-
【Python数据分析】某地区病人死亡数据分析
目录
链接:数据集
提取码:66661.任务要求
- 理解两个文件“deaths.xlsx”和“icd-main.xlsx”的数据结构,通过编程查看文件内容和信息。筛选出2007和2008年两年的个体死亡数据,并去掉无效数据,保存为文件“death0708.csv”。
- 从文件“death0708.csv”读取数据,分组统计不同死亡原因导致的死亡人数,并与“icd-main.xlsx”连接,保存为文件“cause-deaths.csv”。
- 从文件“death0708.csv”读取数据,分组统计不同时刻的死亡人数,计算每个时刻死亡人数占比,并把占比数据增加为一列,保存为文件“hour-deaths.csv”。根据百分比画出折线图,横坐标是一天的24小时,总坐标是百分比。
- 对结果进行评价,得出结论。并说明这些结果对于社会、健康、安全、法律以及文化的影响。
2.流程图
2.1 第一题流程图
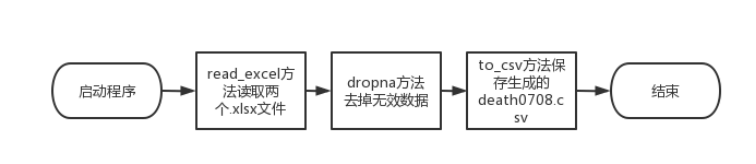
图2.1 第一题流程图
2.2第二题流程图

图2.2 第二题流程图
2.3 第三题流程图
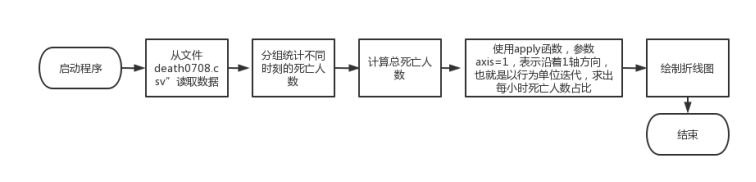
图2.3 第三题流程图
3. 详细代码
- # 1.理解两个文件“deaths.xlsx”和“icd-main.xlsx”的数据结构,通过编程查看文件内容和信息。筛选出2007和2008年两年的个体死亡数据,并去掉无效数据,保存为文件“death0708.csv”。
- # 2.从文件“death0708.csv”读取数据,分组统计不同死亡原因导致的死亡人数,并与“icd-main.xlsx”连接,保存为文件“cause-deaths.csv”。
- # 3.从文件“death0708.csv”读取数据,分组统计不同时刻的死亡人数,计算每个时刻死亡人数占比,并把占比数据增加为一列,保存为文件“hour-deaths.csv”。根据百分比画出折线图,横坐标是一天的24小时,总坐标是百分比。
- # 4.对结果进行评价,得出结论。并说明这些结果对于社会、健康、安全、法律以及文化的影响。
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- # 解决乱码
- plt.rcParams['font.sans-serif'] = ['SimHei']
- plt.rcParams['font.family'] = 'sans-serif'
- plt.rcParams['axes.unicode_minus'] = False
- # 读取deaths.xlsx和icd-main中的数据
- deaths = pd.read_excel('E:\学习\代码\Python_homework\期末课程设计\experiment1\data\deaths.xlsx',index_col=0)
- codes = pd.read_excel('E:\学习\代码\Python_homework\期末课程设计\experiment1\data\icd-main.xlsx')
- print(deaths.columns)
- print(codes.columns)
- print(deaths.describe()) # 查看数据值列的汇总统计
- # 筛选出2007和2008年的个体死亡数据,并去掉无效数据,保存为文件“death0708.csv”
- # Pandas dataframe.ne()函数使用常量,序列或其他按元素排列的 DataFrame 检查 DataFrame 元素的不等式。如果比较中的两个值不相等,则返回true;否则,返回false
- # 筛选数据,dropna()函数删除无效数据
- d0708 = deaths[(deaths.yod == 2008) | (deaths.yod == 2007) & (deaths['dod'].ne(0)) & (deaths['mod'].ne(0))].dropna()
- print(d0708.head(10))
- print(d0708.shape)
- # 保存为文件“death0708.csv”
- d0708.to_csv('E:\学习\代码\Python_homework\期末课程设计\experiment1\data\death0708.csv',encoding='utf-8')
- # 从文件“death0708.csv”读取数据,分组统计不同死亡原因导致的死亡人数,并与“icd-main.xlsx”连接,保存为文件“cause-deaths.csv”
- deaths0708 = pd.read_csv('E:\学习\代码\Python_homework\期末课程设计\experiment1\data\death0708.csv')
- # 添加一列,值全部为1,便于分类后求和就可以计数。
- # deaths0708['count'] = 1
- # 分类汇总按照['cod']分类,取得['count']列
- # c_group = deaths0708.groupby(['cod'])['count']
- # # 对['count’]列使用求和函数,agg函数对分组后数据进行聚合
- # c_group = c_group.agg([np.sum])
- # print(c_group.head(5))
- print('_________________________________________')
- # 使用size函数更快求得分组函数的分类计数
- c_group = deaths0708.groupby(['cod'])
- # reset_index函数将原来的index设置为列rename函数更改列名
- c = c_group.size().reset_index()
- new_col = ['cod', 'death_counts']
- c.columns = new_col
- # 整理后的个体死亡数据集是c
- # 将c的‘cod’列重命名位‘code’与codes中的列名‘code’一致
- # 根据code列把c和code合并为一个DataFrame
- c = c.rename(columns={'cod': 'code'})
- # 显示要合并的两个对象的前三行
- print(c.head(3))
- print(codes.head(3))
- # 合并两个DataFrame
- c = c.merge(codes, on='code')
- c.index.name = 'no'
- print('________________现在的c__________________')
- print(c.head())
- # 保存为文件“cause-deaths.csv
- c.to_csv('E:\学习\代码\Python_homework\期末课程设计\experiment1\data\cause-deaths.csv')
- # 从文件“death0708.csv”读取数据,分组统计不同时刻的死亡人数,计算每个时刻死亡人数占比,并把占比数据增加为一列,保存为文件“hour-deaths.csv”。根据百分比画出折线图,横坐标是一天的24小时,总坐标是百分比
- # 增加了一列,名字叫’prop_hour'
- # 使用apply函数,参数axis=1,表示沿着1轴方向,也就是以行为单位迭代
- # 对每一行,用row['death_counts']/code_value_counts[row['code']]获取比率
- # apply函数返回一个Series,使用round函数保留四位小数
- h_group = deaths0708.groupby(['hod'])
- h = h_group.size().reset_index()
- new_column = ['hod', 'death_counts']
- h.columns = new_column
- # 计算总的死亡人数
- death_value_count = deaths0708.index.size
- h['prop_hour'] = h.apply(lambda row: row['death_counts']/death_value_count, axis=1)
- h['prop_hour'] = h['prop_hour'].round(4)
- print(h.head(24))
- x = h.index
- y = h['prop_hour'].values*100
- plt.title('每小时死亡数目占总死亡数目的百分比')
- plt.xlabel("时间\h")
- plt.ylabel('百分比\%')
- plt.plot(x, y, '-')
- plt.grid()
- plt.show()
4.运行结果和数据分析
图4.1 cause-deaths.csv

图4.2 death0708.csv

图4.3 每小时死亡率折线图
5.结果评价
统计了每个时刻的死亡人数,然后计算了死亡总人数,用每个小时的死亡人数除死亡总人数的除了每个时刻的死亡人数。
由每小时死亡数占总死亡数目的百分比可以看出,不同时刻的死亡率有明显的差异,大致如同一个”n”型,在早上五点,上午酒店,下午五点死亡率最高,此时要提醒身边人这些时间要注意安全。
通过对每小时的死亡率的分析,可以发现每小时不同的死亡率,对于不同人经常的活动时间进行分组,然后结合死亡率来判断保险类型。而死亡率对于社会来说,可以引导各公司动态调节工作时间,避开死亡率高的时段。而死亡率的得出,再结合网络上不同年龄阶段的死亡率数据,也可以让国家动态调节一些政策。
-
相关阅读:
屏蔽搜索引擎的无用蜘蛛,减轻服务器压力
java计算机毕业设计学生公寓管理系统源码+系统+mysql数据库+lw文档
Linux 5.20 可能将版本号升级为 Linux 6.0
Java中Long型数据类型对应MySQL数据库中哪种类型?
Python性能优化
Creo 9.0 中几何对象的选取方法
【代码随想录】算法训练计划23
一、Rabbit的介绍与安装
【Hugging Face】如何下载模型文件
SAP PA HR后台配置
- 原文地址:https://blog.csdn.net/m0_67463447/article/details/125563691
