-
Python爬虫入门基础学习(四)
大家好,我是卷心菜。因为项目的需要,最近在学习Python的爬虫。这一篇是关于Python的基础知识点,也是学习爬虫的入门知识点!如果您看完文章有所收获,可以三连支持博主哦~,嘻嘻。
一、前言
- 前面用四篇文章讲解了Python爬虫需要的基础,
- Python爬虫入门基础学习(一)
- Python爬虫入门基础学习(二)
- Python爬虫入门基础学习(三)
- Python爬虫入门学习:拿捏高级数据类型
- 这一篇是最后一篇基础文章!主要讲解Python中函数的使用、文件的操作以及异常的简单了解,干货满满~
二、函数
- 有过编程基础的小伙伴们都知道,函数在编程中是非常重要的,所以今天就来看看Python中的函数如何定义与使用规则
1、函数定义
- 定义函数的格式如下:

代码举例实践:
def sayHello(): print('Hello') print('World')- 1
- 2
- 3
2、函数调用
- 定义了函数之后,就相当于有了一个具有某些功能的代码,想让这些代码能够执行,必须要调用它们。
调用上述的代码:
sayHello()- 1
运行结果:

函数定义好以后,函数体里的代码并不会执行,如果想要执行函数体里的内容,需要手动的调用函数。 每次调用函数时,函数都会从头开始执行,当这个函数中的代码执行完毕后,意味着调用结束了。
3、函数参数
- 学习了函数调用,接下来学习函数的参数。为什么函数要有参数?思考一下,假如让你设计一个函数实现两数相加的功能,该如何实现呢?这里就用到了函数的参数。
设计代码实现两数相加并打印:
# 现在需要定义一个函数,这个函数能够完成2个数的加法运算,并且把结果打印出来 def add(num1, num2): print(num1 + num2)- 1
- 2
- 3
需要注意的是:
- 在定义函数的时候,小括号里写等待赋值的变量名
- 在调用函数的时候,小括号里写真正要进行运算的数据
- 注意一下调用函数时参数的顺序
def function(a, b): print('a = %d, b = %d' % (a, b)) function(1, 2) # 位置参数 function(b=1, a=2) # 关键字参数- 1
- 2
- 3
- 4
运行结果:

4、函数返回值
- 在计算两数之和时,我们大多数希望可以得到一个值,而不是直接打印在控制台,这里就需要用到函数的返回值
- 想要在函数中把结果返回给调用者,需要在函数中使用return
# return的使用 def fun(num1, num2): return (num1 + num2) # 接收结果给sum sum = fun(3, 5) print(sum) # 8- 1
- 2
- 3
- 4
- 5
- 6
5、局部变量
- 什么是局部变量?就是在
函数内部定义的变量 - 局部变量的作用范围是函数的内部,即只能在这个函数中使用,在函数的外部是不能使用的

6、全局变量
- 什么是全局变量?如果一个变量,既能在一个函数中使用,也能在其他的函数中使用,这样的变量就是全局变量
在函数外边定义的变量叫做全局变量- 全局变量能够在所有的函数中进行访问

三、文件
- 值得高兴的是,文件学习完,就代表着Python爬虫入门基础已经接近了末尾,Python的文件也是非常的重要,认真学起来!
1、文件打开与关闭
- 文件的打开与关闭在Python中非常的简单,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件
代码举例实践:
# open(文件路径,访问模式) fp = open('python.txt','w') fp.close()- 1
- 2
- 3
文件路径
访问模式,简单了解一下,在实际使用到后再做详细说明
访问模式 说明 r 以只读方式打开文件。文件的指针将会放在文件的开头。如果文件不存在,则报错。这是默认模式 w 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件 a 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将 会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入 r+ 打开一个文件用于读写。文件指针将会放在文件的开头 w+ 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件 a+ 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模 式。如果该文件不存在,创建新文件用于读写 rb 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头 wb 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新 文件 ab 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是 说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入 rb+ 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头 wb+ 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文 件 ab+ 以二进制格式打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。如果该文 件不存在,创建新文件用于读写 2、文件读写
写数据(write)
fp = open('python.txt','w') fp.write('Welcome to China\n' * 5) fp.close()- 1
- 2
- 3
这样,代码运行后就会在python.txt中写入五行’Welcome to China’

注意:如果文件不存在,就创建;如果存在就先清空数据,然后写入数据
读数据(read)- 使用
read(num)可以从文件中读取数据,num表示要从文件中读取的数据的长度(单位是字节),如果没有传入 num,那么就表示读取文件中所有的数据
fp = open('python.txt', 'r') # 先读7个字节 content = fp.read(7) print(content) # 读完剩余的字节 print(fp.read()) fp.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
运行结果:

读数据(readline)
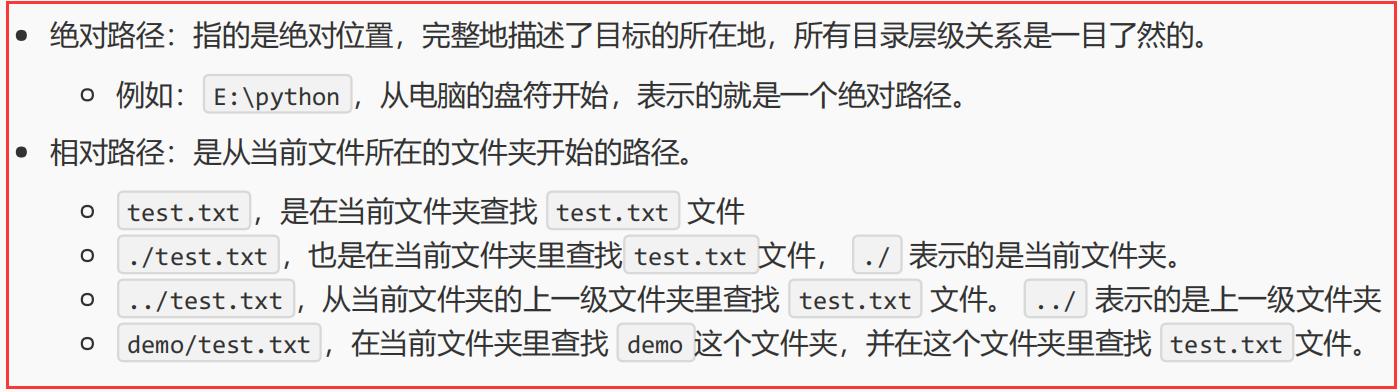
fp = open('python.txt', 'r') content = fp.readline() print(content) print(fp.readline()) fp.close()- 1
- 2
- 3
- 4
- 5
运行结果:
读数据(readlines),readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行为列表的一个元素
fp = open('python.txt', 'r') content = fp.readlines() print(content) print(type(content)) for item in content: print(item) fp.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
运行结果:

3、序列化与反序列化
为什么要有序列化和反序列化?通过文件操作,我们可以将字符串写入到一个本地文件。但是,如果是一个对象(例如列表、字典、元组等),就无法直接写入到一个文件里,需要对这个对象进行序列化,然后才能写入到文件里什么是序列化和反序列化?设计一套协议,按照某种规则,把内存中的数据转换为字节序列,保存到文件,这就是序列化,反之,从文件的字节序列恢复到内存中,就是反序列化- 对象 --> 字节序列 就是序列化
- 字节序列 --> 对象 就是反序列化
- Python中提供了JSON这个模块用来实现数据的序列化和反序列化
1、序列化
dumps方法,作用是把对象转换成为字符串,它本身不具备将数据写入到文件的功能
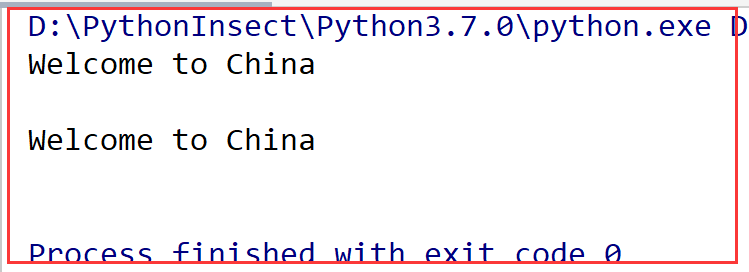
import json file = open('python.txt', 'w') list = ['love', 'China', 'Morning'] # 报错:TypeError: write() argument must be str, not list # file.write(list) # dumps方法得到的结果是一个字符串 result = json.dumps(list) print(type(result)) # <class 'str'> # 可以将字符串写入到文件里 file.write(result) file.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
运行结果:
dump方法,可以在将对象转换成为字符串的同时,指定一个文件对象,把转换后的字符串写入到这个文件里
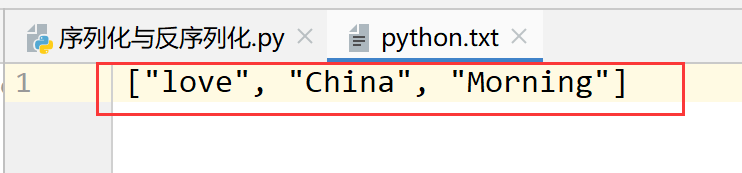
import json file = open('python.txt', 'w') list = ['love', 'China', 'Morning', 'CSY'] json.dump(list,file) file.close()- 1
- 2
- 3
- 4
- 5
2、反序列化
- 使用
loads和load方法,可以将一个JSON字符串反序列化成为一个Python对象 - loads方法需要一个字符串参数,用来将一个字符串加载成为Python对象
- load方法可以传入一个文件对象,用来将一个文件对象里的数据加载成为Python对象


四、异常
- 因为学习的是Python爬虫,这里就简单介绍异常的基本使用
语法结构:

代码举例实践:
try: f = open('test.txt', 'r') print(f.read()) except FileNotFoundError: print('文件没有找到,请检查文件名称是否正确')- 1
- 2
- 3
- 4
- 5
感谢阅读,一起进步,嘻嘻~ -
相关阅读:
docker swarm安装指导
【卫朋】硬件创业:营销与开发同行
whisper使用方法
Flutter(十) 音频+视频播放
多路转接(使用poll实现)
Android网络通讯之Retrofit
Power BI前端设计:深度探索与实战技巧
SpringBoot+百度地图+Mysql实现中国地图可视化
vue 在beforeRouteEnter中获取 this 和操作 data 中的数据
用uniapp开发打包多端应用完整指南
- 原文地址:https://blog.csdn.net/weixin_59654772/article/details/125532994