-
基础数据结构——二叉搜索树
目录
1.二叉搜索树的概念
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树
若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
它的左右子树也分别为二叉搜索树
具体我们可以看到下图就是一棵二叉搜索树

同时我们也可以注意到按照中序遍历的方法去遍历一棵二叉搜索树他的结果一定是有序的。
2.基本功能的实现
2.1 查找
由上述性质我们可以知道二叉树的左节点一定小于当前根节点,右节点一定大于当前根节点。所以我们可以得到以下查找的方法。
若根节点不为空:
1.如果根节点key==查找key 返回true
2.如果根节点key>查找key 继续查找左子树
3.如果根节点key<查找key 继续查找右子树
否则返回 false
由以上操作我们可以得到下面的代码:
- public Node Search(int key){
- Node cur=root;
- while(cur!=null){
- if(cur.val<key){
- cur=cur.right;
- }else if(cur.val==key){
- return cur;
- }else{
- cur=cur.right;
- }
- }
- return null;
- }
2.2 插入
在插入同时我们也需要满足二叉搜索树的基本性质,同时我们也不允许存在重复元素。
如果是空树,直接插入,然后返回true
如果不是空树,则先按照之前查找的方法找到待插入的位置,之后将待插入位置的parent记录
之后根据待插入数据与parent的关系插入到parent的左节点或者右节点即可
- public boolean insert(int val){
- if(root==null){
- root=new Node(val);
- return true;
- }
- Node cur=root;
- Node parent=null;
- while(cur!=null){//找到待插入位置parent
- if(cur.val<val){
- parent = cur;
- cur = cur.right;
- }else if(cur.val==val){
- return false;
- }else{
- parent=cur;
- cur=cur.left;
- }
- }
- Node node=new Node(val);
- if(parent.val < val) {
- parent.right=node;
- }else {
- parent.left = node;
- }
- return true;
- }
2.3 删除
删除操作比较麻烦,我们要分为以下三种情况讨论
设待删除结点为 cur, 待删除结点的双亲结点为 parent
1. cur.left == null
1. cur 是 root,则 root = cur.right
2. cur 不是 root,cur 是 parent.left,则 parent.left = cur.right
3. cur 不是 root,cur 是 parent.right,则 parent.right = cur.right
2. cur.right == null
1. cur 是 root,则 root = cur.left
2. cur 不是 root,cur 是 parent.left,则 parent.left = cur.left
3. cur 不是 root,cur 是 parent.right,则 parent.right = cur.left
3. cur.left != null && cur.right != null
这个时候我们需要找到左树最大值或者右树最小值然后交换,之后就可以转换成上面两种情况来处理了
- private void removeNode(Node cur,Node parent){
- if(cur.left == null){
- if(cur==root){
- root=cur.right;
- }else if(cur==parent.left){
- parent.left=cur.right;
- }else{
- parent.right=cur.right;
- }
- }else if(cur.right==null){
- if(cur==root){
- root=cur.left;
- }else if(cur==parent.left){
- parent.left=cur.left;
- }else{
- parent.right=cur.left;
- }
- }else{//如果左右均存在节点,则找到左树最大值或者右树最小值然后交换
- Node targetParent = cur;
- Node target=cur.right;//右树找最小
- while(target.left!=null){
- targetParent=target;
- target=targetParent.left;
- }
- cur.val=target.val;//交换
- if(target == targetParent.left) {//删除左节点,因为左节点已经被替换上去了
- targetParent.left = target.right;
- }else {
- targetParent.right = target.right;
- }
- }
- }
到此我们的基本操作就已经完成了,接下来的细节部分代码我将会放在下一部分。
3.完整代码及性能分析
完整代码我将放在gitee上,大家可自己查看https://gitee.com/invictusQAQ/BinarySearchTree/blob/master/src/BinarySearchTreeDemo.java
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。
对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二叉搜索树的深度 的函数,即结点越深,则比较次数越多。
但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树:


比如上图左的完全二叉树和上图右的单支树
最优情况下,二叉搜索树为完全二叉树,其平均比较次数为:
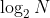
最差情况下,二叉搜索树退化为单支树,其平均比较次数为:N(忽略常数1/2)
而在退化成单分支树的情况下我们就失去了搜索树的优势,之后我们才有了avl树B树等更加优化的数据结构来解决这些问题,大家自行了解即可
-
相关阅读:
Promise系列学习
CentOS7设置 redis 开机自启动
vector迭代器失效问题
Docker常用命令
Nginx请求强制缓存设置
linux下的定时任务
查看服务器的配置,系统,cpu等信息
微信小程序OA会议系统个人中心授权登入
uni-app设置分包和预下载
python代码规范工具
- 原文地址:https://blog.csdn.net/weixin_60778429/article/details/125595329
