-
大数据:脚本实现WordCount,结果以压缩格式输出到HDFS
一、需求:
输出数据量较大时,可以使用Hadoop提供的压缩机制对数据进行压缩,减少网络传输带宽和存储的消耗。
-
可以指定对map的输出也就是中间结果进行压缩;
-
可以指定对reduce的输出也就是最终输出进行压缩;
-
可以指定是否压缩以及采用哪种压缩方式;
-
对map输出进行压缩主要是为了减少shuffle过程中网络传输数据量 ;
-
对reduce输出进行压缩主要是减少输出结果占用的HDFS存储。
二、将输出进行压缩
目的:实现WordCount,词频统计结果,以压缩格式输出到HDFS。
2.1 确定map.py
#!/usr/bin/python import os import sys import gzip def get_file_handler(f): file_in = open(f, 'r') return file_in def get_cachefile_handlers(f): f_handlers_list = [] if os.path.isdir(f): for fd in os.listdir(f): f_handlers_list.append(get_file_handler(f + '/' + fd)) return f_handlers_list def read_local_file_func(f): word_set = set() for cachefile in get_cachefile_handlers(f): for line in cachefile: word = line.strip() word_set.add(word) return word_set def mapper_func(white_list_fd): word_set = read_local_file_func(white_list_fd) for line in sys.stdin: ss = line.strip().split(' ') for s in ss: word = s.strip() #if word != "" and (word in word_set): if word !="": print "%s\t%s" % (s, 1) if __name__ == "__main__": module = sys.modules[__name__] func = getattr(module, sys.argv[1]) args = None if len(sys.argv) > 1: args = sys.argv[2:] func(*args)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
2.2 red.py
#!/usr/bin/python import sys def reduer_func(): current_word = None count_pool = [] sum = 0 for line in sys.stdin: word, val = line.strip().split('\t') if current_word == None: current_word = word if current_word != word: for count in count_pool: sum += count print "%s\t%s" % (current_word, sum) current_word = word count_pool = [] sum = 0 count_pool.append(int(val)) for count in count_pool: sum += count print "%s\t%s" % (current_word, str(sum)) if __name__ == "__main__": module = sys.modules[__name__] func = getattr(module, sys.argv[1]) args = None if len(sys.argv) > 1: args = sys.argv[2:] func(*args)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
用脚本一键启动map.py 与 red.py。
怎么写脚本?
2.3 run.sh
- 确定:
HADOOP_CMD="/usr/local/src/hadoop-2.6.5/bin/hadoop" - 确定:
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar" - 确定:input 输入文件的路径,
"/test/The_Man_of_Property.txt" - 确定:output 输出文件的路径,
"/output_cachearchive_broadcast" - 创建 mapper程序
- 创建 reduce程序
HADOOP_CMD="/usr/local/src/hadoop-2.6.5/bin/hadoop" STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar" INPUT_FILE_PATH_1="/test/The_Man_of_Property.txt" OUTPUT_PATH="/output_cachearchive_broadcast" # 输出文件已存在就删掉,避免因为文件存在导致的运行报错 $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH # Step 1. $HADOOP_CMD jar $STREAM_JAR_PATH \ -input $INPUT_FILE_PATH_1 \ -output $OUTPUT_PATH \ -mapper "python map.py mapper_func WH.gz" \ -reducer "python red.py reduer_func" \ -jobconf "mapred.reduce.tasks=5" \ -jobconf "mapred.job.name=cachefile_demo" \ -jobconf "mapred.compress.map.output=true" \ -jobconf "mapred.map.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec" \ -jobconf "mapred.output.compress=true" \ -jobconf "mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec" \ -cacheArchive "hdfs://master:9000/test/white.tar.gz#WH.gz" \ -file "./map.py" \ -file "./red.py"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
-mapper “python map.py mapper_func WH.gz”
-mapper意思是map函数;
python map.py mapper_func 意思是调用python的map.py程序里的mapper_func函数方法;
后面的WH.gz是一个参数,参数对应的是:-cacheArchive的#WH.gz;
-cacheArchive “hdfs://master:9000/test/white.tar.gz#WH.gz”
WH.gz 就是代表 white.tar.gz
-jobconf:提交作业的一些配置属性
常见配置:
(1)mapred.map.tasks:map task数目
(2)mapred.reduce.tasks:reduce task数目mapred.job.name 作业名 mapred.job.priority 作业优先级 mapred.compress.map.output map的输出是否压缩 mapred.map.output.compression.codec map的输出压缩方式 mapred.output.compress reduce的输出是否压缩 mapred.output.compression.codec reduce的输出压缩方式 mapred.job.map.capacity 最多同时运行map任务数 mapred.job.reduce.capacity 最多同时运行reduce任务数 mapred.task.timeout 任务没有响应(输入输出)的最大时间 

run.sh 脚本执行完毕,查看结果:hadoop fs -ls /output_cachearchive_broadcast

可以看到输出结果是五个压缩包。看看里面的内容:1. 用cat方法:
hadoop fs -cat /output_cachearchive_broadcast/part-00000.gz | head,会乱码,查看不了,得换一种。
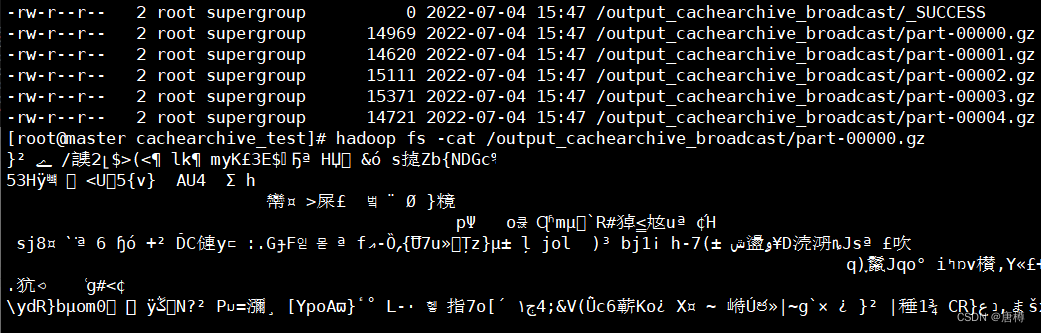
2. 用text方法:
hadoop fs -text /output_cachearchive_broadcast/part-00000.gz | head可以查看压缩文件内容!!
完成:实现WordCount,词频统计结果,以压缩格式输出到HDFS。
如何对这些压缩文件解压呢?
用脚本一键解压。
三、解压缩文件
3.1 设置脚本
- 确定:
HADOOP_CMD="/usr/local/src/hadoop-2.6.5/bin/hadoop" - 确定:
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar" - 确定:input 压缩文件的路径,
"/output_cachearchive_broadcast" - 确定:output 输出解压文件的路径,
"/output_cat" - mapper 为
"cat" - -jobconf map red 任务为0
HADOOP_CMD="/usr/local/src/hadoop-2.6.5/bin/hadoop" STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar" INPUT_PATH="/output_cachearchive_broadcast" OUTPUT_PATH="/output_cat" #$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH # Step 2. $HADOOP_CMD jar $STREAM_JAR_PATH \ -input $INPUT_PATH\ -output $OUTPUT_PATH\ -mapper "cat" \ -jobconf "mapred.reduce.tasks=0"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
运行脚本
run.sh
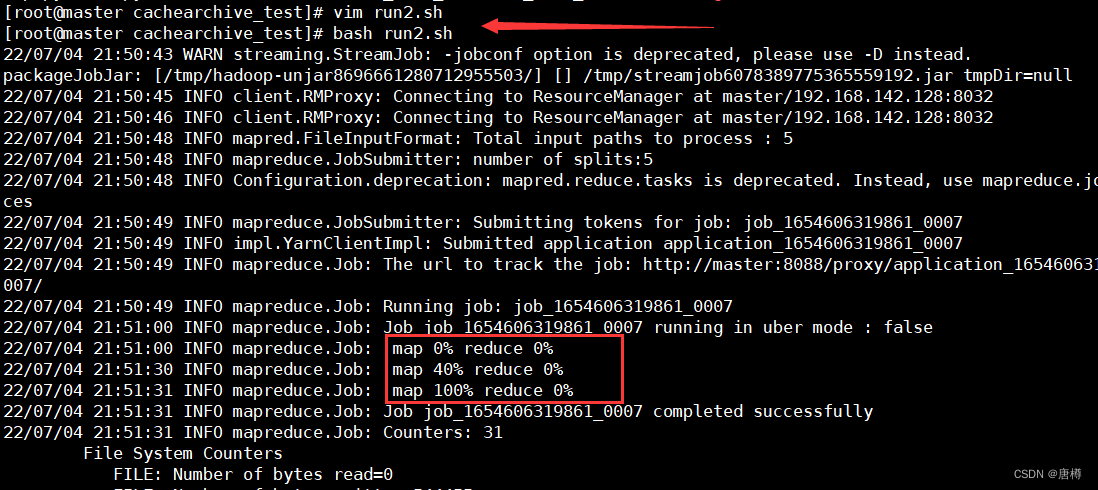
hadoop fs -ls /output_cat
1. 用cat方法:hadoop fs -cat /output_cat/part-00000 | head
-
-
相关阅读:
mysql 查询表字段名,注释 , 以及sql拼接查询出的内容
【SpringCloud-学习笔记】Docker基本操作
A Survey on Fairness in Large Language Models
thinkphp withJoin 模式下field 无效
如何在App里面运行Mac OS 8?
GateWay实现负载均衡
代码随想录笔记_动态规划_377组合总和IV
Image Super-Resolution with Text Prompt Diffusion
[Docker]一.Docker 简介与安装
02-微服务的拆分规则和基于RestTemplate的远程调用
- 原文地址:https://blog.csdn.net/weixin_44775255/article/details/125601898
