-
非DBA人员从零到一,MySQL InnoDB数据库调优之路(三)-分区表与分库分表
我发现我在工作中分区场景没有特别的多,更多时候我们会去讨论进行分库分表要怎么分,所以本篇博客我把分区和分库分表合并在一起。
1 分区表
1.1 什么是分区表
MySQL在5.1版本添加了对分区的支持
- CREATE TABLE `PARTITION_TESt` (
- `id` int(32) NOT NULL,
- `year` datetime NOT NULL,
- PRIMARY KEY(`id`,`year`)
- ) partition by range columns(year)
- (PARTITION `1990` VALUES LESS THAN (1990),
- PARTITION `1991` VALUES LESS THAN (1991),
- PARTITION `1992` VALUES LESS THAN (1992)
- );
- insert into t values(1,'1990-01-01'),(2,'1991-01-01');
物理上这个表或索引可能由数十个物理分区组成。每个分区都是独立的对象,可以独自处理,也可以作为一个更大对象的一部分进行处理。

1个.frm文件 但是就访问数据库的应用而言,从逻辑上讲,只有一个表或一个索引
3个.ibd文件 1.2 分区表的执行逻辑
- 分区表的引擎层行为
session A session B T1 begin;
select * from PARTITION_TESt where year='1990-12-25' for update;
T2 insert into PARTITION_TESt values(1,'1990-12-29');
(block)
insert into PARTITION_TESt values(1,'1991-01-02');
(success)
在非分区的情况下在拥有1990-01-01和1991-12-30下上面的执行结果两个insert语句会堵塞,但是在使用分区表后,因为表被分割成两个物理区间,因此只有1990下的insert语句会堵塞。
- 分区表的server行为
session A session B T1 begin;
select * from PARTITION_TESt where year='1990-12-25';
T2 alter table PARTITION_TESt truncate partition 1990
(block)
server 层看的话,一个分区表就只是一个表,所有分区共用同一个 MDL 锁。
1.3 InnoDB数据库分区表的限制
- MySQL 要求分区表中的主键必须包含分区字段
- 分区无法使用外键
- InnoDB Cluster不支持分区表
1.4 InnoDB数据库分区表的缺点
- MySQL 在第一次打开分区表的时候,需要访问所有的分区
分区表不能建立太多的分区,分区表分区过多导致的主从延迟问题
- 在 server 层,认为这是同一张表,因此所有分区共用同一个 MDL 锁,
虽然物理上分有多个ibd组成,但是实际上在做不同分区的DML操作和DDL、DML操作的时候会出现MDL锁
1.5 分区性能就提升?
分区表不是用于提升MySQL的性能,而是在于方便数据管理
通过非DBA人员从零到一,MySQL InnoDB数据库调优之路(一)-建表可知道InnoDB的存储量与B+树高度的关系,虽然使用分区表使我们数据分散到多个物理分区,但是并没有多大的提升,举个例子把三层2000万整表数据分区成2000个2层10000数据的分区表,在访问数据时候也只是减少了1次IO,实际上没有对性能有显著的提升。
2 分库分表
面试的时候面试官经常会问你们有用分库分表吗,首先我认为分库分表不是公司技术发展的必然结果,根据我实际的工作经验来看,使用分库分表会是有以下几种原因导致:
- 性能达到瓶颈
- 业务需要
- 架构需要
2.1 分库
在我实际碰到和了解到的场景会因为内容域的不同形成垂直库拆分和水平库拆分,除此之外读写分离我觉得也是一种特殊类型的分库手法。
- 因为业务需要,整体数据域需要库水平拆分,例如在项目当中有些公司整体业务是一样的,但是分公司之间数据内容相互独立,数据库就需要垂直拆分,每间分公司单独使用一个库。
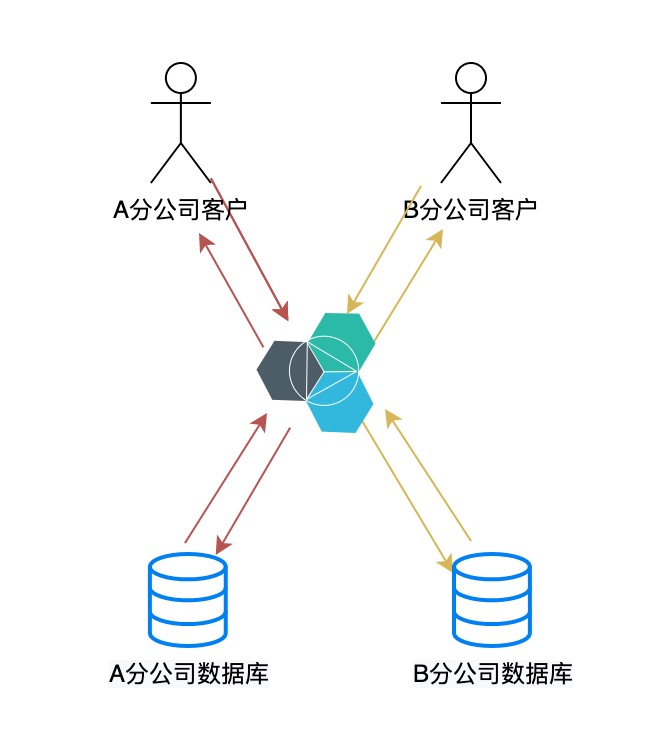
- 因为系统根据业务域进行拆分,不同数据域需要根据业务域库垂直拆分,例如我们微服务拆分的时候,往往也会根据微服务的业务拆分出对应的数据域库。

- 读写分离我们可以把他看作特殊的库水平拆分,拆分出来的库数据最终会完全相同,为了解决单库读写性能瓶颈,读写分离通过写库负责数据变更操作,然后同步到从库当中,而从库只提供查询功能,从而提高系统的数据读取性能。

2.2 分表
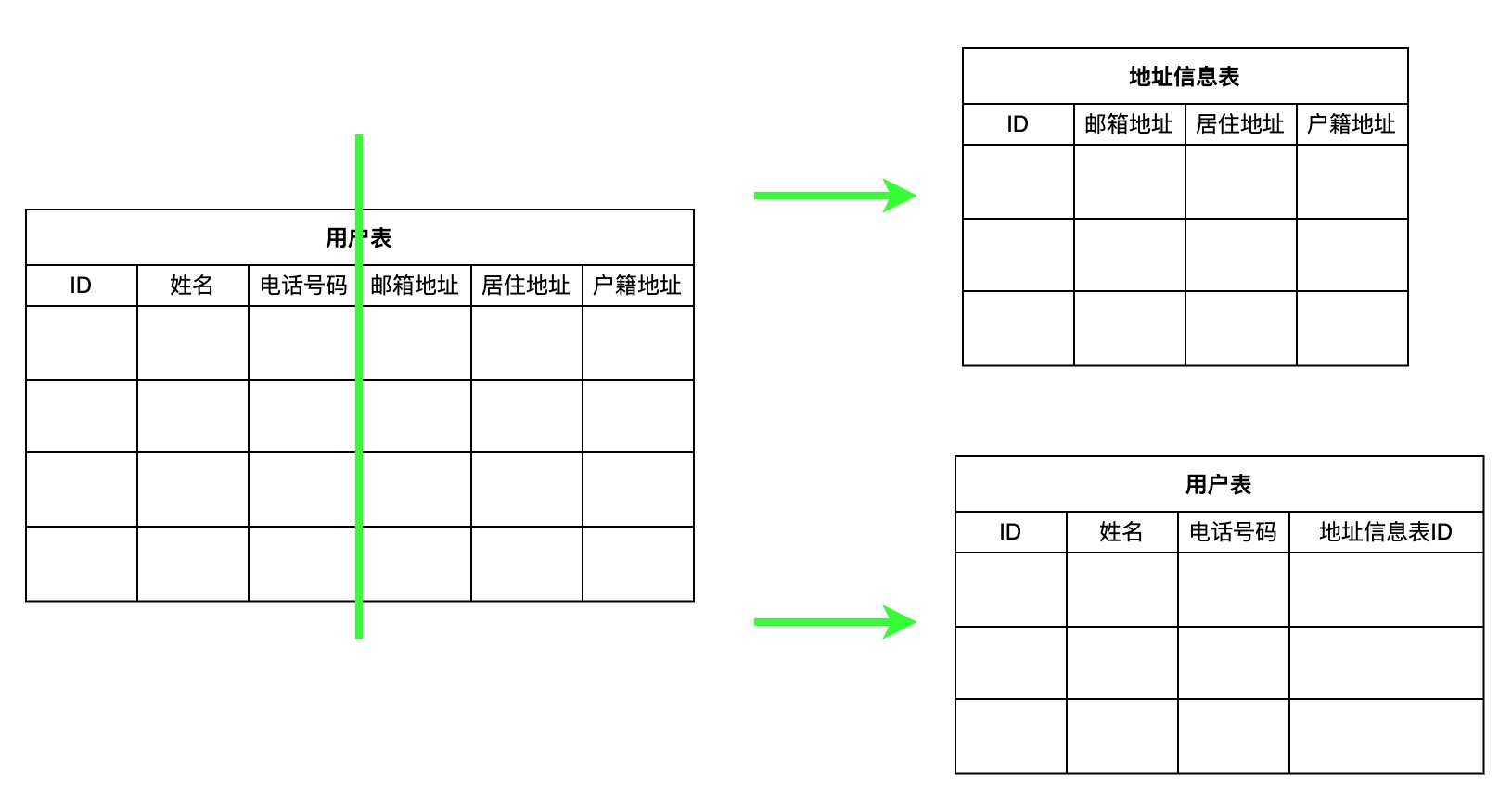
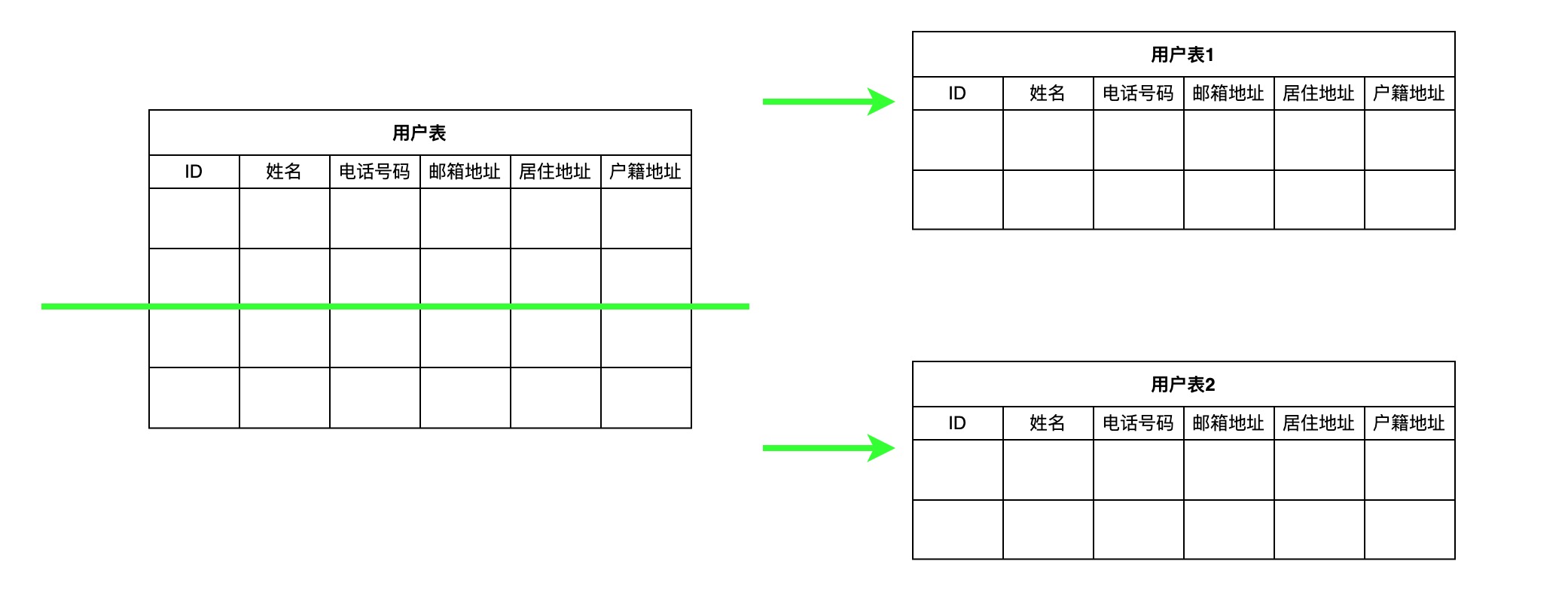
分表的原因就比较好理解,归根究底就是流量和数据量增大,单表容量引起查询负载会陡然增长导致查询需要更多耗时长,因此通过拆分数据表保证单表数据在合适的范围内。分表也分为垂直拆分与水平拆分
- 垂直拆分通过拆分不同列生成两个拥有完全相同行数拥有不同列的表
- 水平分表通过拆分出行数据拆分出列完全相同的表
3 结语
分区表是一个时代的产物,那个时代开源数据库中间件不发达,访问就只能由数据库来进行分区,在发表这篇博文的近几年里,开源的数据库中间件已经非常成熟,如ShardingSphere系列组件它们:
- 分区表通过数据库进行分区。中间件通过proxy或者jdk形式代理路由
- 分区表需要第一次访问所有分区,DDL、DML操作的时候会出现MDL锁。中间件只会根据路由进行数据库访问选择,且各库DDL、DML操作不会相互影响(微观下他们就是一个独立的个体)
分区表始终没有办法突破单表的性能瓶颈,如其长时间对单表数据库参数,服务机硬件升级。不如使用分表在短时间内能看到成效。
对于分表是我对数据库调优中的加法方式,后面我会通过减法来进一步阐述我对数据库调优的理解。
-
相关阅读:
Linux 内核分析 rcu_sched self-detected stall on CPU
# 磁盘引导方式相关知识之BIOS、msdos、MBR、UEFI、gpt、esp、csm
数据结构(C语言)——双链表
Unity URP 渲染管线:URP渲染管线光照机制剖析
Android使用MPAndroidChart 绘制折线图
使用QtWebApp搭建Http服务器
Speedpdf在线转换教你如何XPS转PDF格式
webservice接口测试
02.QMake项目原理和手动配置qtcreator
机器学习笔记03
- 原文地址:https://blog.csdn.net/kiranet/article/details/123940689