-
图像处理8-CNN图像分类
图像处理系列
一、内容
(1)利用Pytorch搭建简单的CNN网络实现图像分类,并测试分类效果(更多步骤可参考https://www.stefanfiott.com/machine-learning/cifar-10-classifier-using-cnn-in-pytorch/);
(2)修改网络模型,进行新的训练,并测试分类效果;
(3)撰写实验报告。
二、使用简单的CNN网络进行图像分类
1.导入包
使用图2.1的代码导入包。
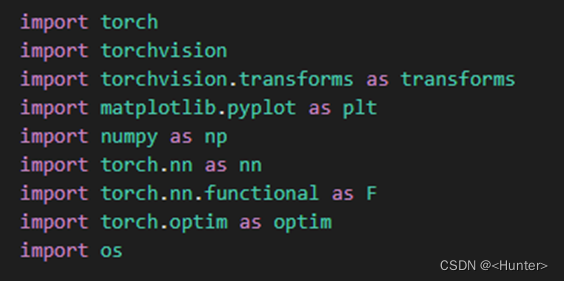
图2.1 导入包
2.数据下载、增强和划分
使用图2.2的代码进行数据下载、增强和划分数据集。

图2.2 数据下载、增强、划分
3.神经网络定义
使用图2.3的代码定义一个简单的CNN神经网络。

图2.3 定义简单的CNN神经网络
4.定义优化器
使用图2.4的代码定义优化器。

图2.4 定义优化器
5.训练和保存神经网络
使用图2.5的代码训练定义的模型,并保存,输出如图2.6。

图2.5 神经网络训练与保存

图2.6 模型训练输出
6.测试神经网络
a.准确率
使用图2.7的代码,计算准去率,最后得到准确率为62.17%。
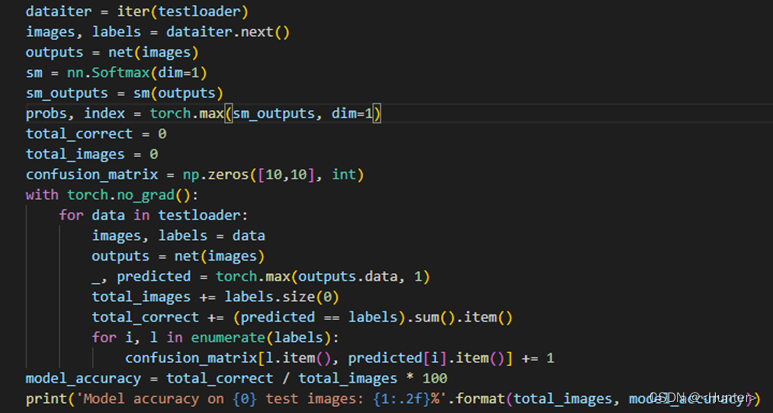
图2.7 计算模型准确率
b.计算每一类的分类准确率
使用图2.8的代码计算每类分类的准确率,结果见图2.9。

图2.8 计算每类分类的准确率

图2.9 每类分类的准确率
c.绘制实际实际类别和预测分类曲线
使用图2.10的代码进行绘制,并输出每个值得大小,如图2.11,曲线如图2.12。
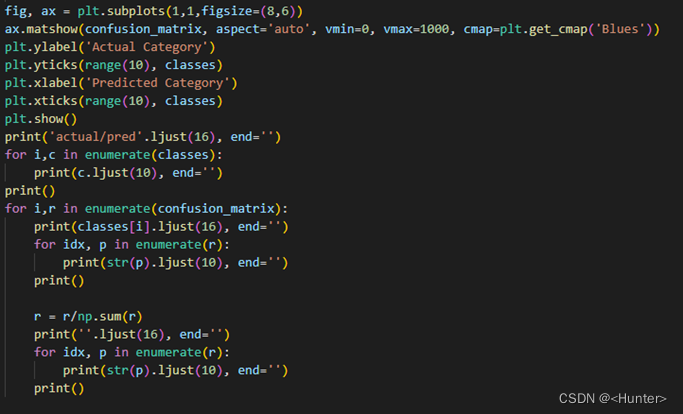
图2.11 绘制实际实际类别和预测分类曲线

图2.12 绘制实际实际类别和预测分类值的大小

图2.13 绘制实际实际类别和预测分类值曲线
三、Geogle Net图片分类
1.导入包
使用图3.1的代码导入包。

图3.1 导入包
2.数据导入、增强和划分
使用图3.2的代码进行参数定义,数据导入、增强和划分。

图3.2 参数定义,数据导入、增强和划分
3.定义网络
使用图3.3的代码进行网络定义。


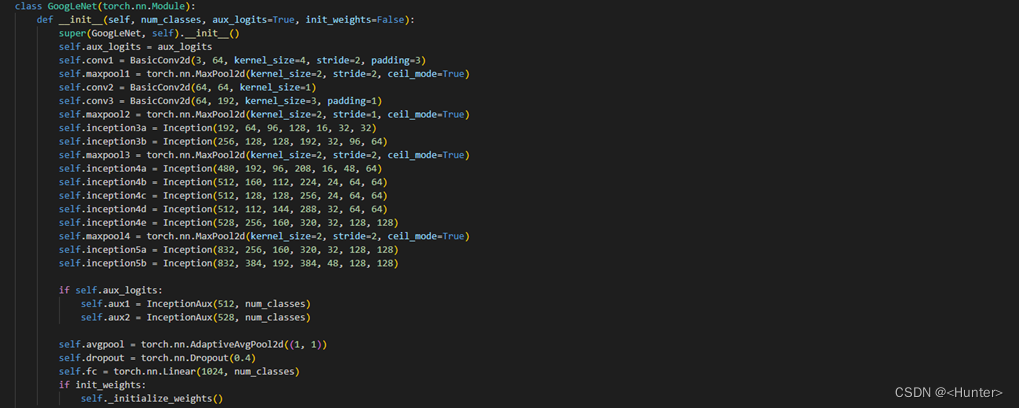


图3.3 网络定义
4.训练网络
使用图3.4的代码进行网络训练,输出如图3.5。

图3.4 网络训练

图3.5 训练输出
5.计算精度
使用图3.6的代码计算精度,精度为80.43%.

图3.6 计算精度
四、总结
使用pytorch,搭建了简单的CNN网络和Geogle Net网络,对Cifar10进行了图像分类,并计算了相应的模型校验参数。
五、源码
1.简单CNN源码
- '''
- 简单CNN图片分类
- '''
- import torch
- import torchvision
- import torchvision.transforms as transforms
- import matplotlib.pyplot as plt
- import numpy as np
- import torch.nn as nn
- import torch.nn.functional as F
- import torch.optim as optim
- import os
- #下载数据并进行数据增强和划分
- transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
- trainset = torchvision.datasets.CIFAR10('./data', train=True,download=True, transform=transform)
- trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,num_workers=4,shuffle=True)
- testset = torchvision.datasets.CIFAR10('./data', train=False,download=True, transform=transform)
- testloader = torch.utils.data.DataLoader(testset, batch_size=4,num_workers=4,shuffle=False)
- classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
- dataiter = iter(trainloader)
- images, labels = dataiter.next()
- #定义网络结构
- class Net(nn.Module):
- def __init__(self):
- super(Net, self).__init__()
- self.conv1 = nn.Conv2d(3, 6, 5)
- self.pool = nn.MaxPool2d(2, 2)
- self.conv2 = nn.Conv2d(6, 16, 5)
- self.fc1 = nn.Linear(16 * 5 * 5, 120)
- self.fc2 = nn.Linear(120, 84)
- self.fc3 = nn.Linear(84, 10)
- def forward(self, x):
- x = self.pool(F.relu(self.conv1(x)))
- x = self.pool(F.relu(self.conv2(x)))
- x = x.view(-1, 16 * 5 * 5)
- x = F.relu(self.fc1(x))
- x = F.relu(self.fc2(x))
- x = self.fc3(x)
- return x
- net = Net()
- #定义优化器
- criterion = nn.CrossEntropyLoss()
- optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
- #训练网络
- model_directory_path = './model、'
- model_path = model_directory_path + 'cifar-10-cnn-model-oralcnn.pt'
- if not os.path.exists(model_directory_path):
- os.makedirs(model_directory_path)
- if os.path.isfile(model_path):
- # load trained model parameters from disk
- net.load_state_dict(torch.load(model_path))
- print('Loaded model parameters from disk.')
- else:
- for epoch in range(10): # loop over the dataset multiple times
- running_loss = 0.0
- for i, data in enumerate(trainloader, 0):
- # get the inputs
- inputs, labels = data
- # zero the parameter gradients
- optimizer.zero_grad()
- # forward + backward + optimize
- outputs = net(inputs)
- loss = criterion(outputs, labels)
- loss.backward()
- optimizer.step()
- # print statistics
- running_loss += loss.item()
- if i % 2000 == 1999: # print every 2000 mini-batches
- print('[%d, %5d] loss: %.3f' %
- (epoch + 1, i + 1, running_loss / 2000))
- running_loss = 0.0
- print('Finished Training.')
- torch.save(net.state_dict(), model_path)
- print('Saved model parameters to disk.')
- #网络测试
- dataiter = iter(testloader)
- images, labels = dataiter.next()
- outputs = net(images)
- sm = nn.Softmax(dim=1)
- sm_outputs = sm(outputs)
- probs, index = torch.max(sm_outputs, dim=1)
- total_correct = 0
- total_images = 0
- confusion_matrix = np.zeros([10,10], int)
- with torch.no_grad():
- for data in testloader:
- images, labels = data
- outputs = net(images)
- _, predicted = torch.max(outputs.data, 1)
- total_images += labels.size(0)
- total_correct += (predicted == labels).sum().item()
- for i, l in enumerate(labels):
- confusion_matrix[l.item(), predicted[i].item()] += 1
- model_accuracy = total_correct / total_images * 100
- print('Model accuracy on {0} test images: {1:.2f}%'.format(total_images, model_accuracy))
- print('{0:10s} - {1}'.format('Category','Accuracy'))
- for i, r in enumerate(confusion_matrix):
- print('{0:10s} - {1:.1f}'.format(classes[i], r[i]/np.sum(r)*100))
- fig, ax = plt.subplots(1,1,figsize=(8,6))
- ax.matshow(confusion_matrix, aspect='auto', vmin=0, vmax=1000, cmap=plt.get_cmap('Blues'))
- plt.ylabel('Actual Category')
- plt.yticks(range(10), classes)
- plt.xlabel('Predicted Category')
- plt.xticks(range(10), classes)
- plt.show()
- print('actual/pred'.ljust(16), end='')
- for i,c in enumerate(classes):
- print(c.ljust(10), end='')
- print()
- for i,r in enumerate(confusion_matrix):
- print(classes[i].ljust(16), end='')
- for idx, p in enumerate(r):
- print(str(p).ljust(10), end='')
- print()
- r = r/np.sum(r)
- print(''.ljust(16), end='')
- for idx, p in enumerate(r):
- print(str(p).ljust(10), end='')
- print()
2.Geogle Net
- '''
- geoglenet图片分类
- '''
- import torch
- import torchvision
- import torchvision.transforms as transforms
- import matplotlib.pyplot as plt
- import numpy as np
- import torch.nn as nn
- import torch.nn.functional as F
- import torch.optim as optim
- import os
- import gc
- ##定义参数
- num_epochs = 40
- batch_size = 100
- num_classes = 10
- learning_rate = 0.0006
- device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- #下载数据并进行数据增强和划分
- transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
- train_dataset = torchvision.datasets.CIFAR10('./data', download=False, train=True, transform=transform)
- test_dataset = torchvision.datasets.CIFAR10('./data', download=False, train=False, transform=transform)
- train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
- test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
- classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
- dataiter = iter(train_loader)
- images, labels = dataiter.next()
- #定义网络
- class BasicConv2d(torch.nn.Module):
- def __init__(self, in_channels, out_channels, **kwargs):
- super(BasicConv2d, self).__init__()
- self.conv = torch.nn.Conv2d(in_channels, out_channels, **kwargs)
- self.batchnorm = torch.nn.BatchNorm2d(out_channels)
- self.relu = torch.nn.ReLU(inplace=True)
- def forward(self, x):
- x = self.conv(x)
- x = self.batchnorm(x)
- x = self.relu(x)
- return x
- # Define InceptionAux.
- class InceptionAux(torch.nn.Module):
- def __init__(self, in_channels, num_classes):
- super(InceptionAux, self).__init__()
- self.avgpool = torch.nn.AvgPool2d(kernel_size=2, stride=2)
- self.conv = BasicConv2d(in_channels, 128, kernel_size=1)
- self.fc1 = torch.nn.Sequential(torch.nn.Linear(2 * 2 * 128, 256))
- self.fc2 = torch.nn.Linear(256, num_classes)
- def forward(self, x):
- out = self.avgpool(x)
- out = self.conv(out)
- out = out.view(out.size(0), -1)
- out = torch.nn.functional.dropout(out, 0.5, training=self.training)
- out = torch.nn.functional.relu(self.fc1(out), inplace=True)
- out = torch.nn.functional.dropout(out, 0.5, training=self.training)
- out = self.fc2(out)
- return out
- class Inception(torch.nn.Module):
- def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
- super(Inception, self).__init__()
- self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
- self.branch2 = torch.nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1),
- BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1))
- self.branch3 = torch.nn.Sequential(BasicConv2d(in_channels, ch5x5red, kernel_size=1),
- BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2))
- self.branch4 = torch.nn.Sequential(torch.nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
- BasicConv2d(in_channels, pool_proj, kernel_size=1))
- def forward(self, x):
- branch1 = self.branch1(x)
- branch2 = self.branch2(x)
- branch3 = self.branch3(x)
- branch4 = self.branch4(x)
- outputs = [branch1, branch2, branch3, branch4]
- return torch.cat(outputs, 1)
- # Define GooLeNet.
- class GoogLeNet(torch.nn.Module):
- def __init__(self, num_classes, aux_logits=True, init_weights=False):
- super(GoogLeNet, self).__init__()
- self.aux_logits = aux_logits
- self.conv1 = BasicConv2d(3, 64, kernel_size=4, stride=2, padding=3)
- self.maxpool1 = torch.nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)
- self.conv2 = BasicConv2d(64, 64, kernel_size=1)
- self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
- self.maxpool2 = torch.nn.MaxPool2d(kernel_size=2, stride=1, ceil_mode=True)
- self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
- self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
- self.maxpool3 = torch.nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)
- self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
- self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
- self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
- self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
- self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
- self.maxpool4 = torch.nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)
- self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
- self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
- if self.aux_logits:
- self.aux1 = InceptionAux(512, num_classes)
- self.aux2 = InceptionAux(528, num_classes)
- self.avgpool = torch.nn.AdaptiveAvgPool2d((1, 1))
- self.dropout = torch.nn.Dropout(0.4)
- self.fc = torch.nn.Linear(1024, num_classes)
- if init_weights:
- self._initialize_weights()
- def forward(self, x):
- x = self.conv1(x)
- x = self.maxpool1(x)
- x = self.conv2(x)
- x = self.conv3(x)
- x = self.maxpool2(x)
- x = self.inception3a(x)
- x = self.inception3b(x)
- x = self.maxpool3(x)
- x = self.inception4a(x)
- if self.training and self.aux_logits: # eval model lose this layer
- aux1 = self.aux1(x)
- x = self.inception4b(x)
- x = self.inception4c(x)
- x = self.inception4d(x)
- if self.training and self.aux_logits: # eval model lose this layer
- aux2 = self.aux2(x)
- x = self.inception4e(x)
- x = self.maxpool4(x)
- x = self.inception5a(x)
- x = self.inception5b(x)
- x = self.avgpool(x)
- x = torch.flatten(x, 1)
- x = self.dropout(x)
- x = self.fc(x)
- if self.training and self.aux_logits: # eval model lose this layer
- return x, aux2, aux1
- return x
- def _initialize_weights(self):
- for m in self.modules():
- if isinstance(m, torch.nn.Conv2d):
- torch.nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
- if m.bias is not None:
- torch.nn.init.constant_(m.bias, 0)
- elif isinstance(m, torch.nn.Linear):
- torch.nn.init.normal_(m.weight, 0, 0.01)
- torch.nn.init.constant_(m.bias, 0)
- net = GoogLeNet(10, False, True).to(device)
- criterion = nn.CrossEntropyLoss()
- optimizer = torch.optim.Adam(net.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
- def update_lr(optimizer, lr):
- for param_group in optimizer.param_groups:
- param_group['lr'] = lr
- #训练网络
- total_step = len(train_loader)
- curr_lr = learning_rate
- for epoch in range(num_epochs):
- gc.collect()
- torch.cuda.empty_cache()
- net.train()
- for i, (images, labels) in enumerate(train_loader):
- images = images.to(device)
- labels = labels.to(device)
- outputs = net(images)
- loss = criterion(outputs, labels)
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
- if (i+1) % 100 == 0:
- print ('Epoch [{}/{}], Step [{}/{}], Loss {:.4f}'.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
- if (epoch+1) % 20 == 0:
- curr_lr /= 3
- update_lr(optimizer, curr_lr)
- torch.save(net.state_dict(), './model/cifar-10-cnn-geoglenet.pt')
- #计算精度
- net.eval()
- with torch.no_grad():
- correct = 0
- total = 0
- for images, labels in test_loader:
- images = images.to(device)
- labels = labels.to(device)
- outputs = net(images)
- _, predicted = torch.max(outputs.data, 1)
- total += labels.size(0)
- correct += (predicted == labels).sum().item()
- print('Accuracy of the model on the test images: {} %'.format(100 * correct / total))
-
相关阅读:
“一万字”动静图生动结合详解:快速排序
醋氯芬酸小鼠血清白蛋白纳米粒Aceclofenac-MSA|利凡诺大鼠血清白蛋白纳米粒Ethacridine-RSA
【AGC】集成华为AGC崩溃服务实用教程
教你如何搭建一个大学生查题公众号
Java日志门面框架--SLF4J
常用adb 命令
bootstrap-datepicker实现只能选择每一年的某一个月份
R语言中的prophet预测时间序列数据模型
架构的未来——End
zabbix监控安装-linux
- 原文地址:https://blog.csdn.net/Hunter_xiaotan/article/details/125541178
