论文信息
论文标题:Attributed Graph Clustering via Adaptive Graph Convolution
论文作者:Xiaotong Zhang, Han Liu, Qimai Li, Xiao-Ming Wu
论文来源:2019, IJCAI
论文地址:download
论文代码:download
1 Introduction
关于GNN 是低通滤波器的好文。
2 Method
2.1 Graph Convolution
2.1.1 Basic idea
为正式定义图卷积,首先引入图信号和图滤波器的概念。
图信号可以表示为一个向量 f=[f(v1),⋯,f(vn)]⊤,其中 f:V→R 是一个实值函数。
-
- 邻接矩阵 A
- 度矩阵 D=diag(d1,⋯,dn)
- 对称标准化图拉普拉斯矩阵 Ls=I−D−12AD−12
Ls 可特征分解:Ls=UΛU−1,其中 Λ=diag(λ1,⋯,λn) 是按特征值升序的对角矩阵,U=[u1,⋯,un] 是对应的正交特征向量。
图滤波器 可表示为 G=Up(Λ)U−1∈Rn×n,其中 p(Λ)=diag(p(λ1),⋯,p(λn)) 被称为 频率响应函数。
图卷积 被定义为 图信号 与 图滤波器 G 的乘法:
¯f=Gf(1)
其中,¯f 为滤波后的图信号。
特征矩阵 X 的 每一列 可看作是一个图信号。在图信号处理中,特征值 (λq)1≤q≤n 可以作为 频率,相关的特征向量 (uq)1≤q≤n 可以作为图的傅里叶基。一个图信号 f 可以被分解为一个特征向量的线性组合,即,
f=Uz=n∑q=1zquq(2)
式中,z=[z1,⋯,zn]⊤ 和 zq 为 uq 的系数。系数 |zq| 的大小表示 f 中表示的基信号 uq 的强度。
如果图上附近的节点具有相似的特征表示,则图信号是平滑的。基信号 uq 的平滑度可以用 拉普拉斯-贝尔特拉米算子 Ω(⋅) 来测量,即,
Ω(uq)=12∑(vi,vj)∈Eaij‖uq(i)√di−uq(j)√dj‖22=u⊤qLsuq=λq(3)
其中,uq(i) 表示向量 uq 的第 i 个元素。
Eq.3 表示与较低频(较小特征值)相关的基信号更平滑,即平滑的图信号 f 应该比高频图信号包含更多的低频基信号。这可通过与低通图滤波器 G 进行图卷积来实现,如下所示。
通过 Eq.2,图卷积可以写成
¯f=Gf=Up(Λ)U−1⋅Uz=n∑q=1p(λq)zquq(4)
在滤波后的信号 ¯f 中,基信号 uq 的系数 zq 按 p(λq) 进行缩放。为保持低频基信号和去除 f 中的高频信号,图滤波器 G 应该是低通的,即 频率响应函数 p(⋅) 应该是 减小 的和 非负 的。
低通图滤波器可以有多种形式。在这里,本文设计了一个具有频率响应函数的低通图滤波器
p(λq)=1−12λq(5)
如 Figure 1(a) 中的红线所示,可以看到 Eq.5 中的 p(⋅) 在 [0,2] 上呈递减趋势,且为非负值。
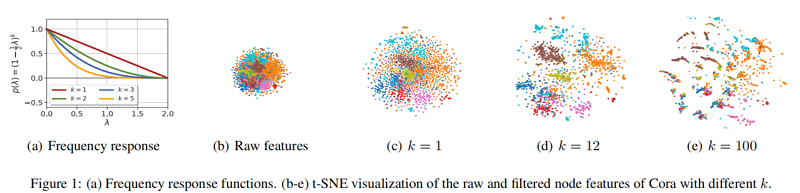
注意,对称归一化图拉普拉斯l的所有特征值 λq 都属于区间 [0,2],这表明 Eq.5 中的 p(⋅) 是低通的。在 Eq.5 中以 p(⋅) 为频率响应函数的图滤波器 G 可以写成
G=Up(Λ)U−1=U(I−12Λ)U−1=I−12Ls(6)
ˉX=GX(7)
其中,ˉX=[¯x1,¯x2,⋯,¯xn]⊤∈Rn×d 是图卷积后过滤后的节点特征。在特征矩阵上应用这样种低通图滤波器,使相邻节点在每个维上具有相似的特征值,即图信号是平滑的。
请注意,在 Eq.6 中提出的图滤波器不同于在 GCN 中使用的图滤波器。GCN 中的图滤波器是 G=I−Ls,频率响应函数 p(λq)=1−λq,这显然不是低通,因为它在 λq∈(1,2] 为负。
GCN 的滤波器
˜D−1/2˜A˜D−1/2=˜D−1/2(˜D−L)˜D−1/2=I−˜D−1/2L˜D−1/2=I−˜Ls
由于 ˜Ls 可以被正交对角化,设 ˜Ls=V˜ΛVT , ˜λi 是 ˜Ls 的特征值,可以证明 ˜λi∈[0,2)。
因此上式变为:I−V˜ΛVT=V(1−˜Λ)VT
显然,其频率响应函数为 p(λ)=1−˜λi∈[−1,1) 。
2.1.2 k-Order Graph Convolution
为了便于聚类,希望同一类的节点在经过图过滤后应该具有相似的特征表示。然而,Eq.7 中的一阶图卷积可能不足以实现这一点,特别是对于大型稀疏图,因为它只通过一个节点的聚合来更新每个节点 vi,而不考虑长距离邻域关系。为了捕获全局图的结构并便于聚类,建议使用 k 阶图的卷积。
ˉX=(I−12Ls)kX(8)
其中 k 为正整数,对应的图滤波器为
G=(I−12Ls)k=U(I−12Λ)kU−1(9)
在 Eq.9 中,G 的频率响应函数为
p(λq)=(1−12λq)k(10)
如 Figure 1(a) 所示,随着 k 的增加,Eq.10 中的 p(λq) 变得更低通,说明滤波后的节点特征 ˉX 将更平滑。
k 阶图卷积的迭代计算公式为
¯x(0)i=xi¯x(1)i=12(¯x(0)i+∑(vi,vj)∈Eaij√didj¯x(0)j)⋮¯x(k)i=12(¯x(k−1)i+∑(vi,vj)∈Eaij√didj¯x(k−1)j)(11)
最终的 ¯xi 是 ¯x(k)i。
Note因为:
ˉX=(I−12Ls)X=12(I+D−12AD−12)X
所以:
¯xi=12(xi+∑(vi,vj)∈eaij√didjxj)
随着 k 增加,k 阶图卷积将使节点特征在每个维度上更平滑。下面,我们使用 Eq.3 中定义的拉普拉斯-贝尔特拉米算子 Ω(⋅) 来证明这一点。用 f 表示特征矩阵 X 的一列,可以分解为 f=Uz。请注意, Ω(βf)=β2Ω(f),其中 β 是一个标量。因此,为了比较不同的图信号的平滑性,我们需要把它们放在一个共同的尺度上。接下来,我们考虑一个归一化信号 f‖f‖2 的平滑性,即,
Ω(f‖f‖2)=f⊤Lsf‖f‖22=z⊤Λz‖z‖22=n∑i=1λiz2in∑i=1z2i(12)
证明:

我们现在可以用这个引理来证明 Theorem 1。为方便起见,我们将 Ls 的特征值 λi 按递增顺序排列为 0≤λ1≤⋯≤λn。由于 p(λ) 是非增加的和非负的,所以 p(λ1)≥⋯≥p(λn)≥0。可以用上述引理来证明Theorem 1 ,通过设置 :
Ti=λi,bi=z2i,ci=p2(λi)z2i(16)
假设 f 和 ¯f 分别由 (k−1) 阶和 k 阶图卷积得到,我们可以立即从 Theorem 1 中推断出 ¯f 比 f 更平滑。换句话说,k 阶图卷积会随着 k 的增加而产生更平滑的特征。由于同一集群中的节点倾向于紧密连接,它们可能具有更多具有大 k 的相似特征表示,这有利于聚类。
2.2 Clustering via Adaptive Graph Convolution
算法如下:

为了自适应地选择 k 阶,我们使用聚类性能度量-仅基于数据的内在信息的内部标准。在这里,我们考虑 intra-cluster distance(对于给定的簇 C),它表示 C 的紧致性:
intra(C)=1|C|∑C∈C1|C|(|C|−1)∑vi,vj∈C,vi≠vj‖ˉxi−ˉxj‖2
需要注意的是,在具有固定数据特征的情况下,簇间距离也可以用来度量聚类性能,良好的簇类划分应该具有较大的簇间距离和较小的簇内距离。然而,根据 Theorem 1,随着 k 的增加,节点特征变得更平滑,这可以显著减少簇内和簇间的距离。因此,簇间的距离可能不是衡量集群性能的可靠度量指标因此,我们建议观察选择 k 的簇内距离的变化。
所以,最后的选择簇分配为 C(t−1)。这种选择策略的好处是有两方面的。首先,它确保为 intra (C) 找到一个局部最小值,这可能表明一个良好的簇分配,并避免过度平滑。其次,停止在 intra (C) 内的第一个局部最小值是时间有效的。
3 Experiments
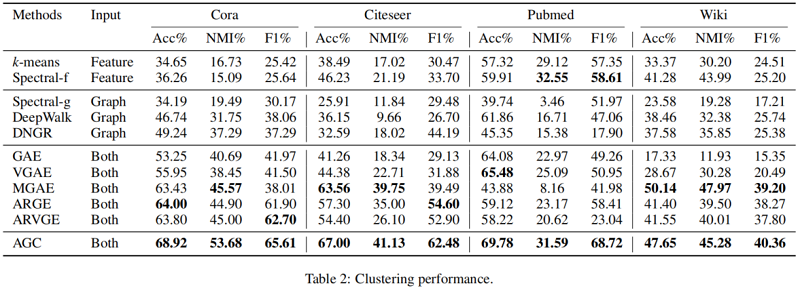
节点聚类
4 Conclusion
本文提出了一种简单而有效的属性图聚类方法。为了更好地利用可用数据和捕获全局集群结构,我们设计了一个k阶图卷积来聚合远程数据信息。为了优化不同图上的聚类性能,我们设计了一种自适应选择合适的k的策略。这使得我们的方法能够达到与经典的和最先进的方法相比的竞争性能。在未来的工作中,我们计划改进自适应选择策略,使我们的方法更加鲁棒和高效。
修改历史
2022-06-30 创建文章
__EOF__
