-
Elasticsearch是如何通过倒排索引来查询数据的
简介
传统的我们的检索是通过文章,逐个遍历找到对应关键词的位置.
而倒排索引,是通过分词策略,形成了词和文章的映射关系表,这种词典+映射表即为倒排索引(Inverted Index).
有倒排索引就有正排索引.通俗的来讲,正排索引是通过key来找value,反向索引是通过value来找key
有了倒排索引,就能实现O (1) 时间复杂度的效率检索,极大的提高了检索效率批量添加一些数据
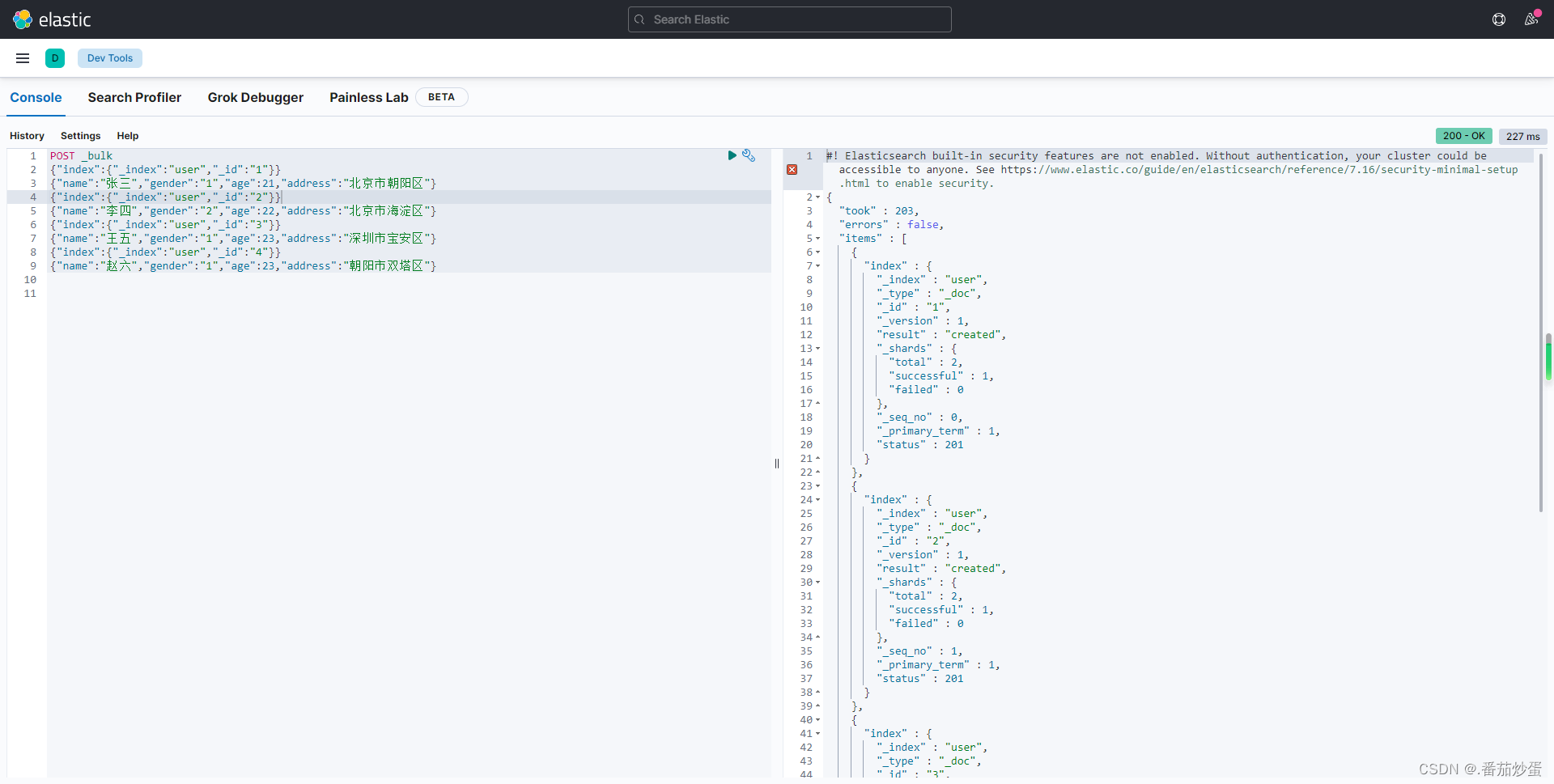
POST _bulk {"index":{"_index":"user","_id":"1"}} {"name":"张三","gender":"1","age":21,"address":"北京市朝阳区"} {"index":{"_index":"user","_id":"2"}} {"name":"李四","gender":"2","age":22,"address":"北京市海淀区"} {"index":{"_index":"user","_id":"3"}} {"name":"王五","gender":"1","age":23,"address":"深圳市宝安区"} {"index":{"_index":"user","_id":"4"}} {"name":"赵六","gender":"1","age":23,"address":"朝阳市双塔区"}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
es再储存这些数据时,就使用到了倒排索引,主要是基于分词的策略来生成倒排索引
以address字段为例:- 首先要对字段内容进行分词,分词就是将一段连续的文本按照语义拆分为多个单词(Term)
- 然后按照单词来作为索引,对应的文档(Document) id建立一个链表,就能构成倒排索引结构
Term Document id 北京市 [1,2] 深圳市 3 朝阳市 4 朝阳 [1,4] 朝阳区 1 海淀区 2 宝安区 3 双塔区 4 倒排索引的另一部分为倒排列表(Postings List), 倒排列表由所有的Term对应的数据(Postings)组成,它不仅仅只有文档id信息;包含但不限于以下信息:
- 文档(Document)id:包含单词的所有文档的唯一id,用于去正排索引中查询原始数据
- 词频: 记录Term出现的次数,用于后续查询得分(_score)
- 位置: 记录Term再每个文档中的分词位置
- 偏移量:记录Tern再每个文档中的开始和结束的位置
当我们进行检索时,就会到倒排列表中查询我们传过来的单词到倒排列表中去获取文档id,然后将整条数据返回给我们

倒排索引的底层实现是基于:FST(Finite State Transducer)数据结构.FST 有两个优点:- 空间占用小.通过对词典中单词前缀和后缀的重复利用,压缩了存储空间.
- 查询速度快.O(len(str))的查询时间复杂度.
-
相关阅读:
Resnet的在指静脉识别应用与改进
多版本CUDA安装切换
【python】(四)python常用数据结构
中国开源软件推进联盟主席陆首群:开源创新,数字化转型与智能化重构
【红外双目有监督】CATS系列数据集探索&加载器
【验证用户输入的日期格式是否正确——工具类SimpleDateFormat类的使用】
Postman之页面简介 V9.31.0
6.2:荷兰国旗问题
Python【数据分析第二阶段测试】
三维模型3DTile格式轻量化在三维展示效果上的重要性分析
- 原文地址:https://blog.csdn.net/qq_43135259/article/details/125630323