人工智能
第十三章 推荐系统
一、推荐系统的背景与价值
1. 推荐系统的应用场景1 – 网易云音乐
- 个性化推荐:在面向用户的互联网产品中发挥着极其重要的作用。
- Youtube 主页:60%+的视频点击率;
- Netflix 观影站点:80%+的观看记录,每年10亿+盈利。
2. 推荐系统的应用场景2 – 电商推荐
二、推荐系统的本质
- 推荐问题本质 – “猜你喜欢”
- 在面向用户的互联网产品中,代替用户评估其从未看过、接触过和使用过的物品,包括电影、新闻、音乐、参观、旅游景点等。推荐系统作为一种信息过滤的重要手段,是解决“信息过载”问题的最有效的方法之一。
- 对于用户来说:帮助用户准确找到感兴趣的信息;
- 具体表现:在有限的时间内,给用户曝光他潜意识里想看的、想买的物品…
- 对于商家来说:帮助商家带来更多的用户关注、销量;
三、推荐系统的原理
1. 推荐系统
- 可以简单地被抽象成一个m x n 的矩阵R,行和列分别表示:用户、物品,m和n分别表示用户和物品数量。矩阵中的每一项代表:一个用户对一个物品的评分,“?”表示这个用户和这个物品之间没有交互(待预测)。
2. 目标
- 预测矩阵中所有未知项的评分,然后给用户推荐评分较高的未交互物品。

四、推荐算法的算法栈

- 在工业界算法不是最重要的,关键是怎么将算法跟产品形态很好的结合起来,快速上线,整个业务要形成闭环,具备迭代优化的能力。
- 基于协同过滤的推荐
- 基于用户的协同过滤推荐(User-Based CF):其本质就是计算用户之间的相似度,然后获取与目标用户相似度较高的用户,并将其交互物品中评分较高的推荐给目标用户。
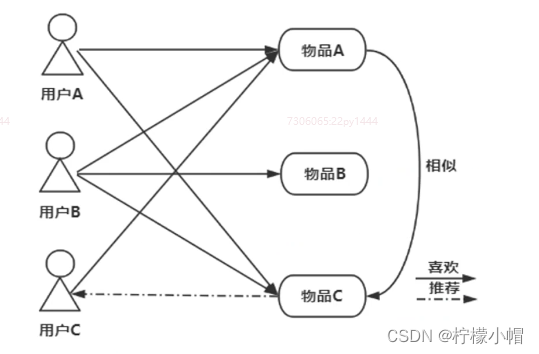
- 基于物品的协同过滤推荐(Item-Based CF):其本质就是计算物品之间的相似度,然后获取与目标用户交互物品相似度较高的物品,并将其推荐给目标用户。
1. 典型算法1:基于用户的协同过滤推荐



2. 典型算法2:基于物品的协同过滤推荐


五、推荐系统的发展趋势
- 移动环境下 推荐系统成为主流
- 近乎实时的个性化推荐服务
- 可解释的推荐系统
- 完整的推荐系统引擎 + 推荐系统作为云服务方式提供
第十四章 电影推荐引擎
import numpy as np
import pandas as pd
ratings = pd.read_json('ratings.json')
ratings

simmat = ratings.corr()
simmat

login_user = 'Michael Henry'
sim_users = simmat[login_user]
sim_users = sim_users.drop(login_user)
sim_users = sim_users[sim_users>0]
movie_list = {}
for sim_user, sim_score in sim_users.items():
movies = ratings[sim_user]
for movie, score in movies.dropna().items():
if np.isnan(ratings[login_user][movie]):
if movie not in movie_list.keys():
movie_list[movie] = [[], []]
movie_list[movie][0].append(score)
movie_list[movie][1].append(sim_score)
print(movie_list)
ml = sorted(movie_list.items(), key=lambda x:np.average(x[1][0], weights=x[1][1]), reverse=True)
print(np.array(ml)[:,0])
"""
{'Inception': [[2.5, 3.0, 3, 3.0], [0.9912407071619304, 0.3812464258315117, 0.924473451641905, 0.6628489803598702]],
'Anger Management': [[3.0, 1.5, 3.0, 2], [0.9912407071619304, 0.3812464258315117, 0.8934051474415644, 0.924473451641905]],
'Jerry Maguire': [[3.0, 3.0, 4.5, 3, 3.0], [0.9912407071619304, 0.3812464258315117, 0.8934051474415644, 0.924473451641905, 0.6628489803598702]]}
['Jerry Maguire' 'Inception' 'Anger Management']
"""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32