-
3.MNIST数据集分类
MNIST数据集及Softmax
MNIST数据集
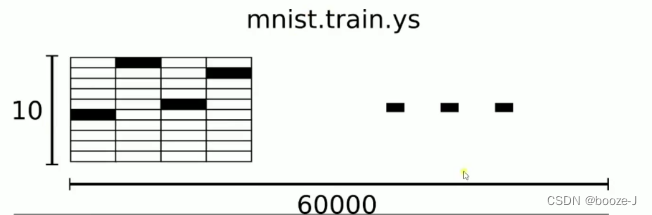
大多数示例使用手写数字的MNIST数据集。该数据集包含60,000个用于训练的示例和10,000个用于测试的示例。

每一张图片包含28*28个像素,在MNIST训练数据集中是一个形状为[60000,28,28]的张量,我们首先需要把数据集转成[60000,784],然后才能放到网络中训练。第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点。一般我们还需要把图片中的数据归一化0~1之间。

MNIST数据集的标签是介于0-9的数字,我们要把标签转化为"one-hotvectors"。一个one-hot向量除了一位数字是1外,其余维度数字都是0,比如标签0将表示为([1,0,0,0,0,0,0,0,0,0]),标签3将表示为([0,0,0,1,0,0,0,0,0,0])。
因此,MNIST数据集的标签是一个[60000,10]的数字矩阵。
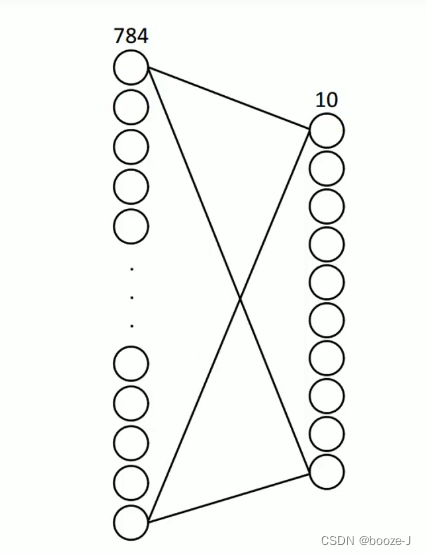
28*28=784,每张图片有784个像素点,对应着784个神经元。最后输出10个神经元对应着10个数字。
Softmax
Softmax作用就是把神经网络的输出转化为概率值。
我们知道MNIST的结果是0-9,我们模型可能推测出一张图片的数字9的概率是80%,是数字8的概率是10%,然后其他数字的概率更小,总体概率加起来等于1。这是一个使用softmax回归模型的经典案例。softmax模型可以用来给不同的对象分配概率。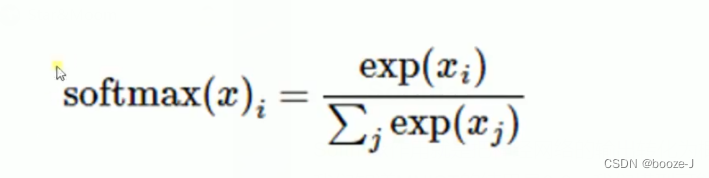
![比如输出有3个输出,输出结果为[1,5,3]](https://1000bd.com/contentImg/2022/07/05/232157554.png)
MNIST数据集分类
代码运行平台为jupyter-notebook,文章中的代码块,也是按照jupyter-notebook中的划分顺序进行书写的,运行文章代码,直接分单元粘入到jupyter-notebook即可。
1.导入第三方库
import numpy as np from keras.datasets import mnist from keras.utils import np_utils from keras.models import Sequential from keras.layers import Dense from tensorflow.keras.optimizers import SGD- 1
- 2
- 3
- 4
- 5
- 6
2.加载数据及数据预处理
# 载入数据 (x_train,y_train),(x_test,y_test) = mnist.load_data() # (60000, 28, 28) print("x_shape:\n",x_train.shape) # (60000,) 还未进行one-hot编码 需要后面自己操作 print("y_shape:\n",y_train.shape) # (60000, 28, 28) -> (60000,784) reshape()中参数填入-1的话可以自动计算出参数结果 除以255.0是为了归一化 x_train = x_train.reshape(x_train.shape[0],-1)/255.0 x_test = x_test.reshape(x_test.shape[0],-1)/255.0 # 换one hot格式 y_train = np_utils.to_categorical(y_train,num_classes=10) y_test = np_utils.to_categorical(y_test,num_classes=10)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3.训练模型
# 创建模型 输入784个神经元,输出10个神经元 model = Sequential([ # 定义输出是10 输入是784,设置偏置为1,添加softmax激活函数 Dense(units=10,input_dim=784,bias_initializer='one',activation="softmax"), ]) # 定义优化器 sgd = SGD(lr=0.2) # 定义优化器,loss_function,训练过程中计算准确率 model.compile( optimizer=sgd, loss="mse", metrics=['accuracy'] ) # 训练模型 model.fit(x_train,y_train,batch_size=32,epochs=10) # 评估模型 loss,accuracy = model.evaluate(x_test,y_test) print("\ntest loss",loss) print("accuracy:",accuracy)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
最终运行结果:
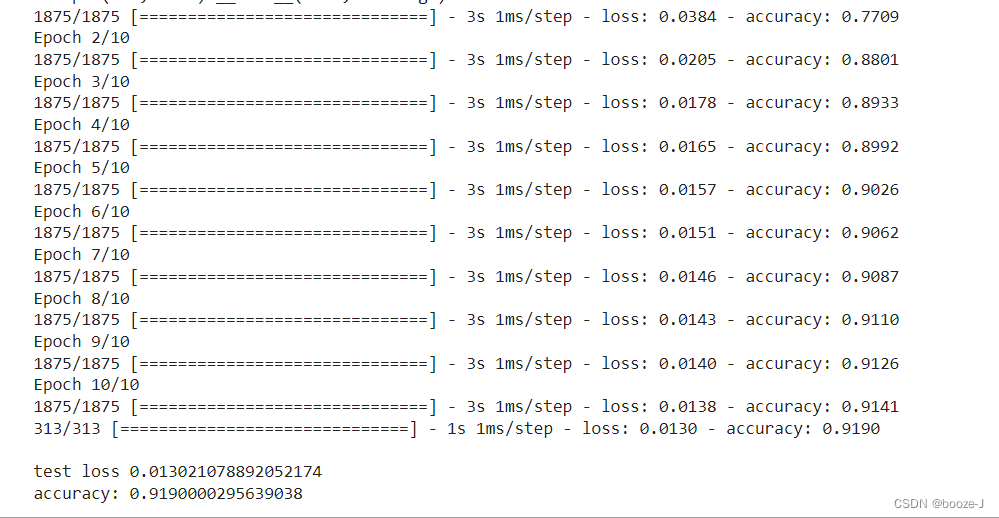
注意Dense(units=10,input_dim=784,bias_initializer='one',activation="softmax")这里用到了softmax激活函数。- 这里我们使用的
fit方法进行的模型训练,之前的线性回归和非线性回归的模型训练方式和这不同。
代码:
model.compile( optimizer=sgd, loss="mse", metrics=['accuracy'] )- 1
- 2
- 3
- 4
- 5
中添加
metrics=['accuracy'],可以在训练过程中计算准确率。 -
相关阅读:
YOLOv8改进 | 卷积模块 | 用DWConv卷积替换Conv【轻量化网络】
机器学习基础之《回归与聚类算法(4)—逻辑回归与二分类(分类算法)》
Tomcat配置SSL证书
SparkStreaming 案例实操 完整使用 (第十七章)
IDEA中SpringBoot的启动类文件变成了一个J文件的解决方案
指定顺序输出
开源软件的漏洞响应:应对安全威胁
在window10脱离hadoop独立安装hbase-2.5.6
call()、apply()、bind() 区别、使用场景、实现方式
tomcat启动后,执行一个方法作为监听
- 原文地址:https://blog.csdn.net/booze_/article/details/125621175