-
Pair RDD的操作
原创申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址
全文共计6644字,阅读大概需要3分钟
欢迎关注我的个人公众号:不懂开发的程序猿1. 实验室名称:
大数据实验教学系统
2. 实验项目名称:
Pair RDD的操作
3. 实验学时:
4. 实验原理:
一些Spark操作只在键值对的RDDs上可用。Spark在包含key/value对的RDDs上提供了专门的transformation API,包括reduceByKey、groupByKey、sortByKey和join等。
Pair RDDs让我们能够在key上并行操作,或者跨网络重新组织数据。Key/value RDDs常被用于执行聚合操作,以及常被用来完成初始的ETL(extract, transform, load)以获取key/value格式数据。5. 实验目的:
掌握Pair RDD专属Transformation转换方法。
掌握Pair RDD专属Action行动方法。
掌握Pair RDD的JOIN操作。6. 实验内容:
1、对Pair RDD执行各种常见转换操作:reduceByKey、groupByKey、sortByKey和join等。
2、对Pair RDD执行各种常见action操作:countByKey、collectAsMap、lookup等。7. 实验器材(设备、虚拟机名称):
硬件:x86_64 ubuntu 16.04服务器
软件:JDK 1.8,Spark-2.3.2,Hadoop-2.7.3,zeppelin-0.8.1,Scala-2.11.118. 实验步骤:
8.1 启动Spark集群
在终端窗口下,输入以下命令,启动Spark集群。
1. $ cd /opt/spark 2. $ ./sbin/start-all.sh- 1
- 2
然后使用jps命令查看进程,确保Spark的Master进程和Worker进程已经启动。
8.2 启动zeppelin服务器
在终端窗口下,输入以下命令,启动zeppelin服务器。
1. $ zeppelin-daemon.sh start- 1
然后使用jps命令查看进程,确保zeppelin服务器已经启动。
8.3 创建notebook文档
1、首先启动浏览器,在地址栏中输入以下url地址,连接zeppelin服务器。
http://localhost:9090
2、如果zeppelin服务器已正确建立连接,则会看到如下的zeppelin notebook首页。
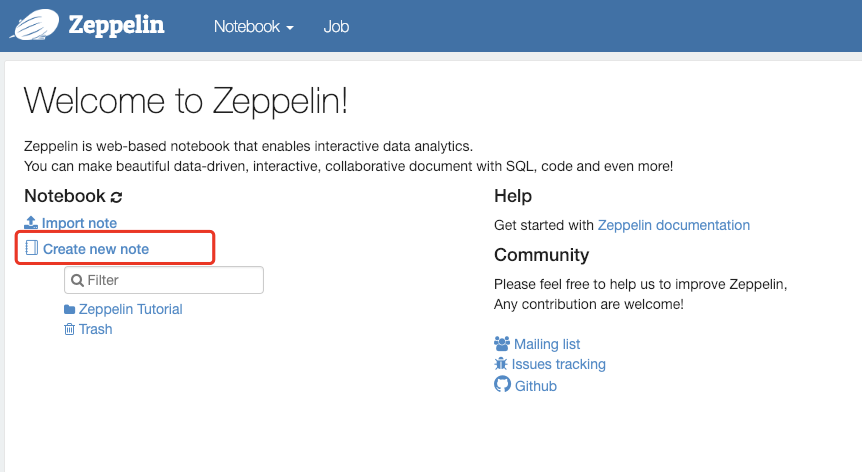
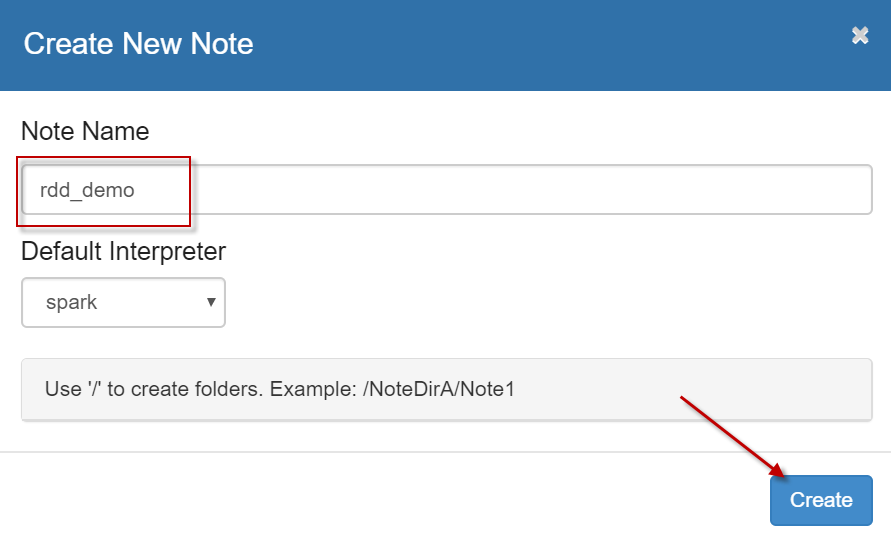
3、点击【Create new note】链接,创建一个新的笔记本,并命名为”rdd_demo”,解释器默认使用”spark”,如下图所示。
8.4 创建Pair RDD
创建Pair RDD的方式有多种。
1、第一种创建方式:从文件中加载。在zeppelin中执行以下代码:1. // 方式1:从文件中加载,使用map转换为pair rdd 2. val hdfsPath = "file:///data/dataset/resources/people.txt" 3. val rdd = sc.textFile(hdfsPath) 4. 5. // 转换 6. val pairRDD = rdd.map(line => line.split(",")).map(arr => (arr(0),arr(1).trim.toInt)) 7. pairRDD.collect- 1
- 2
- 3
- 4
- 5
- 6
- 7
同时按下【shift+enter】,执行以上代码,输出内容如下:
res45: Array[(String, Int)] = Array((Michael,29), (Andy,30), (Justin,19))- 1
2、第二种创建方式:通过并行集合创建Pair RDD。在zeppelin中执行以下代码:
1. // 方式2:通过并行集合创建Pair RDD 2. val rdd = sc.parallelize(List("Hadoop","Spark","Hive","Spark")) 3. val pairRDD = rdd.map(word => (word,1)) 4. pairRDD.collect- 1
- 2
- 3
- 4
同时按下【shift+enter】,执行以上代码,输出内容如下:
res139: Array[(String, Int)] = Array((Hadoop,1), (Spark,1), (Hive,1), (Spark,1))- 1
通过应用keyBy函数来生成对应的key。例如,下面的代码使用每个单词的长度为key,返回构造以后的Pair RDD:
1. val rdd1 = sc.parallelize(List("black","blue","white","green","grey"),2) 2. 3. // 通过应用keyBy函数来创建该RDD中元素的元组,返回一个pair RDD 4. val pairRDD1 = rdd1.keyBy(_.length) 5. pairRDD1.collect- 1
- 2
- 3
- 4
- 5
同时按下【shift+enter】,执行以上代码,输出内容如下:
res141: Array[(Int, String)] = Array((5,black), (4,blue), (5,white), (5,green), (4,grey))- 1
8.5 transformation操作
假设有一个pair rdd {(1,2),(3,4),(3,6)}。首先,让我们构造出一个Pair RDD。在zeppelin中执行以下代码:
1. // 构造pair rdd 2. val pairRDD = sc.parallelize(Seq((1,2),(3,4),(3,6))) 3. pairRDD.collect- 1
- 2
- 3
接下来,学习Pair RDD上的各种转换操作方法:
1、reduceByKey:按照key来合并值,返回新的Pair RDD。在zeppelin中执行如下代码:1. val p1 = pairRDD.reduceByKey((x,y) => x + y) 2. p1.collect- 1
- 2
同时按下【shift+enter】,执行以上代码,输出内容如下:
res147: Array[(Int, Int)] = Array((1,2), (3,10))
2、groupByKey:按照key进行分组。在zeppelin中执行如下代码:1. val p2 = pairRDD.groupByKey 2. p2.collect- 1
- 2
同时按下【shift+enter】,执行以上代码,输出内容如下:
res150: Array[(Int, Iterable[Int])] = Array((1,CompactBuffer(2)), (3,CompactBuffer(4, 6)))- 1
3、keys:返回所有的key,返回结果是一个数组。在zeppelin中执行如下代码:
1. val p3 = pairRDD.keys 2. p3.collect- 1
- 2
同时按下【shift+enter】,执行以上代码,输出内容如下:
res153: Array[Int] = Array(1, 3, 3)- 1
4、values。返回所有的值,返回结果是一个数组。在zeppelin中执行如下代码:
1. val p4 = pairRDD.values 2. p4.collect- 1
- 2
同时按下【shift+enter】,执行以上代码,输出内容如下:
res156: Array[Int] = Array(2, 4, 6)- 1
5、sortByKey:按key进行排序。在zeppelin中执行如下代码:
1. // val p5 = pairRDD.sortByKey() // 默认是升序 2. val p5 = pairRDD.sortByKey(false) // 降序 3. p5.collect- 1
- 2
- 3
同时按下【shift+enter】,执行以上代码,输出内容如下:
res164: Array[(Int, Int)] = Array((3,4), (3,6), (1,2))- 1
6、mapValues:key不变,对值进行map转换。在zeppelin中执行如下代码:
1. val p6 = pairRDD.mapValues(x => x*x) 2. p6.collect- 1
- 2
同时按下【shift+enter】,执行以上代码,输出内容如下:
res167: Array[(Int, Int)] = Array((1,4), (3,16), (3,36))- 1
7、flatMapValues:key不变,对值先进行map转换,再进行flatten转换。在zeppelin中执行如下代码:
1. val p7 = pairRDD.flatMapValues(x => (x to 5)) 2. p7.collect- 1
- 2
同时按下【shift+enter】,执行以上代码,输出内容如下:
res170: Array[(Int, Int)] = Array((1,2), (1,3), (1,4), (1,5), (3,4), (3,5))- 1
8.6 操作多个pair rdd
还可以对两个pair rdd执行集合操作和join连接操作。假设有两个RDD,分别是{(1,2),(3,4),(3,6)}和{(3,9)}。
1、首先构造两个pair rdd。在zeppelin中执行如下代码:1. // 构造两个pair rdd 2. val pairRDD1 = sc.parallelize(Seq((1,2),(3,4),(3,6))) 3. pairRDD1.collect 4. 5. val pairRDD2 = sc.parallelize(Seq((3,9))) 6. pairRDD2.collect- 1
- 2
- 3
- 4
- 5
- 6
同时按下【shift+enter】,执行以上代码,输出内容如下:
res178: Array[(Int, Int)] = Array((1,2), (3,4), (3,6)) res179: Array[(Int, Int)] = Array((3,9))- 1
- 2
2、ubstractByKey:按key计算差集。在zeppelin中执行如下代码:
1. val r1 = pairRDD1.subtractByKey(pairRDD2) 2. r1.collect- 1
- 2
同时按下【shift+enter】,执行以上代码,输出内容如下:
res182: Array[(Int, Int)] = Array((1,2))- 1
3、执行join内连接。在zeppelin中执行如下代码:
1. val r2 = pairRDD1.join(pairRDD2) 2. r2.collect- 1
- 2
同时按下【shift+enter】,执行以上代码,输出内容如下:
res185: Array[(Int, (Int, Int))] = Array((3,(4,9)), (3,(6,9)))- 1
4、执行join左外连接。在zeppelin中执行如下代码:
1. val r3 = pairRDD1.leftOuterJoin(pairRDD2) 2. r3.collect- 1
- 2
同时按下【shift+enter】,执行以上代码,输出内容如下:
res188: Array[(Int, (Int, Option[Int]))] = Array((1,(2,None)), (3,(4,Some(9))), (3,(6,Some(9))))- 1
5、执行join右外连接。在zeppelin中执行如下代码:
1. val r4 = pairRDD1.rightOuterJoin(pairRDD2) 2. r4.collect- 1
- 2
同时按下【shift+enter】,执行以上代码,输出内容如下:
res191: Array[(Int, (Option[Int], Int))] = Array((3,(Some(4),9)), (3,(Some(6),9)))- 1
6、cogroup: 对来自两个RDD的数据按key进行分组。在zeppelin中执行如下代码:
1. val r5 = pairRDD1.cogroup(pairRDD2) 2. r5.collect- 1
- 2
同时按下【shift+enter】,执行以上代码,输出内容如下:
res194: Array[(Int, (Iterable[Int], Iterable[Int]))] = Array((1,(CompactBuffer(2),CompactBuffer())), (3,(CompactBuffer(4, 6),CompactBuffer(9))))- 1
8.7 action操作
所有的传统action操作在pair RDDs上都可以用。除此之外,在pair RDDs上还有一些额外的action可用,以利用数据的key/value性质。
假设有一个pair rdd {(1,2),(3,4),(3,6)}。首先,让我们构造出一个RDD。在zeppelin中执行以下代码:1. // 构造rdd 2. val pairRDD = sc.parallelize(Seq((1,2),(3,4),(3,6))) 3. pairRDD.collect- 1
- 2
- 3
接下来,学习Pair RDD上的各种action操作方法:
1、countByKey()操作:countByKey()函数只能在key-value类型的RDDs上可用。它返回一张带有每个key的计数的(K,Int)对的表。在zeppelin中执行如下代码:1. // countByKey 2. pairRDD.countByKey- 1
- 2
同时按下【shift+enter】,执行以上代码,输出内容如下:
res203: scala.collection.Map[Int,Long] = Map(1 -> 1, 3 -> 2)- 1
2、collectAsMap():将结果返回为Map。在zeppelin中执行如下代码:
1. // collectAsMap 2. pairRDD.collectAsMap- 1
- 2
同时按下【shift+enter】,执行以上代码,输出内容如下:
res206: scala.collection.Map[Int,Int] = Map(1 -> 2, 3 -> 6)- 1
3、lookup()函数:查看指定的元素。在zeppelin中执行如下代码:
1. // lookup(key) 2. pairRDD.lookup(3)- 1
- 2
同时按下【shift+enter】,执行以上代码,输出内容如下:
res209: Seq[Int] = WrappedArray(4, 6)- 1
9. 实验结果及分析:
实验结果运行准确,无误
10. 实验结论:
经过本节实验的学习,通过学习RDD的创建方式,进一步巩固了我们的Spark基础。
11. 总结及心得体会:
RDD支持两种类型的操作:transformations和actions。其中:transformations是操作RDD并返回一个新的RDD,如map()和filter()方法,而actions是返回一个结果给驱动程序或将结果写入存储的操作,并开始一个计算,如count()和first()。
Spark对于transformations和actions的方式很不一样,所以理解我们所执行的操作是哪一种很重要。transformations RDD是延迟计算的,只在action时才真正进行计算。许多转换是作用于元素范围内的,也就是一次作用于一个元素。12、 实验知识测试
1、在RDD中通过key查找数据的方法正确的是©{单选}
A、countByKey()
B、keys()
C、lookup()
D、join()13、实验拓展
1. 假设有以下数据集合。请编写Spark代码,按key求平均值。
- (“panda”,0),(“pink”,3),(“pirate”,3),(“panda”,1),(“pink”,4)

-
相关阅读:
YOLOV5识别成语点选验证码
周报不止是汇报进度,如何用周报轻松提升团队协作效率?
对开源自动化测试平台MeterSphere的使用感触
6.< tag-动态规划和打家劫舍合集(树形DP)>lt.198.打家劫舍 + lt.213. 打家劫舍 II + lt.337. 打家劫舍 III dbc
从开发流程看 PyQt5 入门
ArrayLis集合扩容机制
全民拼购模式是怎么卖货的?营销模式解析
Label 相关论文汇总
判断满二叉树、完全二叉树
【YOLOV5】YOLOV5添加OTA
- 原文地址:https://blog.csdn.net/qq_44807756/article/details/125552417