-
seatunnel 架构
概览
SeaTunnel 是一个非常易用的支持海量数据实时同步的超高性能分布式数据集成平台,每天可以稳定高效同步数百亿数据,已在近百家公司生产上使用。
SeaTunnel 尽所能为您解决海量数据同步中可能遇到的问题:- 数据丢失与重复
- 任务堆积与延迟
- 吞吐量低
- 应用到生产环境周期长
- 缺少应用运行状态监控
SeaTunnel 使用场景
- 海量数据同步
- 海量数据集成
- 海量数据的 ETL
- 海量数据聚合
- 多源数据处理
SeaTunnel 的特性
- 简单易用,灵活配置,无需开发
- 实时流式处理
- 离线多源数据分析
- 高性能、海量数据处理能力
- 模块化和插件化,易于扩展
- 支持利用 SQL 做数据处理和聚合
- 支持 Spark Structured Streaming
- 支持 Spark 2.x
优势
- 简单易用,灵活配置,无需开发
- 模块化和插件化
- 支持利用SQL做数据处理和聚合
- 由于其高度封装的计算引擎架构,可以很好的与中台进行融合,对外提供分布式计算能力
缺点
- Spark支持2.2.0 - 2.4.8,不支持spark3.x
- Flink支持1.9.0,目前flink已经迭代至1.14.x,无法向上兼容
- Spark作业虽然可以很快配置,但相关人员还需要懂一些参数的调优才能让作业效率更优
配置文件
https://github.com/lightbend/config/blob/main/HOCON.md
版本
1.x
- 支持spark
- 主要开发语言scala
- 主要构建工具sbt
2.x
- 支持spark
- 支持flink
- 开发java
- 主要构建maven
竞品
架构与工作流程
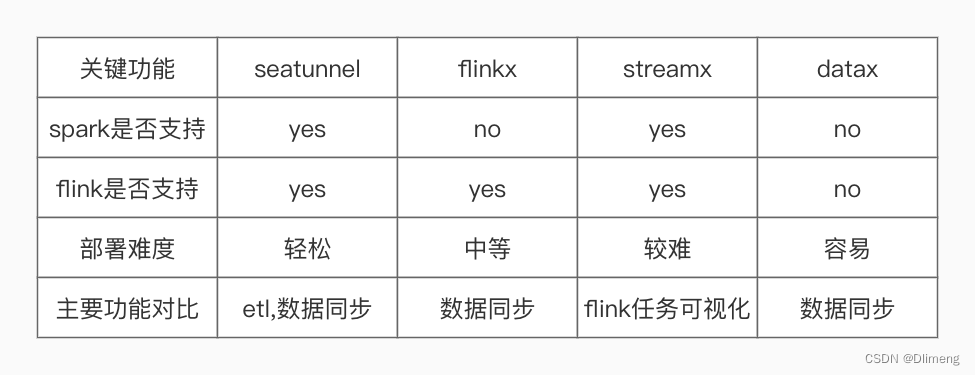
Apache SeaTunnel 发展上有 2 个大版本,1.x 版本基于 Spark 构建,现在在打造的 2.x 既支持 Spark 又支持 Flink。在架构设计上,Apache SeaTunnel 参考了 Presto 的 SPI 化思想,有很好的插件化体系设计。
在技术选型时,Apache SeaTunnel 主要考虑技术成熟度和社区活跃性。Spark、Flink 都是非常优秀并且流行的大数据计算框架,所以 1.x 版本选了 Spark,2.x 版本将架构设计的更具扩展性,用户可以选择 Spark 或 Flink 集群来做 Apache SeaTunnel 的计算层,当然架构扩展性的考虑也是为以后支持更多引擎准备,说不定已经有某个更先进的计算引擎在路上,也说不定 Apache SeaTunnel 社区自己会实现一个为数据同步量身打造的引擎。如下图是 Apache SeaTunnel 的整个工作流程,数据处理流水线由 Source、Sink 以及多个 Transform 构成,以满足多种数据处理需求:
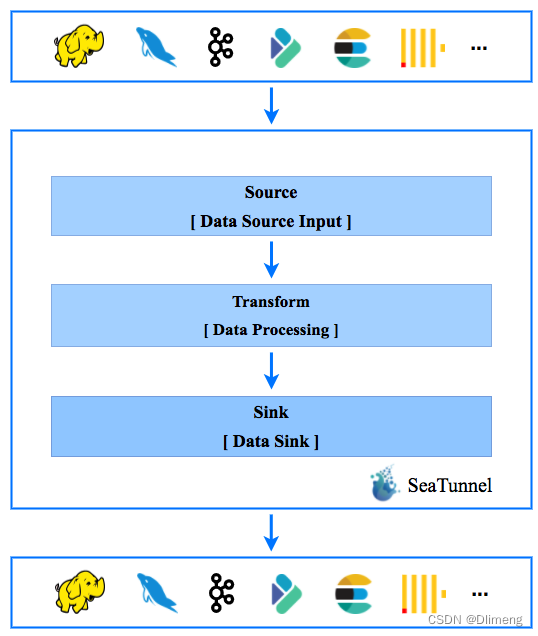
如果用户习惯了 SQL,也可以直接使用 SQL 构建数据处理管道,更加简单高效。目前,SeaTunnel 支持的 Transform 列表也在扩展中。你也可以开发自己的数据处理插件。插件的动态注册使用了java spi技术,保证了框架的灵活扩展,设计思路参考了presto、es等,有兴趣的同学可以下去自行研究,es使用了google guice,presto使用的就是上面提到的java spi。
在以上理论基础上,数据的转换需要做一个统一的抽象与转化,很契合的是spark或者flink都已经为我们做好了这个工作,spark的DataSet,flink的DataSet、DataStream都已经是对接入数据的一个高度抽象,本质上对数据的处理就是对这些数据结构的转换,同时这些数据在接入进来之后可以注册成上下文中的表,基于表就可以使用SQL进行处理
整个Seatunnel通过配置文件生成的是一个spark job或者flink job
程序执行流程
读取配置-》构建插件-》构建执行环境-》检查插件配置-》插件前准备-》组装DAG流程图并执行插件
最上层插件抽象实现细节
public interface Plugin<T> extends Serializable { // 配置文件的key String RESULT_TABLE_NAME = "result_table_name"; String SOURCE_TABLE_NAME = "source_table_name"; // 设置每个插件的config void setConfig(Config config); // 获取插件的配置 Config getConfig(); // 对于config的校验 CheckResult checkConfig(); // 插件前准备 void prepare(T prepareEnv); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Spark插件架构
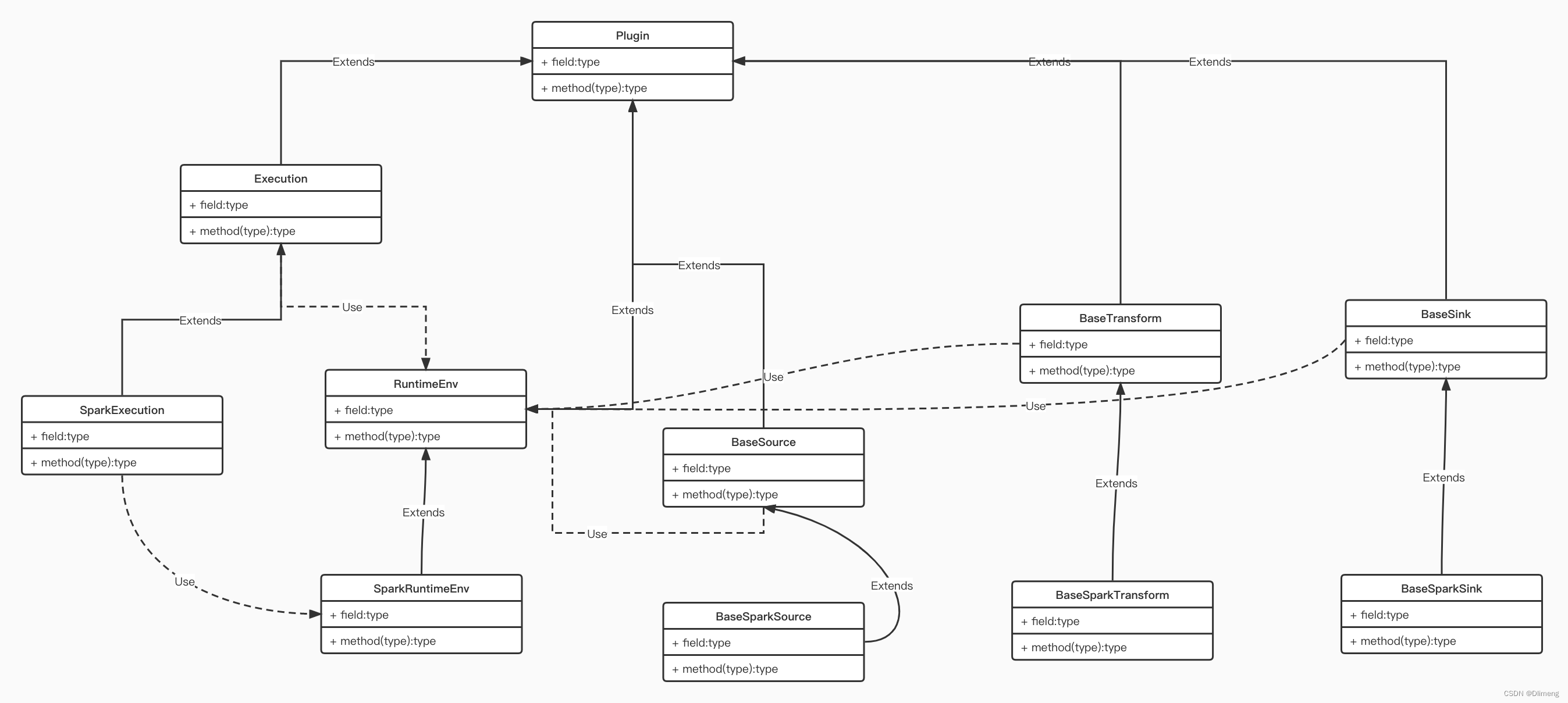
批处理Batch
Source
trait BaseSparkSource[Data] extends BaseSource[SparkEnvironment] { protected var config: Config = ConfigFactory.empty() override def setConfig(config: Config): Unit = this.config = config override def getConfig: Config = config def getData(env: SparkEnvironment): Data; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Transform
trait BaseSparkTransform extends BaseTransform[SparkEnvironment] { protected var config: Config = ConfigFactory.empty() override def setConfig(config: Config): Unit = this.config = config override def getConfig: Config = config def process(data: Dataset[Row], env: SparkEnvironment): Dataset[Row]; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Output
trait BaseSparkSink[OUT] extends BaseSink[SparkEnvironment] { protected var config: Config = ConfigFactory.empty() override def setConfig(config: Config): Unit = this.config = config override def getConfig: Config = config def output(data: Dataset[Row], env: SparkEnvironment): OUT; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
流处理Stream
trait SparkStreamingSource[T] extends BaseSparkSource[DStream[T]] { def beforeOutput(): Unit = {} def afterOutput(): Unit = {} def rdd2dataset(sparkSession: SparkSession, rdd: RDD[T]): Dataset[Row] def start(env: SparkEnvironment, handler: Dataset[Row] => Unit): Unit = { getData(env).foreachRDD(rdd => { val dataset = rdd2dataset(env.getSparkSession, rdd) handler(dataset) }) } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
Flink插件
Batch
Source
public interface FlinkBatchSource<T> extends BaseFlinkSource { DataSet<T> getData(FlinkEnvironment env); }- 1
- 2
- 3
- 4
Transform
public interface FlinkBatchTransform<IN, OUT> extends BaseFlinkTransform { DataSet<OUT> processBatch(FlinkEnvironment env, DataSet<IN> data); }- 1
- 2
- 3
- 4
- 5
Output
public interface FlinkBatchSink<IN, OUT> extends BaseFlinkSink { DataSink<OUT> outputBatch(FlinkEnvironment env, DataSet<IN> inDataSet); }- 1
- 2
- 3
- 4
- 5
流处理Stream
Source
public interface FlinkStreamSource<T> extends BaseFlinkSource { DataStream<T> getData(FlinkEnvironment env); }- 1
- 2
- 3
Transform
public interface FlinkStreamSource<T> extends BaseFlinkSource { DataStream<T> getData(FlinkEnvironment env); }- 1
- 2
- 3
Output
public interface FlinkStreamSink<IN, OUT> extends BaseFlinkSink { DataStreamSink<OUT> outputStream(FlinkEnvironment env, DataStream<IN> dataStream); }- 1
- 2
- 3
自定义插件步骤
针对不同的框架和插件类型继承对应的接口,接口中的核心处理方法
在java spi中注册
将自己定义的jar包放在Seatunnel主jar包的plugins目录下Java spi
概念
SPI全称Service Provider Interface,是Java提供的一套用来被第三方实现或者扩展的接口,它可以用来启用框架扩展和替换组件,SPI的作用就是为这些被扩展的API寻找服务实现
API和SPI的区别
API-(Application Programming Interface)大多数情况下,都是实现方制定接口并完成对接口的实现,调用方仅仅依赖接口调用,且无权选择不同实现。 从使用人员上来说,API 直接被应用开发人员使用,SPI-(Service Provider Interface)是调用方来制定接口规范,提供给外部来实现调用方选择自己需要的外部实现。 从使用人员上来说,SPI 被框架扩展人员使用
实现demo
定义接口
package com.tyrantlucifer; public interface Animal { void shut(); }- 1
- 2
- 3
- 4
定义main函数,使用service loader进行动态加载
package com.tyrantlucifer; import java.util.ServiceLoader; public class Main { public static void main(String[] args) { ServiceLoader<Animal> services = ServiceLoader.load(Animal.class); for (Animal service : services) { service.shut(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
实现接口
package com.tyrantlucifer; public class Cat implements Animal { public void shut() { System.out.println("cat shut miao miao!!!"); } } package com.tyrantlucifer; public class Dog implements Animal{ public void shut() { System.out.println("dog shut wang wang!!!"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
注册spi,需要在resources/META-INF/services下新建以接口全类名的文件,比如我们这次的接口com.tyrantlucifer.Animal,那么就新建一个com.tyrantlucifer.Animal文件,并在文件中添加自己的实现类:
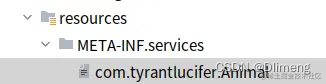
com.tyrantlucifer.Cat
com.tyrantlucifer.DogSeatunnel demo
Spark
park { spark.streaming.batchDuration = 5 spark.app.name = "seatunnel" spark.ui.port = 13000 } input { socketStream {} } filter { split { fields = ["msg", "name"] delimiter = "," } } output { stdout {} }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
Flink
env { execution.parallelism = 1 } source { SocketStream{ result_table_name = "fake" field_name = "info" } } transform { Split{ separator = "#" fields = ["name","age"] } sql { sql = "select * from (select info,split(info) as info_row from fake) t1" } } sink { ConsoleSink {} }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
自定义插件
class MyStdout extends BaseOutput { var config: Config = ConfigFactory.empty() /** * Set Config. * */ override def setConfig(config: Config): Unit = { this.config = config } /** * Get Config. * */ override def getConfig(): Config = { this.config } override def checkConfig(): (Boolean, String) = { if (!config.hasPath("limit") || (config.hasPath("limit") && config.getInt("limit") >= -1)) { (true, "") } else { (false, "please specify [limit] as Number[-1, " + Int.MaxValue + "]") } } override def prepare(spark: SparkSession): Unit = { super.prepare(spark) val defaultConfig = ConfigFactory.parseMap( Map( "limit" -> 100, "format" -> "plain" // plain | json | schema ) ) config = config.withFallback(defaultConfig) } override def process(df: Dataset[Row]): Unit = { val limit = config.getInt("limit") var format = config.getString("format") if (config.hasPath("serializer")) { format = config.getString("serializer") } format match { case "plain" => { if (limit == -1) { df.show(Int.MaxValue, false) } else if (limit > 0) { df.show(limit, false) } } case "json" => { if (limit == -1) { df.toJSON.take(Int.MaxValue).foreach(s => println(s)) } else if (limit > 0) { df.toJSON.take(limit).foreach(s => println(s)) } } case "schema" => { df.printSchema() } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
命令
Spark
bin/start-seatunnel-spark.sh
bin/start-seatunnel-spark.sh
-c config-path
-m master
-e deploy-mode
-i city=beijingYarn client mode
./bin/start-seatunnel-spark.sh
–master yarn
–deploy-mode client
–config ./config/application.confYarn cluster mode
./bin/start-seatunnel-spark.sh
–master yarn
–deploy-mode cluster
–config ./config/application.confFlink
bin/start-seatunnel-flink.sh
-c config-path
-i key=value
-r run-application
[other params]使用-r/–run-mode指定 flink 作业运行模式,可以使用run-applicationor run(默认值)
使用-c/–config指定配置文件的路径
使用-i/–variable来指定配置文件中的变量,可以配置多个bin/start-seatunnel-flink.sh
-c config-path
-i my_name=kid-xiong该名称将"${my_name}"在配置文件中替换为kid-xiong
本节中的所有配置env都将应用于 Flink 动态参数,格式为-D,例如-Dexecution.parallelism=1.
其余参数参考原flink参数。检查 flink 参数方法:bin/flink run -h. 可根据需要添加参数。例如,-m yarn-cluster被指定为on yarn模式。bin/start-seatunnel-flink.sh
-p 2
-c config-path-p 2指定作业并行度是2
bin/start-seatunnel-flink.sh
-m yarn-cluster
-ynm seatunnel
-c config-path-m yarn-cluster -ynm seatunnel指定作业在 上运行yarn,名称yarn WebUI为seatunnel
-
相关阅读:
2022 极术通讯-安谋科技加大自研投入,稳步推进多领域发展
MATLAB算法实战应用案例精讲-【智能优化算法】和声搜索算法-HS(附MATLAB、Java和Python代码)
海外平台运营为什么需要静态住宅IP?
基于SSH框架的学生信息管理系统
【力扣2154】将找到的值乘以 2
极兔快递 | 快递单号查询API
基于VUE + Echarts 实现可视化数据大屏文化大数据
mysql in 禁止排序 按照in内容排序
【电磁】基于 Biot-Savart 定律模拟沿螺旋(螺线管或环形)电流回路的磁场附matlab代码
JavaScript(短信验证码)
- 原文地址:https://blog.csdn.net/qq_19968255/article/details/125905542