-
基于开放基准下的点击率预估模型研究 · 详解
摘要 · 基于开放基准下的点击率预估模型
1、业界由于缺乏用于CTR预测研究的标准化基准和统一的评估协议。这导致现有研究中的实验结果不可重复,甚至不一致,这在很大程度上限制了其研究的实际价值和潜在影响。
2、作者的目标是对CTR预测进行开放基准测试,并以可复制的方式对不同模型进行严格比较。
3、实验结果表明,通过充分的超参数搜索和模型调整,许多dnn模型的差异比预期的要小。作者已经公开发布了基准测试代码

添加VX:julyedufu77 回复 "0704" 观看公开课视频 + 领取完整课件PDF 或联系七月任一老师 介绍 · 点击率预估模型复现的痛点
1、现有研究通常执行自己的数据分区(例如,使用未知的测试集分割或使用未知的随机种子)和预处理步骤(处理数字特征和过滤稀疏的分类特征阈值)
2、一些主流模型的官方或第三方源代码(例如,DeepCTR)通常缺少关于超参数设置、数据加载和提前停止的培训细节
3、由于发表的文献中缺乏可重用和可比较的基准测试结果,研究人员在发表新论文时需要重新实现所有基线模型,并在自己的数据分区上重新评估它们。这是一项繁琐而重复的工作,极大地增加了研究人员开发新模型的负担

添加VX:julyedufu77 回复 "0704" 观看公开课视频 + 领取完整课件PDF 或联系七月任一老师 核心· 文章的三个核心贡献
1、该论文的工作是迈向CTR预测开放基准的第一步
2、作者在网站上发布了所有基准代码、评估协议和实验结果,以促进CTR预测的可复制研究。
3、作者的工作揭示了现有研究中的不可再现性和不一致性问题,并呼吁在未来的CTR预测研究中进行开放和严格的评估。
优化 · 点击率预估模型的三个重点优化方向
▋特征工程:
1、CTR预测的目标是预测用户单击给定项目的概率。与图像和文本等其他数据类型相比,CTR预测问题中的数据通常采用表格格式,包括多个不同字段的数字、类别或多值(或序列)特征。样本量通常很大,但特征空间非常稀疏。例如,Google Play[8]中的应用程序推荐涉及数十亿个样本和数百万个特征。
2、特征embedding。CTR预测的输入实例通常包含三组特征,即用户特征集合、item特征集合和上下文特征集合
▋特征交叉学习:
1、在因子分解机(FM)中,内积显示为捕获成对特征交互的简单而有效的方法。自FM成功以来,大量研究致力于以不同方式捕捉特征之间的交互。
典型示例包括PNN中的特征内积和外积层、NFM中的双向特征交互、DCN中的特征交叉网络、xDeepFM中的特征压缩交互、FGCNN中的特征卷积、HFM中的循环卷积、FiBiNET中的双线性交互、AutoInt中的自注意机制、FiGNN中的图形神经网络、InterHAt中的层次注意,目前大多数工作都研究了如何将显式和隐式特征交互与普通全连接网络(即MLP)结合起来。
▋模型表征:
1、浅层模型:工业CTR预测任务通常具有大规模数据。因此,浅层模型因其简单高效而得到广泛应用。即使在今天,LR和FM仍然是业界部署的两个强大的基线模型,包括LR,FM,FFM,HOFM,FwFM,LorentzFM
2、深层模型: 目前,深度神经网络已被广泛研究并应用于CTR预测。与浅层模型相比,deep模型在捕捉复杂的具有非线性激活函数的高阶特征交互方面更强大,通常会产生更好的性能。然而,效率已成为实际应用中深层模型的主要瓶颈,具体包括:DNN,CCPM,wide & deep,IPNN,DeepCross,NFM,AFM,DeepFM,DCN,xDeepFM,HFM+,FGCNN,AutoInt+,FiGNN,ONN,FiBiNET,AFN+,InterHAt。

添加VX:julyedufu77 回复 "0704" 观看公开课视频 + 领取完整课件PDF 或联系七月任一老师 重要 · 复现论文中点击率预估模型的几点要求
1、数据预处理的参数
2、模型源代码
3、模型超参数
4、基线模型原代码
5、基线模型超参数
重要 · 模型评估协议
1、数据集:主要使用两个真实世界的数据集进行评估:Criteo和Avazu。它们都是由两家领先的广告公司发布的开放数据集,在之前的工作中得到了广泛应用,是从生产过程中的真实点击日志中收集或采样的,而且两者都有数千万个样本,这使得基准测试结果对行业从业者来说很有意义。
2、Data split:作者将Criteo和Avazu随机分成8:1:1,分别作为训练集、验证集和测试集。为了使其完全可复制并易于与现有工作进行比较,作者重用了AutoInt提供的代码,并控制随机种子(即种子=2018)进行分割。
3、数据预处理:Criteo数据集由一周内的广告点击数据组成。它包括26个分类特征字段和13个数字特征字段。作者创建两个不同的评估设置,分别表示为Criteox4001和Criteox4002。分别过滤稀疏特征的阈值设置为mincount=10和mincount=2。特征embedding的维度分别为16和40;Avazu包含10天的点击日志。它总共有23个字段,包括应用程序id、应用程序类别、设备id等,与第一个数据集一样,也是两个不同的特征过滤参数和特征embedding的维度。
4、评估指标:作者使用两个最常用的指标AUC和logloss进行基准测试。
5、基准测试工具包:作者提供了包括数据预处理、批量加载、模型训练、早期停止、学习率衰减、超参数搜索在内的全流程基准测试工具包。
6、模型训练细节和超参数调节:默认学习速率为1��� − 3、batchsize最初设置为10000,如果GPU中出现OOM错误,则使用[5000、2000、1000]逐渐减小。作者对每个模型进行73次实验,以获得最佳结果。所有实验都是在一个共享GPU集群上运行的,该集群有P100个GPU,每个GPU都有16GB的内存。
7、再现性:作者保留了每个数据分割的md5sum值。并为每个实验明确设置随机种子,并将数据设置和模型超参数记录到配置文件中。在Pytorch中实现模型,作者向社区开放了基准代码以及所有评估设置和结果,以促进未来更具可复制性的研究。
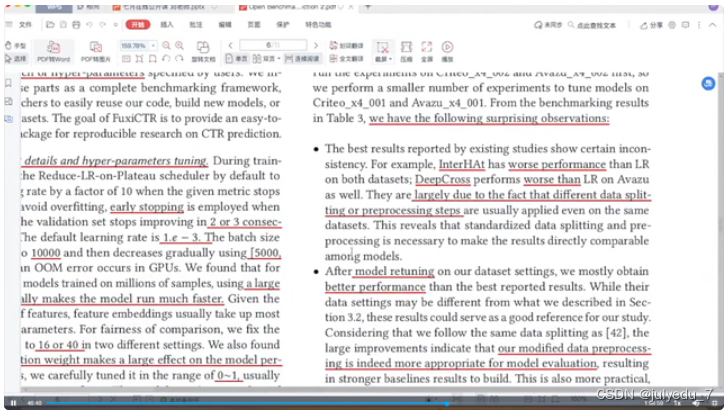
添加VX:julyedufu77 回复 "0704" 观看公开课视频 + 领取完整课件PDF 或联系七月任一老师 重要 · 结果分析
1、InterHAt在两个数据集上的性能都比LR差;DeepCross在Avazu的表现也比LR差
2、在数据集参数设置上进行重新调整模型后,作者通常会获得比最佳报告结果更好的性能
3、IPNN、DeepFM、DCN、xDeepFM和ONN都可以达到相同的精度级别(∼0.814 AUC),而DNN、DeepFM、DCN和xDeepFM在Avazu上的性能相当,InterHAt、AFN+和LorentzFM,获得的结果比以前的一些最新模型更差
4、内存消耗和模型效率是工业CTR预测任务的两个重要方面。由于使用卷积网络(如CCPM、FGCNN、HFM+)、field交互(如FFM、ONN)、图形神经网络(如FiGNN)等运行速度非常慢,阻碍了模型在工业中的实际应用
5、模型和数据参数经过重新调整后,作者在原始超参数的基础上实现了相当大的改进(高达5%)。在新的数据拆分上测试模型时(即使对于相同的数据集),有必要重新调整超参数。
重要 · 模型优化的关键因素
1、数据预处理:数据通常决定模型的上限。然而,现有工作很少在数据预处理期间调整类别特征的最小计数阈值。作者为不频繁的特征过滤设置了一个合适的阈值,产生了更好的性能。
2、Batchsize :大的batchsize通常会导致更快的培训和更好的性能。例如,如果GPU没有引发OOM错误,作者将其设置为10000
3、Embedding size:虽然现有的工作通常在实验中将其设置为10或16,但作者也通过在GPU内存限制内使用更大的嵌入大小(例如40)来实验
4、调整权重和dropout值。正则化和dropout是减少模型过拟合的两个关键参数。它们对CTR预测模型的性能有很大影响。作者在一个范围内进行了穷尽地搜索最优值
5、Batch normalization:在某些情况下,在DNN模型的隐藏层之间添加Batch normalization可以进一步提高预测性能
探索 · 点击率预估模型在开放基准下进行进一步探索的潜在方向
1、使用更多的数据集
2、数据切分方式的优化
3、模型的在线预估时效性
4、自动调整超参数

添加VX:julyedufu77 回复 "0704" 观看公开课视频 + 领取完整课件PDF 或联系七月任一老师 方向 · 发展的几个方向
1、特征交互学习
2、行为序列建模
3、多任务学习
4、多模态学习

添加VX:julyedufu77 回复 "0704" 观看公开课视频 + 领取完整课件PDF 或联系七月任一老师 总结 · 论文总结
在本文中,作者提出了第一个CTR预测的开放基准。目标在于缓解当前研究中提出的不可重复和不一致结果的问题。作者对评估协议进行了标准化,并通过在两个广泛使用的真实数据集上运行7000多个实验,持续12000多个GPU小时,评估了24个现有模型。
作者提供了最全面的基准测试结果,以严格的方式比较现有模型。结果表明,许多模型之间的差异小于预期,现有文献中存在不一致的结果。作者的基准测试不仅会推动更多的可重复性研究,还可以帮助新手学习最先进的CTR预测模型。
进大厂是大部分程序员的梦想,而进大厂的门槛也是比较高的。刷题,也成为面试前的必备环节。
七妹给大家准备了“武功秘籍”,七月在线干货组继19年出的两本书《名企AI面试100题》和《名企AI面试100篇》后,又整理出《机器学习十大算法系列》、《2021年最新大厂AI面试题 Q3版》两本图书,不少同学通过学习拿到拿到dream offer。
为了让更多AI人受益,七仔现把电子版免费送给大家,希望对你的求职有所帮助。如果点赞和点在看的人数较多,我会后续整理资料并分享答案给大家。
以下4本书,电子版,添加VX:julyedufu77(或七月在线任一老师)回复“088” 领取!

-
相关阅读:
吃透Spring源码分析专题
10.26~10.27论文,ALP: AdaptiveLossless floating-Point Compression
Centos 7.9安装PostgreSQL14.4步骤
超级兔子人
降低模拟量信号干扰的10个有效方法
etcd和redis的对比
德语翻译器在线翻译中文-德语翻译器支持各大语言翻译
MindSpore基础教程:使用 MindCV和 Gradio 创建一个图像分类应用
这波操作看麻了!十亿行数据,从71s到1.7s的优化之路。
ansible DBA常用场景命令小集
- 原文地址:https://blog.csdn.net/julyedu_7/article/details/125605088