-
内存池的实现思路
内存池的目的是避免频繁的申请和释放内存。频繁申请和释放内存会导致内存碎片化,尤其是大量的小块内存的申请和释放。内存池的基本思路是预先分配堆内存,然后接管内存的分配和释放,业务层不断申请和释放内存并不会从系统中频繁分配和释放。
思路一
使用链表组织malloc申请的内存。每个节点保存一个next指针和内存指针,如图:
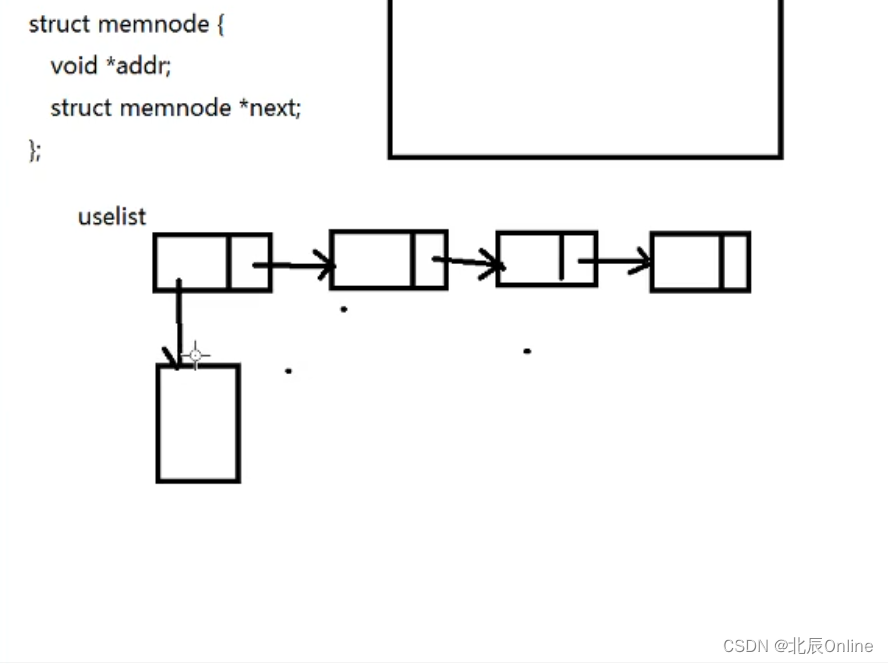 每次malloc就加入节点,每次释放只是给节点一个标志表示释放。节点结构体如下:
每次malloc就加入节点,每次释放只是给节点一个标志表示释放。节点结构体如下:struct memnode { void *addr; int size; int flag; // 1 used, 0 free struct memnode *next; }- 1
- 2
- 3
- 4
- 5
- 6
每次分配内存先去内存池中查找flag == 0并且有内存块的节点返回而不去系统中去申请。
以上思路是内存池的最基本的实现思路。但是这个思路存在一个问题:- 需要的内存不合适则再申请内存,会造成内存越分越小。
解决方法:
节点大小固定方案来解决上面越分越小的问题。但是会造成内存浪费。然后采用分配不同阶梯大小的单元,比如以16个字节为单位: 16, 32, 64, 128, 256, 512, 1024, 2048这种梯度来分配节点大小。比如分配14个字节,这分配16个字节,依次找第一个比需要分配大小的阶梯。这种方案你能解决内存越分越小且避免一定的浪费。如果分配的大小大于最大阶梯的,则直接使用系统申请和释放。此种就引出了大块和小块的内存概念,大块的内存很好处理,不会造成内存碎片化,一般需要处理的是小内存。
思路二
先建立一个哈希表,保存每个阶梯大小。每次分配内存,先查找哈希表及下的内存链表是否有空闲内存,没有这重新分配并加到链表下。释放的时候根据地址去遍历链表找到具体的节点。思路如下图:
 内存之间不连续问题需要根据使用场景来判断,比如内存池是使用在一个连接生命周期内,内存池本身都是有生命周期的情况就不需要做小块内存合并处理。当使用全局内存池就需要处理这种问题。
内存之间不连续问题需要根据使用场景来判断,比如内存池是使用在一个连接生命周期内,内存池本身都是有生命周期的情况就不需要做小块内存合并处理。当使用全局内存池就需要处理这种问题。
小块内存不连续: 可以预先分配大块内存,然后每次分配都从4K中获取一部分,比如4K,如果4K中所有都不用,则回收。
对于全局内存池,需要回收小块内存,则是一个很麻烦的事情,这种情况下建议使用开源成熟的框架。
开源的有jemalloc/tcmalloc
内存池: 要用,不要自己造,原理一定要懂。实现参考代码: https://download.csdn.net/download/beichen_yx/86245885
-
相关阅读:
AI智能机器人的语音识别是如何实现的 ?
docker基础命令(包括安装、卸载、打包等)
组合数的和
windows11恢复ie浏览器的方法教程
【Linux】Linux常用命令—文件管理(上)
Django DRF API(GET/POST/PUT)序列化和反序列化(一对多,多对多)demo-模型类序列化器ModelSerializer
CRS 管理与维护
2022/8/15 考试总结
kafka开发环境搭建
人力外包有什么优势
- 原文地址:https://blog.csdn.net/beichen_yx/article/details/125882568