-
05 正则表达式语法
一、正则表达式常见语法



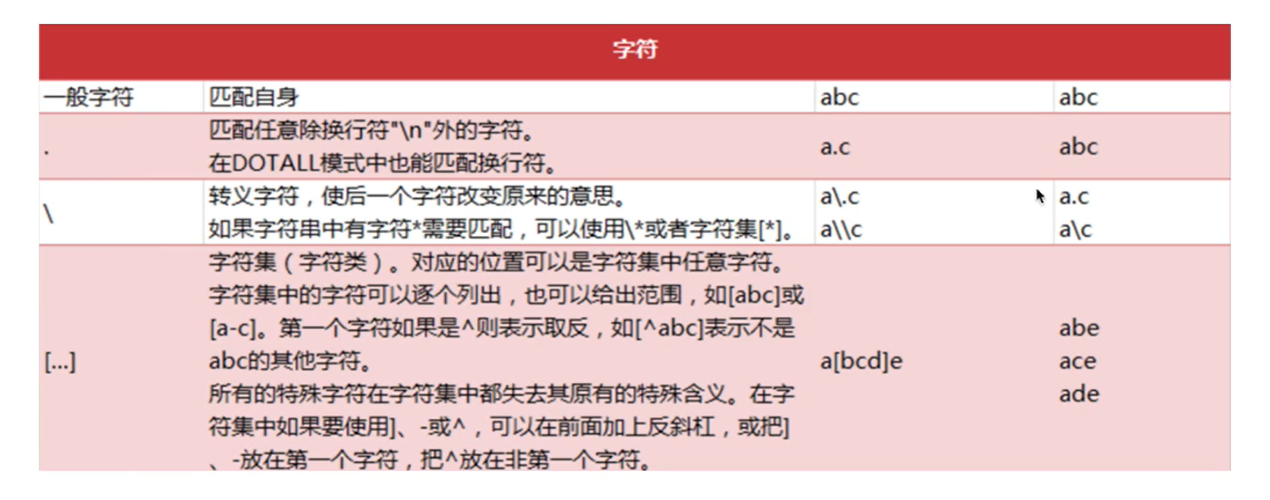
. :是除换行符以外的任意字符 a.c —>可以和abc匹配、acc匹配、a$c匹配
****:是转义符,a.c–>a.c a\c—>a\c
[…]:表示任一个字符只出现一次

\d:是匹配0–9的数字中的一个
\D:是匹配非数字的,只要不是数字都可以
\s:是用来匹配空白符的 a\sc–> a c
\S:是用来匹配非空白符的 a\Sc–>abc
\w:匹配所有的字母(包括大小写)数字和下划线以及中文
\W:只要不是字母(包括大小写)数字和下划线以及中文,其它的都可以匹配
** * *:表示匹配前一个字符出现0次或多次 \d
+:表示匹配前一个字符出现一次或多次(至少要出现1次)
?:表示 匹配前一个字符0次或1次。只能匹配到前面1个
{m}:匹配前一个字符m次
# 1、导入正则模块 import re # 2、字符匹配 # 一、简单字符串匹配 rs = re.findall('abc', 'abc') # 第一个写的是正则表达式,后面是我们要查找的字符串 print(rs) # ['abc'] rs = re.findall('abc', 'abcfeffevfefggh') # 从后面的字符串中查找到我们需要的内容 print(rs) # ['abc'] # 二、使用“.”进行匹配 (.是匹配除换行符以外的任意字符,就是不能匹配换行符) rs = re.findall('a.c', 'abc') print(rs) # ['abc'] rs = re.findall('a.c', 'a%c') print(rs) # ['a%c'] rs = re.findall('a.c', 'a\nc') print(rs) # [] 就是不能匹配换行符 rs = re.findall('a\.c', 'a.c') # 只匹配a.c print(rs) # ['a.c'] rs = re.findall('a\.c', 'abc') # 只匹配a.c print(rs) # [] 只匹配a.c # 三、使用“[]”进行匹配 rs = re.findall('a[bc]d', 'abd') print(rs) # ['abd'] rs = re.findall('a[bc]d', 'acd') print(rs) # ['acd'] rs = re.findall('a[bc]d', 'aed') print(rs) # [] 只能匹配abd、abc # 四、预定义的字符集 rs = re.findall('\d', '123') print(rs) # ['1', '2', '3'] rs = re.findall('\w', '123_中文') print(rs) # ['1', '2', '3', '_', '中', '文'] rs = re.findall('\w', '123_中文$') print(rs) # ['1', '2', '3', '_', '中', '文'] 不匹配$符号 rs = re.findall('\W', '123_中文$') print(rs) # ['$'] # 五、数量词 rs = re.findall('\d*', '123') # 允许有空串 print(rs) # ['123', ''] rs = re.findall('a\d*', 'a123') print(rs) # ['a123'] rs = re.findall('\d+', '123') print(rs) # ['123'] rs = re.findall('a\d?', 'a123') print(rs) # ['a1'] rs = re.findall('a\d{2}', 'a123') print(rs) # ['a12']- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
二、findall()方法


flag是用来对.和\n进行匹配的import re # 1.findall方法,返回匹配的结果列表 rs = re.findall('\d+', 'chuan13zhi24') print(rs) # 2.findall方法中,flag的作用 rs = re.findall('a.bc', 'a\nbc') # .不能和换行符进行匹配 print(rs) # [] # 如果希望.能和换行符进行匹配,我们需要使用flag这个参数。re.DOTALL或者re.S 这样,就可以匹配所有字符 rs = re.findall('a.bc', 'a\nbc', re.DOTALL) print(rs) # ['a\nbc'] rs = re.findall('a.bc', 'a\nbc', re.S) print(rs) # ['a\nbc'] # 3.findall方法中分组的使用,分组就是存在() ''' 关于分组在正则中的使用,如果要是没有分组的话,它就是使用整个正则去字符串里面查找和这个正则匹配的内容,然后进行返回。 但是,如果这个findall方法里正则表达式有分组,即有小括号的话,那么它只会返回与小括号里面这个正则匹配的内容,会进行返回,比如: a(.+)bc,只返回了\n。其它的正则是用来定位的。这里只找a后面的,bc前面的内容,其它的地方我们都不要 ''' # 没有分组,则从整个字符串中进行匹配 rs = re.findall('a.+bc', 'a\nbc', re.S) print(rs) # ['a\nbc'] # 这样是分组(就是出现小括号的),只找a后面的b前面的内容,a和b是用来定位的 rs = re.findall('a(.+)bc', 'a\nbc', re.S) print(rs) # ['a\nbc']- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
三、r原串中的使用

import re '''re的作用: 有几个\就写几个\,这样让我们写正则表达式非常的简单 ''' # 1、在不使用r原串的时候,遇到转义符(\)怎么做 rs=re.findall('a\nbc','a\nbc') print(rs) rs=re.findall('a\\nbc','a\\nbc') print(rs) rs=re.findall('a\\\nbc','a\\nbc') print(rs) rs=re.findall('a\\\\nbc','a\\nbc') print(rs) # ['a\\nbc'] 需要写4个转义符 # r原串在正则中就可以消除转义符带来的影响 rs=re.findall(r'a\\nbc','a\\nbc') print(rs) # ['a\\nbc'] rs=re.findall(r'a\nbc','a\nbc') print(rs) # ['a\nbc'] # 扩展:可以解决写正则的时候,不符合PEP8的规范的问题(没有r也行) rs=re.findall(r'\d','a123') print(rs) # ['1', '2', '3']- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
-
相关阅读:
【2023】COMAP美赛数模中的大型语言模型LLM和生成式人工智能工具的使用
Java回顾-枚举类
MES管理系统如何解决电子企业的生产痛点
MAC地址_MAC地址格式_以太网的MAC帧_基础知识
信息学奥赛一本通:1307:【例1.3】高精度乘法
OS实战笔记(5)-- Cache和内存
ABAP BASE64/STRING/XSTRING/BINARY 等之间的转换总结
BEV(Bird’s-eye-view)三部曲之三:demo和验证
【YOLO系列】YOLO.v1算法原理详解
从0到1搭建ES集群
- 原文地址:https://blog.csdn.net/qq_44636569/article/details/125891032
