-
JVM内存管理及垃圾回收机制
JVM 的内存划分
JVM从操作系统申请到内存,然后将其划分为以下区域
- 程序计数器
- 用来保存下一条要执行的指令在哪
- 当一个程序想要运行,JVM就得把指令(字节码)加载到内存中,然后程序从内存中一条条取出指令,放到CPU上执行
- 我们知道CPU是并行加并发执行的,当CPU执行了一段时间别的进程指令后,再回来接着执行该进程,就需要知道该进程目前执行到哪里了,程序计数器就能记录。(每个线程都有一个程序计数器)
- 栈
- 用来存放 局部变量 和 方法调用信息
- 每次调用一个方法,该方法就会入栈,每一个方法执行完,该方法就会出栈

- 栈中存放每个方法的信息就叫做 栈帧 ,遵循先进后出的原则
- 站空间比较小,如果递归次数多,条件没写好,很有可能就会栈溢出
- 每个线程就有一个单独的栈空间
- 堆
- 成员变量、new出来的对象都是在堆中
- 每个进程只有一份,多个线程共用一份
- 方法区
- 方法区放的就是 类对象 ,类对象就描述了一个类长什么样(里面的成员、方法、成员类型、方法类型、方法里的指令…)
类加载的过程
- 类加载: 把.class文件加载到内存中,然后被JVM构造成类对象
- 类加载的过程
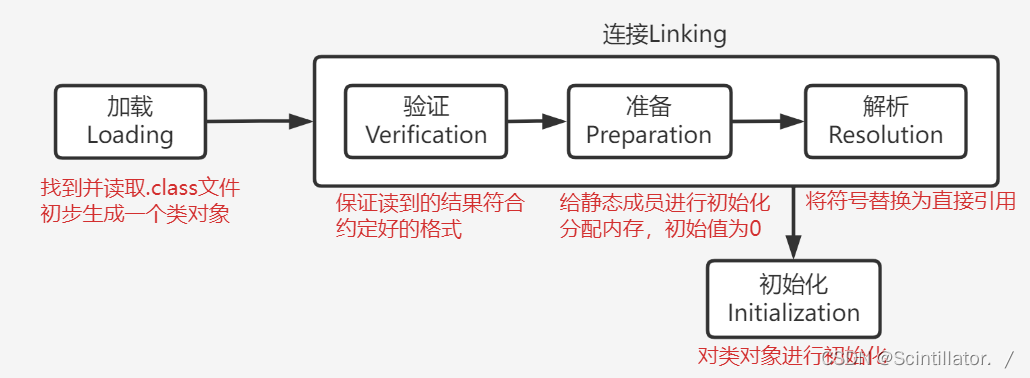
- 类加载的过程
- 双亲委派模型: JVM中的类加载器找 .class文件的过程
- 默认的类加载器有以下3个
- BootStrapClassLoader: 负责加载标准库中的类(String、ArrayList…)
- ExtensionClassLoader:负责加载JDK扩展的类
- ApplicationClassLoader:负责加载自己项目中的类(自己自定义的类)
-
加载java.lang.String的过程
a. 程序启动,进入ApplicationClassLoader
b. ApplicationClassLoader 检查他的父类加载器是否加载过了,没有则先加载
c. ExtensionClassLoader 检查他的父类加载器是否加载过了,没有则先加载
d. BootStrapClassLoader发现没有父类加载器,就自己扫描自己的目录,找到java.lang.String这个类,直接由BootStrapClassLoader负责后续的加载过程,查找环节结束
-
加载自定义的类 Animal
a. 程序启动,进入ApplicationClassLoader
b. ApplicationClassLoader 检查他的父类加载器是否加载过了,没有则先加载
c. ExtensionClassLoader 检查他的父类加载器是否加载过了,没有则先加载
d. BootStrapClassLoader发现没有父类加载器,就自己扫描自己的目录,未找到,则回到子类加载器
e. ExtensionClassLoader 扫描自己的目录,未找到,则回到子类加载器
f. ApplicationClassLoader 扫描自己的目录,找到该类,直接由其负责后续的加载过程,查找环节结束(如果也没找到,则会抛出类找不到的异常)

JVM中的垃圾回收机制(GC)
垃圾回收主要是回收的是 堆 上的实例对象
- 垃圾回收的基本单位是 对象
垃圾的判定:
- 基于引用计数

当此处的引用计数为0时,就认为该对象是垃圾。
void func(){ Test t = new Test(); Test t2 = t; }- 1
- 2
- 3
- 4
当该方法执行完毕后,t 和 t2 跟着栈帧一起释放,对应的引用实例对象的引用计数就 -1
缺点:
- 空间利用率低,每次创建一个对象都需要搭配一个计数器
- 会有 循环引用的问题

假设再加上 a1.a = a2; a2.a = a1;
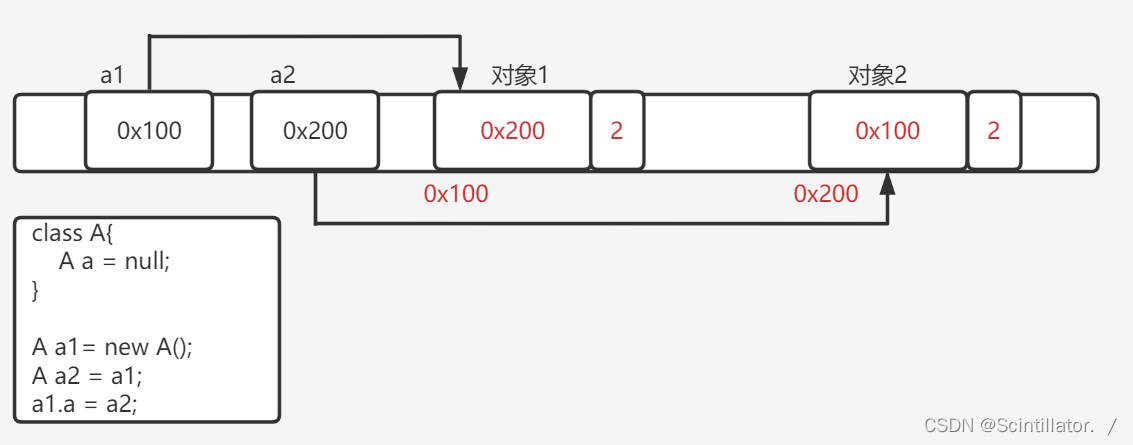
接下来执行 a1 = null ; a2 = null;

此时两个对象的引用计数为0,无法释放,外界也没有代码访问这两个对象,这就造成了 “内存泄漏” 问题(申请了内存却没有释放)- 基于可达性分析: 通过额外的线程,定期针对整个内存空间的对象进行扫描
有以下结构:

对于A来说,F就是访问不到的节点,F就是不可达的,就被认定为垃圾,应该被回收
垃圾的回收:
-
标记 - 清除
标记:就是对对象进行可达性分析,如果是垃圾则标记为垃圾

清除:这里的垃圾都是不连续的,当释放掉这些资源后,会产生很多的 内存碎片 ,内存碎片过多,则空间利用率会下降(比如内存碎片加起来有500M,要申请200M的内存可能会申请失败,因为可能没有连续的200M的内存)

-
复制算法
为了解决上述的内存碎片的问题, 又引入了复制算法

将不是垃圾的内存中的数据,拷贝到没有使用的另一半内存中,然后将之前的一半空间完全释放掉

缺点:- 内存空间利用率低,每次只用一半
- 如果要保留的对象相对于垃圾来说比较多,则复制的开销较大
-
标记 - 整理
类似于顺序表的删除操作,将要保留的前移,然后释放掉后半部分的空间


实际JVM是将多种方案结合 – 分代回收 (根据对象的“年龄”分类,熬过一轮GC扫描,年龄就大了一岁)

- 对于刚创建的对象,都会被放到伊甸区
- 伊甸区的对象熬过一轮扫描,就被拷贝到 幸存区(大部分对象都熬不过一轮GC就被回收了)(复制算法)
- 在后续的几轮GC中, 幸存区的对象就再两个幸存区来回拷贝 (复制算法)
- 若干轮之后,进入老年代
- 老年代的GC扫描频率大大小于新生代 (标记 – 整理 的方式进行回收)
- 例外:比较大的对象最初就会被放到老年代区,因为对象比较大,不适合用复制算法一直复制下去
垃圾回收器
Serial收集器、Serial Old收集器: 串行收集,产生严重的STW
ParNew收集器、Parallel Old收集器、Parallel Scavenge: 并发收集,引入多线程扫描
CMS收集器: 尽可能使得STW时间短1
1. 初始标记,速度很快,会引起短暂的STW
2. 并发标记,速度慢,但可以和业务线程并发执行
3. 重新标记,针对2进行微调
4. 回收内存,并发
G1收集器: 将整个内存划分为很多个小的区域,一次扫描若干个区域(分多次扫描) - 程序计数器
-
相关阅读:
索引(index)
Python之第十章 IO及对象列化
XML——基本语法及使用规则
【锁】悲观锁与乐观锁实现
java基于SpringBoot+Vue的疫苗接种管理系统 element
单例模式的双重检查锁定是什么
java计算机毕业设计家庭食谱管理系统2021MyBatis+系统+LW文档+源码+调试部署
Pioneer | X METAVERSE PRO Explores the New Value of “Mining + Finance“
使用htmlWebpackPlugin添加代码版本信息
操作系统内存管理
- 原文地址:https://blog.csdn.net/qq_45792749/article/details/125488559