-
Pointnet/Pointnet++点云数据集处理并训练
一、三维数据的表示方法
三维数据的表述形式一般分为四种:① 点云:由N 个D 维的点组成,当这个D = 3 的时候一般代表着( x , y , z ) 的坐标,当然也可以包括一些法向量、强度等别的特征。这是今天主要讲述的数据类型。

② Mesh:由三角面片和正方形面片组成。

③ 体素:由三维栅格将物体用0和1表征。

④ 多角度的RGB图像或者RGB-D图像

而又由于点云更接近于设备的原始表征(即雷达扫描物体直接产生点云)同时它的表达方式更加简单,一个物体仅用一个N × D 的矩阵表示,所以点云成为了众多三维数据表示方法中最重要的一种。在测绘、建筑、电力、工业甚至如今最热门的自动驾驶等领域均有广泛的应用。二、点云分割数据集处理
我们的点云数据可能与模型需要的数据不符,所以需要自己编写脚本进行数据的规范化。标准的点云数据处理的格式如下:

其只包含了点云的(x,y,z)坐标以及每个点对应的标签。而可能我们从CloudCompare中导出的数据有四列数据还有一列点云的强度信息: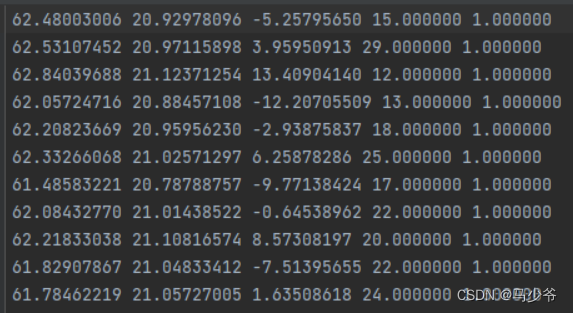
所以编写如下的脚本对多余的第四列数据进行去除(文件的具体路径自己设置):# -*- coding:utf-8 -*- import os filePath = 'D:\\点云数据处理小组\\pointnet-my\\data\\shapenetcore_partanno_segmentation_benchmark_v0_normal\\03797390' for i,j,k in os.walk(filePath): for name in k: print(name) f = open(filePath+name) # 打开txt文件 line = f.readline() # 以行的形式进行读取文件 list1 = [] while line: a = line.split() b = a[0:3] c = float(a[-1]) print(c) if(float(a[-1])==36.0): c=2 if(float(a[-1])==37.0): c=3 b.append(c) list1.append(b) # 将其添加在列表之中 line = f.readline() f.close() print(list1) with open(filePath+name, 'w+') as file: for i in list1: file.write(str(i[0])) file.write(' '+str(i[1])) file.write(' ' + str(i[2])) file.write(' ' + str(i[3])) if(i!=list[-1]): file.write('\n') file.close() # path_out = 'test.txt' # 新的txt文件 # with open(path_out, 'w+') as f_out: # for i in list1: # fir = '9443_' + i[0] # 第一列加前缀'9443_' # sec = 9443 + int(i[1]) # 第二列数值都加9443 # # print(fir) # # print(str(sec)) # f_out.write(fir + ' ' + str(sec) + '\n') # 把前两列写入新的txt文件- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
接着我们需要对划分训练集、测试集、验证集的json文件进行处理,由于我们采用的是自己的数据集,每一个txt的文件名与之前官方数据集中的文件名一定不一样,所以需要编写脚本对控制训练集、测试集、验证集读入的三个json文件进行修改。具体代码如下(路径名同样需要修改为自己的路径名):
import os filePath = 'D:\\点云数据处理小组\\pointnet-my\\data\\shapenetcore_partanno_segmentation_benchmark_v0_normal\\03797390' #####最后一行会出现一个, 报错!!!!!!!!! ######手动删除或改进程序 ##### file = '1.txt' with open(file,'a') as f: f.write("[") for i,j,k in os.walk(filePath): for name in k: base_name=os.path.splitext(name)[0] #去掉后缀 .txt f.write(" \"") f.write(os.path.join("shape_data/03797390/",base_name)) f.write("\"") f.write(",") f.write("]") f.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
最后在实际程序运行时发现会由于含0的数据过多而导致模型分类不准确,如下:

而根据具体项目的实际物理意义(这里的全0即表示未被激光探测到的位置,x,y,z坐标均标注为0),所以编写脚本程序对全0的部分进行去除:# -*- coding:utf-8 -*- import os filePath = 'D:\\点云数据处理小组\\pointnet-my\\data\\shapenetcore_partanno_segmentation_benchmark_v0_normal\\03797390' for i,j,k in os.walk(filePath): for name in k: list1 = [] for line in open(filePath+name): a = line.split() #print(a) b = a[0:6] #print(b) a1 =float(a[0]) a2 =float(a[1]) a3 =float(a[2]) #print(a1) if(a1==0 and a2==0 and a3==0): continue list1.append(b[0:6]) with open(filePath+name, 'w+') as file: for i in list1: file.write(str(i[0])) file.write(' '+str(i[1])) file.write(' ' + str(i[2])) file.write(' ' + str(i[3])) file.write(' ' + str(i[4])) if(i!=list[-1]): file.write('\n') file.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
三、 模型训练
我们打开项目文件夹下的model文件夹,选择以pointnet2_part_seg_msg为名的python文件,双击进入:

接下来我们需要修改的地方为PointNetFeaturePropagation的in_channel,具体方法为128+4分割的总类个数,比如这里我们的分割采用的是两个物体,每个物体均为2分类,所以通道数为128+42=136: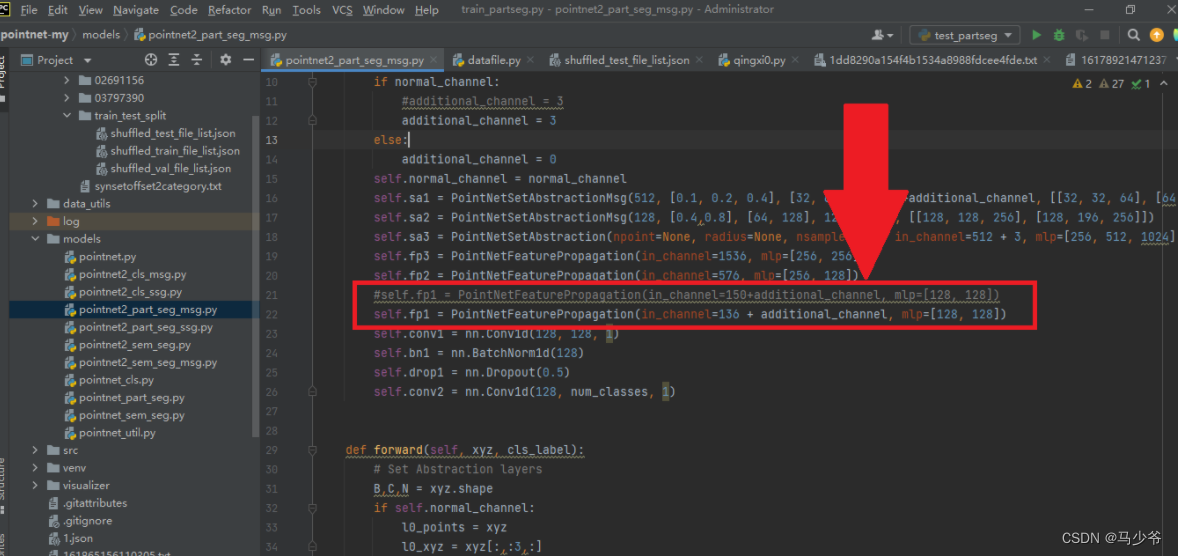
接着我们需要修改独热编码部分,将view方法中的第二个参数修改为需要被分割的物体的种类数:

2.2.5 训练模型部分的修改
在训练模型的时候,我们需要修改要分类的对象seg_classes为我们自己的数据集对应的类别,如例子中的分类两个类别,每个类别有两个部件。(为了方便,我们保留了原来的’Airplane’: [0, 1], ‘Mug’: [2, 3]这两个名字,同时应该注意,编号应该从0开始依次编号,若不是这样则会报错),同时应该注意自己的电脑是否支持cuda加速,如果没有GPU,则可以把代码后面所有的".cuda()"删去,程序才能正确运行。

接下来我们需要修改分割的物体总数num_classes为自己的类别个数,总共的部件数为自己的总个数:num_part。

最后,右键运行程序,如果出现进度条则表明模型已经成功改进,可以跑通自己的数据集啦!

四、打印模型预测数据
我们在用自己的数据集训练完模型后,将利用名为test_partseg的python文件进行模型的测试,为了更好的理解模型以及测试模型效果,我们有时需要打印出模型预测后的点云坐标。这里给出test_partseg文件的修改方法以及运行结果。4.1 测试模型代码修改
首先我们需要找到该python文件,接着与上面同样的修改如下图的两个地方:

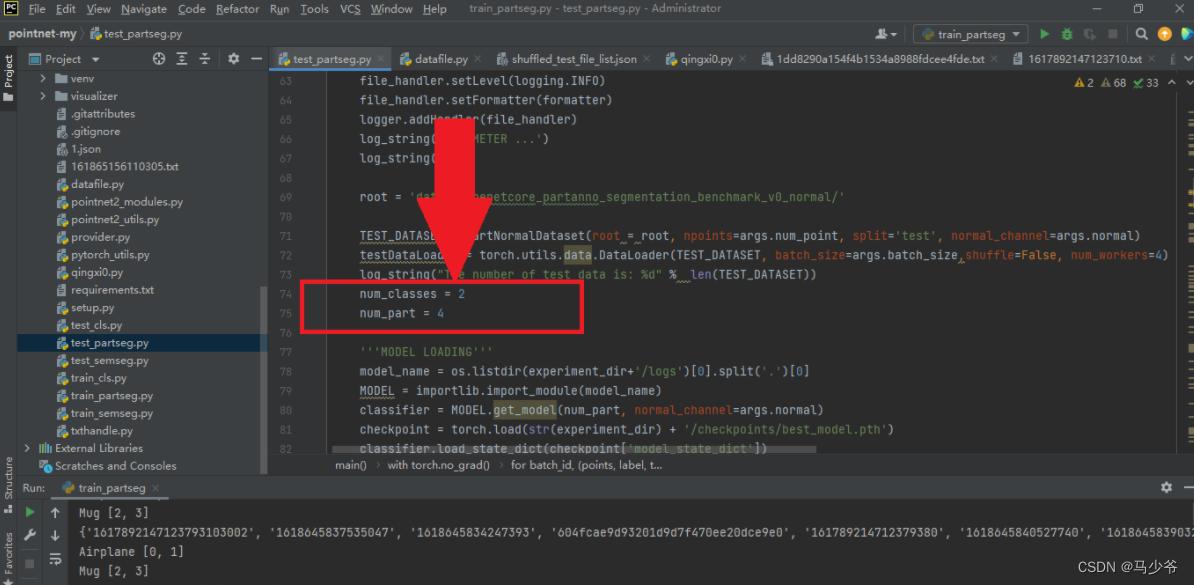
接着我们需要编写代码打印出分类后的具有不同标签的坐标,本例子中要打印两个物体的四个类别的坐标点,代码如下(部分代码):
for j in aaa: #print(points1[i,j]) res1= open(r'E:\03797390_0_'+str(i)+'.txt', 'a') res1.write('\n' + str(points1[i,j]).strip('[]')) res1.close() xxxxxx=xxxxxx+1 bbb = numpy.argwhere(cur_pred_val[i] == 1) for j in bbb: #print(points1[i, j]) res2 = open(r'E:\03797390_1_' + str(i) + '.txt', 'a') res2.write('\n' + str(points1[i,j]).strip('[]')) res2.close() xxxxxx = xxxxxx + 1 ccc = numpy.argwhere(cur_pred_val[i] == 2) for j in ccc: #print(points1[i, j]) res3 = open(r'E:\02691156_2_' + str(i) + '.txt', 'a') res3.write('\n' + str(points1[i,j]).strip('[]')) res3.close() xxxxxx = xxxxxx + 1 ddd = numpy.argwhere(cur_pred_val[i] == 3) for j in ddd: #print(points1[i, j]) res4 = open(r'E:\02691156_3_' + str(i) + '.txt', 'a') res4.write('\n' + str(points1[i,j]).strip('[]')) res4.close() xxxxxx = xxxxxx + 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
修改完成后运行程序发现可以显示结果,表明修改成功!

打印出的点云坐标格式如下:


参考文献:https://blog.csdn.net/weixin_44603934/article/details/123589948 -
相关阅读:
Linux的七种运行级别
C++ QT QLocalSocket/QLocalServer基操
Python在字典中获取带权重的随机值
【解决Qt编译报错:-1: warning: **.so, not found(try using -rpath or -rpath-link)】
LeetCode 10. 正则表达式匹配
SAP 电商云 Spartacus UI 的 Product Category Navigation UI 实现
这项镜头贴膜技术背后,藏着让VR变轻巧的秘密
5.js模块化
C#中错误与异常处理
阶乘算法优化
- 原文地址:https://blog.csdn.net/qq_27353621/article/details/125594871
