-
MySQL 的索引和事务
一、索引
索引的主要意义就是进行查找,它的存在大大提高了查找效率。
但其查找效率提高了,同时也会有一些弊端。索引带来的好处:提高了查找的速度。
索引带来的坏处:占用了更多的空间,拖慢了增删改的速度。说白了,就是利用空间换取时间。而在实际场景中,查找操作要多于增删改的操作。
1. 查看索引
show index from 表名;- 1
拥有【unique 约束 】或【primary key 约束】,就会自动创建索引。
如下图,student 表有索引,score 表没有索引。

2. 创建索引
其中,下面索引名字是自定义起的名字。
create index 索引名字 on 表名(列名);- 1
3. 删除索引
drop index 索引名字 on 表名;- 1

然而,创建索引和删除索引是一件非常低效的操作,尤其是当表中有很多数据的时候。
对于线上的数据库,如果当前表中没有索引,我们不能贸然创建索引,同样我们也不能贸然删除索引,这容易将数据库弄崩溃。二、索引背后的数据结构
先来看三种数据结构:
二叉搜索树,B 树, B+ 树.
1. 二叉搜索树

二叉搜索树在我之前的博客中有写到,并不难,不再赘述。
2. B树

B 树的每个节点上,都会存储 N 个 key 值,N 个 key 值就划分了 N+1 个区间,每个区间都对应到一个新的节点,而从新的节点开始,又是一棵树…
在 B 树 中查找元素的过程和二叉搜索时非常相似,先从根节点出发,根据查找元素与当前节点来判断谁大谁小,以此来确定一个区间。
而我们从 B 树 的结构来看,很明显,它每一层所能比较节点的次数远远大于二叉搜索树的每一层的比较次数,这就会使利用 B 树 查找数据的时候,所能查找到的高度大大降低了。而树的高度又与磁盘 IO 次数有关,树的高度越低,磁盘的读写次数越少,那么就会使得查找速度快很多。
3. 理解B+ 树
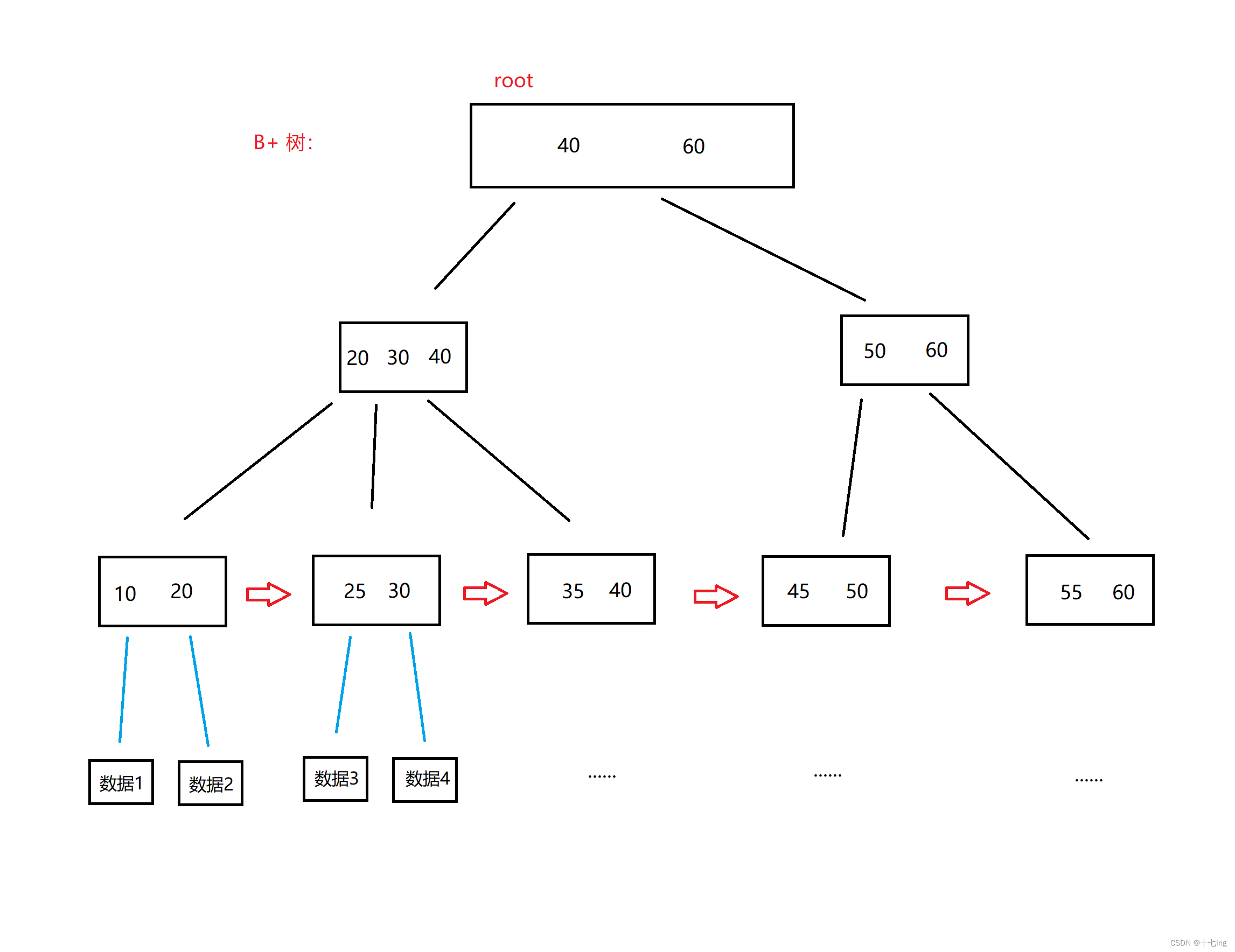
B+ 树是一棵 N 叉搜索树,每个节点上都包含多个 Key 值,每个节点如果有 N 个 Key,就分成了 N 个区间。
所有的非叶子节点的值,最终都会存储在叶子节点中,而叶子节点最终也通过链表结构得以顺序连接。
所有的节点存储的都是索引,而只有叶子节点可以通过索引值来找到数据。也就是说,叶子节点挂着对应的数据,而我们可以通过索引和其一一对应的数据之间的关系,找到索引,即可找到数据。B+ 树广泛用于数据库中
对于数据库的查找操作,它具有如下特点:
① 使用 B+ 树 进行查找时,整体的磁盘 IO 次数较少。
② 所有的查询最终都落在叶子节点中,每次的查询磁盘 IO 次数都是差不多的,查询速度非常稳定。
③ 最终我们还是通过所有的叶子节点,即链表进行查找数据的,所以非常适合进行某一范围、某一区间的查找。
④ 所有的数据存储都是放到叶子节点上的,非叶子节点中只保存 Key 值即可,因此非叶子节点占用的空间较小,甚至可以缓存到内存中。4. 理解索引
当别人 / 面试官让你谈谈对索引的理解,我们从三点出发:
(1) 索引是干啥的?
(2) 索引的适用场景,使用索引后,有什么优缺点?
(3) 索引背后的数据结构,(将 B+ 树画出来,直接按图陈述思路即可。)三、事务
1. 什么是计算机中的事务
事务的定义:在一个业务中,有很多操作步骤 / 任务,而事务对应的就是某项操作中不可再分割的单元,这个单元要么全部执行完,要么不执行。
事务存在的意义:为了把若干个独立的操作打包成一个整体。
2. 事务的基本特性
(1) 原子性
原子性即表示事务就是最小的单位,表示某个操作 / 任务不可再分。
在 MySQL 数据库的操作中表示:要么将这个操作所用到的 SQL 全部执行完,要么一个 SQL 都不执行。(2) 一致性
在事务执行前后,数据库中的数据都是合理合法的。
例如:你微信钱包有 100 元,而你从超市买了一瓶可乐,然后你通过微信扫码付钱给超市老板 3 元钱,对方就会收到 3 元钱,而你的微信就剩下了 97 元。事务的一致性就表示,你付给了老板 3 元钱,你的钱包 -3 元,老板的钱包 +3元,即合理交易。这不会造成你多了 3元钱,也不会造成老板收不到钱。
(3) 持久性
事务一旦提交后,数据就写入到硬盘之中,所以数据被持久化存储了起来。
(4) 隔离性
一个事务的运行与其他事务的运行,互不干扰。
四、理解并发与隔离两者的特点
1. 并发编程
并发编程是当下主要的一种编程方式,执行程序的特点是并发式进行的。
举个并发式程序的例子:当你打开电脑,你会使用多个软件,比方说:谷歌浏览器,网易云音乐,Word,计算器…而这些程序都在后台挂着,有的时候你需要经常切换来使用这些软件。2. 事务执行的一些问题
(1) 脏读
脏读:事务1 还未执行完某组数据的时候,事务2 拿到了事务1 的临时数据,注意 !!! 这里是临时数据,而当事务1 执行完所有的操作时,事务2 拿到的临时数据与事务1 的最终数据又不同了。
比方说:大学辅导员让班长创建一个在线文档, 统计一下全班的学号,全班有 30名学生,这30名同学一起在线填写文档,当全班同学都填完的时候,班长把这份文档发给了辅导员,但是辅导员发现有两个学号重名了,打回去给班长,重新统计。班长一脸懵逼,后来才发现,原来问题出现在:学号为 21 的同学在填写的时候,把学号为 20 的同学学号也填成了21号,这就导致了有两个 21号学号的重名现象。而辅导员第一次拿到的文档就表示其 “脏读” 了这份数据,并不是最终版本的文档。也就是说,刚刚的临时文档是一份不合理、不正确的数据。
上述的【脏读问题】,我们可以看到30 名同学在线编写文档,这就是并发式的特点,一起编写文档,如果没有一些特定的约束,也许就会有同学填错。然而30 名同学一起在线填写文档,这个速度是很快的。
(2) 不可重读
不可重读:在一个事务中,包含了多次读的操作,如果某个操作还没执行完,我们却进行多次读数据的操作,那么这些数据都是不一样的、错误的。
比方说:还是上面那个大学辅导员让班长创建一个在线文档的例子,班长让30 位同学在线填写表格,但是没有说明规则,这时所有的同学就都将信息填写在了在线文档的第一行。而每次班长查看的时候,都发现了错误,因为前面的同学总是被后一位同学填的信息覆盖。所以班长每次看到的数据其实是下一名同学的数据,这与顺序又对不上了,当然了,最终的结果显然就是最后一名同学的数据了,显然不是辅导员想要的结果。而每个同学填写一次后,班长就检查一下表格是否正确,这些多次读数据,而读的数据每次都是不一样的情况,就是不可重读的问题。
(3) 幻读
幻读:一个事务执行的过程中进行了多次查询,多次查询的结果都不一样,可能多了一条或少了一条,这种操作是一种特殊的不可重读读。
比方说:还是上面那个大学辅导员让班长创建一个在线文档的例子,当班长让30 位同学填写数据,然而,班长临时有事,当学号填写到10 号的时候,班长检查了一下没问题,他就交给了副班长去处理这件事情。但副班长不知道有没有填完,就直接把在线文档发给辅导员了,辅导员接收文件后,发现文档不完整,又打回去重新弄。之后,副班长有事,让学习委员来处理这件事,同样地,当学号填写了 20号的时候,学习委员就把文档交给辅导员了,最后又被打回来了。
而辅导员第一次读的文档是不完整的,第二次读的文档又是不完整的…这就是幻读问题。(4) 解决方式
那么如何解决以上三种方式呢?
解决方式:让班长创建30张表格,让每个同学轮流填写表格,不准在线编辑,前一个同学填好了表格,就把表格拿给下一位同学,直至最后一位同学填好了给班长,班长检查正确无误之后,再提交给辅导员。
而这个解决方式就对应着事务中的隔离性,彻底串行,没有并发运行的特点。
从上面在线表格的例子中我们就可以看到,当所有同学一起编程的时候,难免有错误,但是速度快,而隔离运行的时候,出错几率很小,但速度慢。那有没有折中的办法呢?五、MySQL中事务的隔离级别
所以,在实际问题中,我们可以根据实际需要来调整数据库的隔离级别,通过不同的隔离级别控制事务之间的隔离性,同时也就控制了并发程度。
MySQL中事务的隔离级别,提供了这么几种:
① read uncommitted:
允许读取未提交的数据,并发程度最高,隔离程度最低,会引入脏读、不可重读、幻读问题。② read committed:相当于给写操作加锁。
只允许读取提交之后的数据,并发程度降低了一些,隔离程度提高了一些。解决了脏读问题,会引入不可重读、幻读。③ repeatable read:相当于给读写操作都加锁。
并发程度又降低了,隔离程度提高了。解决了脏读、不可重复度,会引入幻读。④ serializable:串行化。
并发程度最低,隔离程度最高,解决了脏读、不可重读、幻读问题,但是执行速度最慢。 -
相关阅读:
C++ 动态库热加载
7月第3周榜单丨飞瓜数据B站UP主排行榜发布!
TYUT太原理工大学2022需求工程考试大题
javaScript学习———变量概述 变量的使用 变量语法扩展 变量命名规范交换 变量案例
Python标准库中的typing
番外--Task1:
keycloak~jwt的rs256签名的验证方式
Ribbon负载均衡算法
Spring Cloud(十四):微服务灰度发布 --- Discovery
Pikachu靶场——目录遍历漏洞和敏感信息泄露
- 原文地址:https://blog.csdn.net/lfm1010123/article/details/125553386