-
激活函数介绍
前言
激活函数是向神经网络中引入非线性因素,通过激活函数神经网络就可以拟合各种曲线(提供网络的非线性建模能力,如果没有激活函数,那么该网络仅能够表达线性映射)。激活函数主要分为饱和激活函数(Saturated Neurons)和非饱和函数(One-sided Saturations)。Sigmoid和Tanh是饱和激活函数,而ReLU以及其变种为非饱和激活函数。非饱和激活函数主要有如下优势: 1、非饱和激活函数可以解决梯度消失问题。 2、非饱和激活函数可以加速收敛。
一、饱和激活函数
1-1、Sigmoid函数
公式:
f ( x ) = 1 1 + e x p ( − x ) f(x) = \frac{1}{1+exp(-x)} f(x)=1+exp(−x)1
代码实现:import plotly.express as px import numpy as np # 语法: # 格式: array = numpy.linspace(start, end, num=num_points)将在start和end之间生成一个统一的序列,共有num_points个元素。 # start -> Starting point (included) of the rangestart ->范围的起点(包括) # end -> Endpoint (included) of the rangeend ->范围的端点(包括) # num -> Total number of points in the sequencenum >序列中的总点数 # np.linspace用于在线性空间中以均匀步长生成数字序列,默认生成浮点数序列。 x=np.linspace(-10,10) fig = px.line(x=x, y=1/(1+np.exp(-x))) fig.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
函数曲线:

本质:可以将一个实数映射到(0,1)的区间,可以用来做二分类。缺点:
1、激活函数计算量大。
2、反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。1-2、Tanh函数
公式:
f ( x ) = e x − e − x e x + e − x f(x) = \frac{e^x-e^{-x}}{e^x+e^{-x}} f(x)=ex+e−xex−e−x
代码实现:import plotly.express as px import numpy as np x=np.linspace(-10,10) fig = px.line(x=x, y=(np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x))) fig.show()- 1
- 2
- 3
- 4
- 5
函数曲线:

本质:tanh的使用优先是高于Sigmoid函数的。
缺点:
1、与sigmoid类似,也存在梯度消失的问题,在饱和时会杀死梯度。
2、当输入较大或较小时,输出几乎是平滑的并且梯度较小,这不利于权重更新。二、非饱和激活函数
2-1、ReLU函数
公式:
f ( x ) = m a x ( 0 , x ) f(x) = max(0, x) f(x)=max(0,x)
代码实现:import plotly.express as px import numpy as np x=np.linspace(-10,10) fig = px.line(x=x, y=np.array([0*item if item<0 else item for item in x ])) fig.show()- 1
- 2
- 3
- 4
- 5
函数曲线:
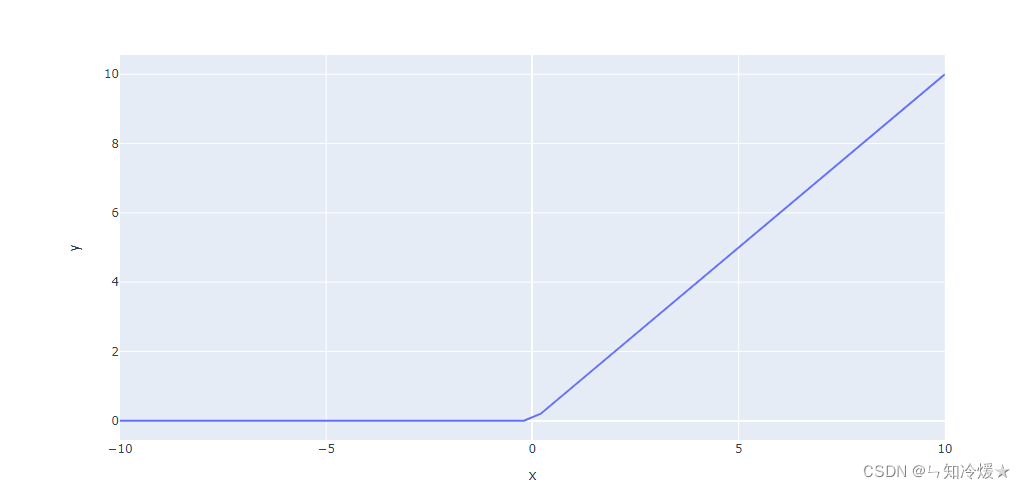
优点:相比于饱和激活函数,收敛速度会快很多,计算速度会快得多。
缺点:有时可能会忽略掉许多神经元,这是因为在输入为负的时候,Relu完全失效。
选择建议:在使用Relu的过程中,要小心设置学习率,否则会出现多个被忽略掉的神经元,如果无法避免,建议使用Leaky Relu激活函数。2-2、Leaky Relu函数
公式:
x > 0 : f ( x ) = x x>0: f(x) = x x>0:f(x)=x
x < 0 : f ( x ) = 0.2 ∗ x x<0: f(x) = 0.2*x x<0:f(x)=0.2∗x
代码实现:import plotly.express as px import numpy as np x=np.linspace(-10,10) fig = px.line(x=x, y=np.array([0.2*item if item<0 else item for item in x ])) fig.show()- 1
- 2
- 3
- 4
- 5
函数曲线:
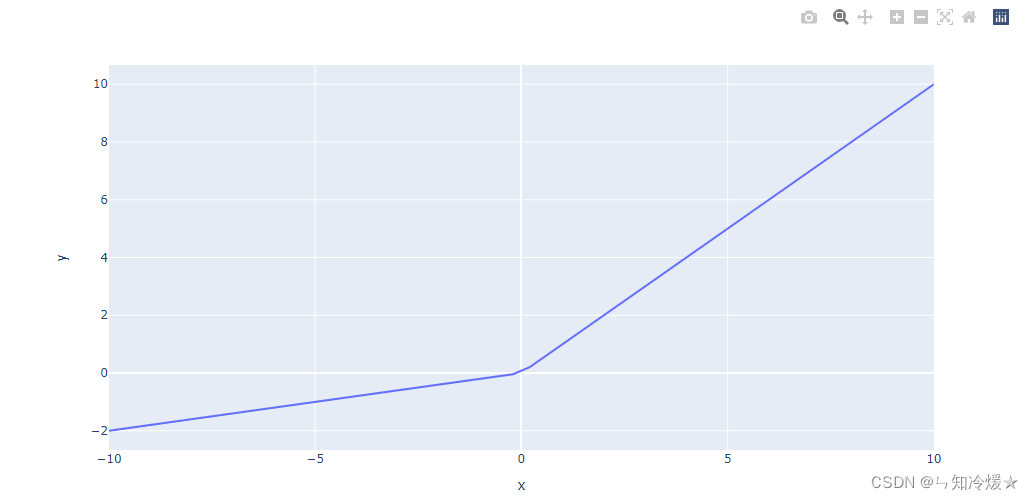
优点:在一定程度上缓解了Relu的缺点。2-3、ELU函数
公式:
x > 0 : f ( x ) = x x>0: f(x) = x x>0:f(x)=x
x < 0 : f ( x ) = α ( e x − 1 ) x<0: f(x) = α(e^x-1) x<0:f(x)=α(ex−1)
代码实现:import plotly.express as px import numpy as np x=np.linspace(-10,10) fig = px.line(x=x, y=np.array([2.0*(np.exp(item)-1) if item<0 else item for item in x ])) fig.show()- 1
- 2
- 3
- 4
- 5
函数曲线:
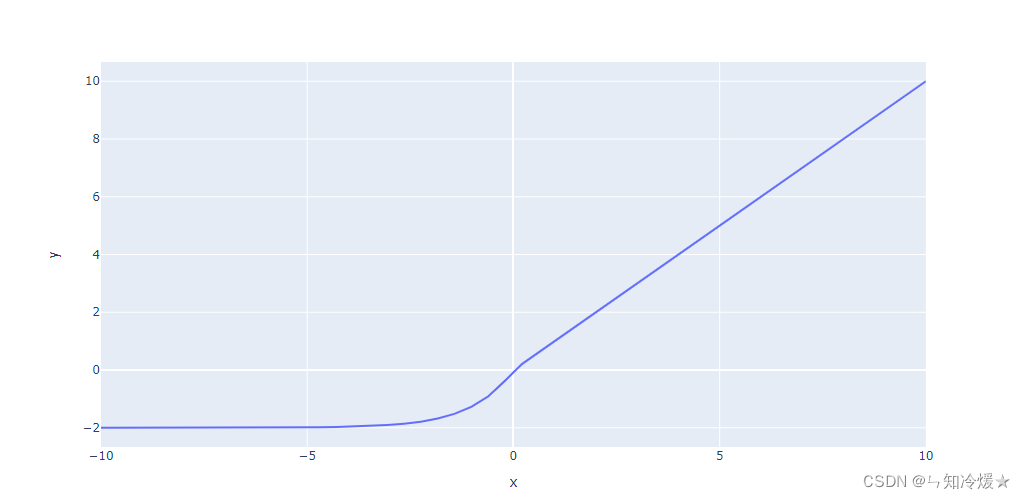
优点:融合了sigmoid和ReLU,左侧具有软饱和性,右侧无饱和性。右侧线性部分使得ELU能够缓解梯度消失,而左侧软饱能够让ELU对输入变化或噪声更鲁棒。ELU的输出均值接近于零,所以收敛速度更快。
缺点:计算强度高,计算量较大。参考文章:
详解激活函数(Sigmoid/Tanh/ReLU/Leaky ReLu等).
花书电子版.
机器学习(九):激活函数.
深度学习笔记:如何理解激活函数?(附常用激活函数).
激活函数 | 深度学习领域最常用的10个激活函数,详解数学原理及优缺点.
总结
-
相关阅读:
(十二)Flask重点之session
学习笔记 Golang 写入文件(io.WriteString、ioutil.WriteFile、file.Write、write.WriteString)
shell编程3-shell选择结构和循环语句
【python】点燃我,温暖你 ,快来Get同款~
java计算机毕业设计汽车售后服务信息管理系统的设计与实现源程序+mysql+系统+lw文档+远程调试
微服务架构 Sentinel 的服务限流及熔断
EXCEL——计算数据分散程度的相关函数
全网最全Docker常用命令合集
Magisk V26.3卡刷包APK最新版下载-支持payload.bin自动维补ROOT
免疫浸润计算方法是CIBERSORT和ssgsea 画图
- 原文地址:https://blog.csdn.net/weixin_42475060/article/details/125877405