-
从资源隔离、资源配额、存储、网络四个方面认识Docker
Docker具有隔离性、可配额、安全性、便携性的特点,此篇博客将从资源隔离、资源配额控制、存储、网络四个方面来认识docker。在了解隔离实现原理前,先了解Docker中容器的定义,基于Linux内核的Cgroup,Namespace,以及Union FS等技术,对进程进行封装隔离,属于操作系统层面的虚拟化技术,由于隔离的进程独立于宿主和其它的隔离进程,因此也称其为容器。Docker在容器的基础上,进行了进一步封装,从文件系统、网络互联到进程隔离等等,极大简化了容器的创建和维护。而进程隔离主要靠Linux Namespace隔离方案来实现。
资源隔离:
Linux Namespace是一种Linux Kernel提供的资源隔离方案,系统可以为进程分配不同的Namespace,并保证不同的Namespace资源独立分配,进程间彼此隔离,即不同的Namespace下进程互不干扰。具体的namespace如下所示:
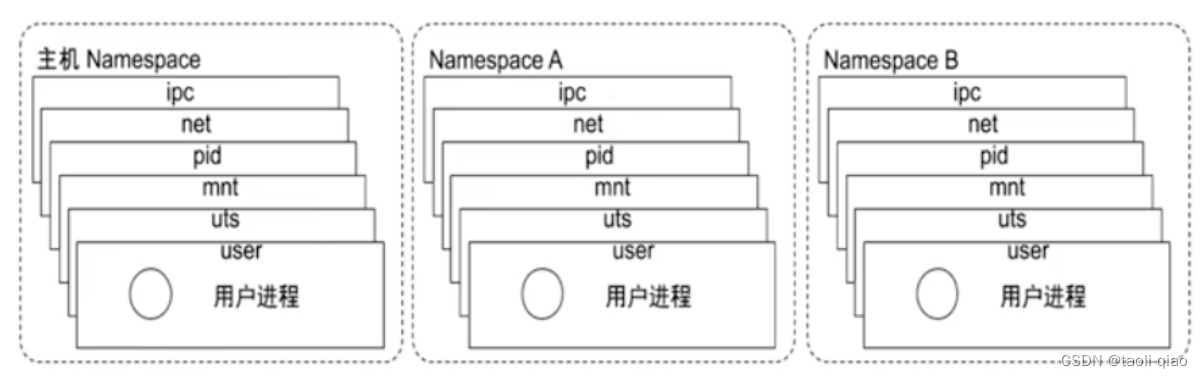
pid namespace:不同用户进程是通过Pid namespace进行隔离的,不同namespace中可以有相同的Pid
net namesapce:每个net namespace有独立的network devices,ip address,pi routing table,/proc/net目录。docker
默认采用veth的方式讲container中的虚拟网卡同host上的一个docker bridge:docker0连接在一起。
ipc namesapce:ipc:interprocess communication,进程间交互方法,包括常见的信号量、消息队列等。
mnt namespace:每个namespace中进程所看到的文件目录被隔离了
uts namespace:Unix Time-sharing system namesapce允许每个container拥有独立的hostname和domain name,使其在网络上可以被视作一个
独立的节点而非Host上的一个进程。
user namespace: 每个container可以有不同的user和group id,等同于可以让container内部的用户执行程序而非Host上的用户。
lsns -t type: 查看当前系统的namespace,可以看到每个进程都有不同的namespace,pid=1的进程事守护进程。
ls -la /proc/$pid/ns:查看当前进程的namespace

nsenter -t $pid -n ip addr:查看某个进程的网络配置 资源配额控制
资源配额控制隔离是通过Linux namespace来实现,那么资源配额又是如何实现的呢?Cgroup是Linux喜爱对于一个或者一组进程进行资源控制和监控的机制,可以对cpu,内存,磁盘I/O等进程所需的资源进行限制。进入/sys/fs/cgroup目录,里面又有cpu,memory目录

进入cpu目录,如果要对进程所使用的cpu进行限制,那么需要先把进程号加入到cgroup.procs中,然后在相关配置文件中设置,即可完成对进程所使用的cpu的控制。例如
cpu.cfs_period_us
cfs_period_us表示一个cpu带宽,单位为微秒。系统总CPU带宽: cpu核心数 * cfs_period_uscpu.cfs_quota_us
cfs_quota_us表示Cgroup可以使用的cpu的带宽,单位为微秒。cfs_quota_us为-1,表示使用的CPU不受cgroup限制。cfs_quota_us的最小值为1ms(1000),最大值为1s。结合cfs_period_us,就可以限制进程使用的cpu。例如配置cfs_period_us=10000,而cfs_quota_us=2000。那么该进程最大可占比的cpu百分比是20%。
接下来做一下小实验,用go语言写个无限循环占用cpu,如果不设置cpu占比的情况下,启动该应用,那么cpu占比应该是200%,此时在cpu目录下创建cpudemo目录,创建该目录后,会自动生产cpu相关配置文件,在cpudemo目录下的cgroup.procs中添加上上进程号,查看cpu.cfs_period_us默认值是100000,此时如果设置cpu.cfs_quota_us的值为10000,那么cpu使用占比会降低到10%,如果设置cpu.cfs_quota_us的值为50000,那么cpu占比会变成50%。
go语言编写的for循环代码如下所示:
- package main
- func main() {
- go func() {
- for {
- }
- }()
- for {
- }
- }
top命令查看cpu占比情况,可以看到是10%和50%两个值。

除了对cpu进行控制外,还可以对memory进行控制,如果要控制进程占用的memory,也是先把进程好写入cgroup.procs中,让后配置可使用的内存总量,例如可设置memory.limit_in_bytes来控制该进程可占用的内存总量,如果超出了设置的值,那么会爆out of memory的错误。
 存储
存储典型的Linux文件系统有Bootfs和rootfs组成,对于不同的linux版本,bootfs基本是一致的,但rootfs有差别,rootfs包含/dev,/proc,/bin,/etc等标准目录和文件,在linux启动后,首先会将rootfs设置为readonly,进行一系列检查后,将其切换为readwrite供用户使用。
Docker启动时将rootfs以readonly方式加载并检查,接着通过union mount的方式将一个readwrite文件系统挂载在readonly的rootfs上且允许再次将下层FS设定为readonly向上叠加,这样一组readonly和一个writeable的结构组成了container的运行时状态。
容器存储有多种类型驱动,比较常见的有OverlayFs存储驱动,接下来将看看overlay工作原理。
一个 overlay 文件系统包含两个文件系统,一个 upper 文件系统和一个 lower 文件系统,是一种新型的联合文件系统。overlay是“覆盖…上面”的意思,overlay文件系统则表示一个文件系统覆盖在另一个文件系统上面。如下图所示,OverlayFS在单个Linux主机上分层两个目录,并将它们显示为单个目录。这些目录称为“ 层” ,统一过程称为“ 联合安装” 。OverlayFS将较低的目录称为lowerdir ,将较高的目录称为upperdir 。统一视图通过其自己的目录称为merged公开。
接下来做一个小实验,在demo目录下,创建lower,upper,work, merged四个目录,切在lower和upper目录下创建文件,然后执行mount命令,执行完成后,可以看到merged目录中包含了lower和upper目录下的所有文件。

执行df -h命令,可以看到demo/merged目录挂载成功

对于docker而言,镜像层就是lower层,容器层就是upper层,那么容器如何通过overflay完成读写操作呢?
读取文件
考虑三种情况,其中容器打开文件以进行覆盖访问。
-
该文件在容器层中不存在 :如果容器打开文件以进行读取访问,并且该文件在容器中(
upperdir)不存在,则从映像(lowerdir)读取该lowerdir)。这几乎不会产生性能开销。 -
该文件仅存在于容器层中 :如果容器打开文件以进行读取访问,并且该文件存在于容器中(
upperdir),而不存在于映像中(lowerdir),则直接从容器中读取文件。 -
该文件同时存在于容器层和图像层中 :如果容器打开文件以进行读取访问,并且文件存在于图像层和容器层中,则将读取容器层中文件的版本。容器层(
upperdir)中的文件会使图像层(lowerdir)中具有相同名称的文件模糊。
修改文件或目录
考虑在某些情况下修改了容器中的文件。
-
首次写入文件 :容器第一次写入现有文件时,该文件在容器中不存在(
upperdir)。overlay/overlay2驱动程序执行copy_up操作,将文件从映像(lowerdir)复制到容器(upperdir)。然后,容器将更改写入容器层中文件的新副本。但是,OverlayFS在文件级别而不是块级别工作。这意味着所有OverlayFS copy_up操作都会复制整个文件,即使该文件非常大且只有一小部分被修改。这会对容器写入性能产生明显影响。但是,有两点值得注意:
-
copy_up操作仅在第一次写入给定文件时发生。随后对同一文件的写入将对已经复制到容器的文件副本进行操作。
-
OverlayFS仅适用于两层。这意味着性能应该比AUFS更好,后者在多层图像中搜索文件时可能会出现明显的延迟。此优点适用于
overlay和overlay2驱动程序。overlayfs2相比,overlayfs在初次读取时的性能要overlayfs于overlayfs,因为它必须遍历更多的层,但是会缓存结果,因此这只是一个小小的代价。
-
-
删除文件和目录 :
-
当一个文件被一个容器中删除,在所述容器(创建文件白斑
upperdir)。不会删除图像层(lowerdir)中文件的版本(因为lowerdir是只读的)。但是,白化文件会阻止容器使用它。 -
当一个目录由容器内删除, 不透明目录在容器(内创建
upperdir)。这与中断文件的工作方式相同,并且即使该目录仍然存在于映像(lowerdir)中,也可以有效地防止该目录被访问。
-
-
重命名目录 :仅当源路径和目标路径都在顶层时,才允许对目录调用
rename(2)。否则,它将返回EXDEV错误(“不允许跨设备链接”)。您的应用程序需要设计为可以处理EXDEV并退回到“复制和取消链接”策略。
网络
前面介绍了存储,接下来看看网络方面,即同一个instance上不同容器间如何进行网络通信。容器启动的时候可以设置不同的网络模式,默认情况时bridge模式,为了更好的理解bridge工作模式,我们会启动一个Null的网络模式(即不进行任何网络配置),然后通过手动配置的方式实现Bridge。
步骤一:启动一个null模式nginx容器(docker run --network=none -d nginx)
步骤二:获取容器的Pid(docker inspect ff8b08a72f93 (containerID)|grep -i pid)
步骤三:查看容器的网络配置(nsenter -t 69984(pid) -n ip a),可以看到只有loopback配置

步骤四:进行桥接配置
4.1创建veth pair
//可以理解称创建了一根网线,网线的一头为A,林外一头为B
ip link add A type veth peer name B4.2网线的A口连接到宿主机的docker0上
brctl addif docker0 A
ip link set A up4.3将网线的B口连接到容器进程上
SETIP=172.17.0.10
SETMASK=16
GATEWAY=172.17.0.1ip link set B netns $pid
//通过容器的进程号将网线的B口连接上容器
ip netns exec $pid ip link set dev B name eth0
//将网线的B口名称修改为eth0
ip netns exec $pid ip link set eth0 up
ip netns exec $pid ip addr add $SETIP/$SETMASK dev eth0
//通过容器的进程号设置容器的ip地址
ip netns exec $pid ip route add default via $GATEWAY
//通过容器的进程号设置容器的网管步骤五:配置完成后,通过curl命令(curl 容器IP地址)访问启动nginx容器,可以看到获取nginx内容成功,说明网络配置成功。

再次查看容器进程的网络配置,可以看到除了boopback外,eth0进行了网络配置。

再次用docker run -d nginx命令新启动一个nginx容器,因为默认是桥接方式,查看新启动的nginx容器进程,会发现网络配置和上面手动配置结果相同。
总结网桥模式,docker 服务默认会创建一个
docker0网桥,docker 默认指定了docker0接口 的 IP 地址和子网掩码,让主机和容器之间可以通过网桥相互通信。通过创建veth pair,每个启动的容器和主机的docker进行联通,这样容器之间也进行了互通。 -
相关阅读:
你知道哪几种Java锁?分别有什么特点?
Python快速刷题网站——牛客网 数据分析篇(九)
程序员是不是人均黑客?
Spring底层原理学习笔记--第十讲--(aop之agent增强)
【数据挖掘】分类与回归预测
pytorch-损失函数-分类和回归区别
【从零开始一步步学习VSOA开发】同步RPC客户端
【数据结构与算法分析】0基础带你学数据结构与算法分析05--串 (string)
如何在Docker中安装MySQL数据库
【蓝桥杯选拔赛真题15】C++三个数排序 第十二届青少年组蓝桥杯C++选拔赛真题解析
- 原文地址:https://blog.csdn.net/qiaotl/article/details/125495590