-
List集合&UML图
目录
List接口
基本介绍
特点:元素有序,且可重复
遍历:下标,foreach,迭代器
扩容:
- 初始容量10,负载因子0.5,扩容增量0.5倍
- 新容量 = 原容量 + 原容量 * 0.5 , 如 ArrayList的容量为10,那么一次扩容后容量为15
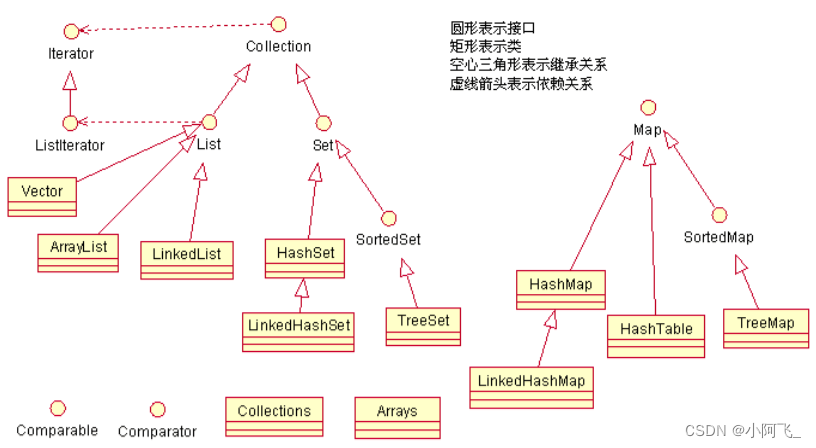
List的实现类
1、ArrayList
- 简单数据结构,超出容量自动扩容,动态数组
- ArrayList扩容原理图解:

- ArrayList的扩容机制是效率和空间的之间的平衡,
- 内部实现是基于基础的对象数组的
- 不适合随机增加或删除(有位移现象)
- 适用于不确定数据的最大个数的情况
- 随机访问快、遍历快
- 线程不安全(在作为类的成员变量时)
2、LinkedList
- LinkedList提供额外的get,remove,insert方法在LinkedList的首部或尾部
- LinkedList可被用作堆栈(stack)【包括了push,pop方法】,队列(queue)或双向队列(deque)
- 以双向链表实现,链表无容量限制,允许元素为null,线程不安全
双向链表图鉴:

适合做随机的增加或删除,因为链表结构在增加删除时不会出现位移现象
3、Vector
线程安全,但是并行性能慢(因为上锁了),不建议使用
4、CopyOnWriteArrayList
- 写时复制
- 线程安全
- (版本的)最终一致性,无法做到实时版本一致
- 比Vector性能高
- 适合于读多,写少的场景
- 实现了List接口,使用方式与ArrayList类似
- 写时复制出一个新的数组,完成插入、修改或者移除操作后将新数组赋值给原来的数组
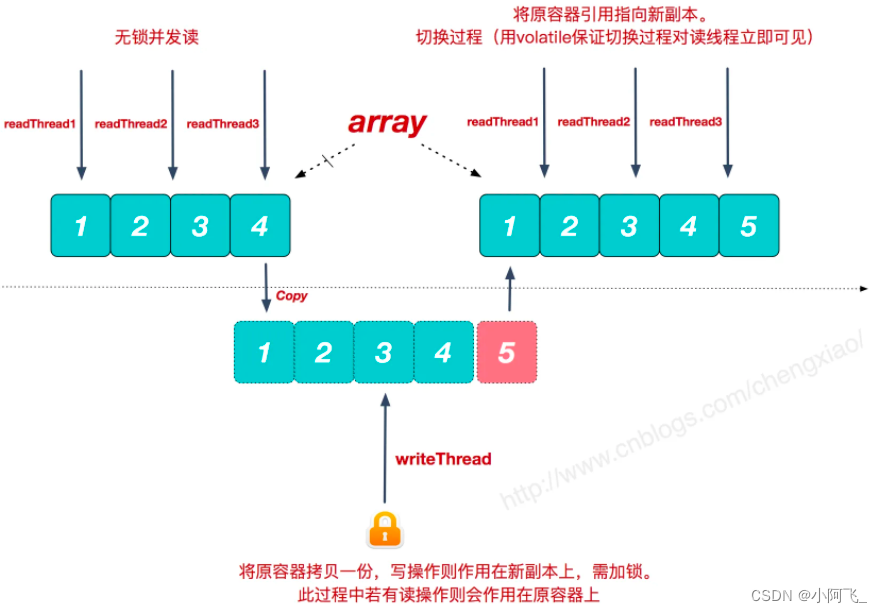
CopyOnWriteArrayList图解
在看图之前先了解一下读和写的概念
- 读:只对数据进行读取,不修改数据(CopyOnWriteArrayList中原来的集合用于读)
- 写:对数据进行一下操作使得数据产生变化(CopyOnWriteArrayList中新集合用于写)
在CopyOnWriteArrayList对新集合所有“写”的操作一旦完成,指向原来那个集合的指针就会马上指向新集合,体现了最终一致性
使用ArrayList中remove方法的注意点
remove特性:
- 传入整数类型时删除下标
- 传入对象类型时删除对应的元素(如Integer.parseInt(null))
数据准备工作:为方便演示,需要有紧挨在一起的两个或多个相同的元素
- List<Integer> list=new ArrayList<Integer>();
- list.add(1);
- list.add(2);
- list.add(3);
- list.add(3);
- list.add(4);
使用ArrayList中remove方法的几种不同的写法:
- 错误写法示例
- for(int i=0;i<list.size();i++){
- if(list.get(i)==3) list.remove(i);//list.get(i)得到下标为i的元素
- }
👆👆错误原因:ArrayList在增加和删除时有位移现象,当两个一样的元素3相邻时,第一个3在判断并删除后,第二个3及其后面的所有元素的下标都会向前移动一位,这样第二个3就到了第一个3下标所在的位置,但是指针已经判断过第一个3所在位置的元素是否为3了,故不会删除掉第二个3
- for(Integer i:list){
- if(i==3) list.remove(i);
- }
👆👆错误原因:因为ArrayList中有一个变量(modCount=原数组的元素个数)还在内部封装了一个内部类(Itr),这个内部类实现了迭代器,当使用foreach方法遍历时,使用的是ArrayList内部类的迭代器,其中内部类中定义了一个改变次数的变量(expectedModCount),这个变量被赋值为外部modcount的值,当使用内部类(Itr)发生增加或者修改操作时,抛出异常,其目的是阻止ArrayList长度发生改变。
简而言之,就是不推荐使用foreach进行集合的增加和删除操作,它更适合用来遍历数据
- 正确写法示例
- for(int i=0;i<list.size();i++){
- if(list.get(i)==3) list.remove(i--);
- }
👆👆正确原因:使用了i--,即在进行删除之后指针会向前移一位,再回到删除过的下标位置进行判断,而这样就避免了因为ArrayList的位移现象所导致的判断遗漏。
注意:不可使用--i,因为--i会在remove方法在删除之前执行
- for(int i=list.size()-1;i>=0;i--){
- if(list.get(i)==3){
- list.remove(i);
- }
- }
👆👆正确原因:使用了从集合中的最后一位元素向第一位元素方向进行遍历的倒序遍历方法,这样即使ArrayList的位移现象发生也无法对删除产生影响
最后一种写法:ArrayList集合在进行删除、增加等操作时,要考虑其动态位移的特性,推荐使用迭代器,会比较安全
- Iterator<Integer> it=list.iterator();
- while(it.hasNext()){
- if(it.next()==3){
- it.remove();
- }
- }
注意:上述代码的it.remove不要写成list.remove(i)
UML图
什么是UML图?
统一建模语言(UML)是一种模型化语言
模型大多以图表的方式表现出来
建模图表通常包含几个块或框,连接线和作为模型附加信息之用的文本,在UML规则中相互联系和扩展。
为什么使用UML图?
(1)UML统一了各种方法对不同类型的系统、不同开发阶段以及不同内部概念的不同观 点,从而有效的消除了各种建模语言之间不必要的差异。它实际上是一种通用的建模语言,可以为许多面向对象建模方法的用户广泛使用。
(2)UML建模能力比其它面向对象建模方法更强。它不仅适合于一般系统的开发,而且对并行、分布式系统的建模尤为适宜。
(3)UML是一种建模语言,而不是一个开发过程。
UML图示例
UML图中的关系及表示
1、关联(Association)
关联关系是一种拥有的关系,它使一个类知道另一个类的属性和方法;如:老师与学生,丈夫与妻子关联可以是双向的,也可以是单向的。双向的关联可以有两个箭头或者没有箭头,单向的关联有一个箭头
代码体现:成员变量
箭头及指向:带普通箭头的实心线,指向被拥有者

上图中,老师与学生是双向关联,老师有多名学生,学生也可能有多名老师。但学生与某课程间的关系为单向关联,一名学生可能要上多门课程,课程是个抽象的东西他不拥有学生
下图为自身关联:

2、依赖(Dependency)
依赖关系是一种使用的关系,即一个类的实现需要另一个类的协助,所以要尽量不使用双向的互相依赖,一般为单向依赖
代码表现:局部变量、方法的参数或者对静态方法的调用
比如一个类的方法中使用了别的类中的方法,或者一个类的方法中使用了局部变量
关联关系越强,依赖关系也就越强
箭头及指向:带箭头的虚线,指向被使用者

3、聚合与组合
指的都是整体中的局部与整体的关系的密切程度,它们都是关联关系的一种
组合(Composition)
- 是整体与部分的关系,但部分不能离开整体而单独存在。如公司和部门是整体和部分的关系,没有公司就不存在部门
- 组合关系是关联关系的一种,是比聚合关系还要强的关系,它要求普通的聚合关系中代表整体的对象负责代表部分的对象的生命周期
- 代码体现:成员变量
- 箭头及指向:带实心菱形的实线,菱形指向整体

聚合(Aggregation)
- 是整体与部分的关系,且部分可以离开整体而单独存在。如车和轮胎是整体和部分的关系,轮胎离开车仍然可以存在。
- 聚合关系是关联关系的一种,是强的关联关系;关联和聚合在语法上无法区分,必须考察具体的逻辑关系
- 代码体现:成员变量
- 箭头及指向:带空心菱形的实心线,菱形指向整体

4、实现(Realization)
是一种类与接口的关系,表示类是接口所有特征和行为的实现
箭头指向:带三角箭头的虚线,箭头指向接口

5、泛化(Generalization)
是一种继承关系,表示一般与特殊的关系,它指定了子类如何特化父类的所有特征和行为。例如:老虎是动物的一种,即有老虎的特性也有动物的共性
箭头指向:带三角箭头的实线,箭头指向父类

小结
各种关系的强弱顺序:
泛化 = 实现 > 组合 > 聚合 > 关联 > 依赖
下面这张UML图,比较形象地展示了各种类图关系:

-
相关阅读:
昇思25天学习打卡营第01天|imdeity
python查询数据库发送邮件,附件csv格式,xlsx格式
韵达快递 | 快递单号查询API
面试-Java【之】HashMap原理,源码逐行分析,理论总结(变量、常量、数据结构、Node、TreeNode、初始化、添加、查询、更新、删除)
清理迅雷系列软件数据记录【破坏性】
掌握可扩展和可维护应用程序:12-Factor应用程序开发的全面指南
极简c++(8)抽象类与多态
利用二维码定位技术实现桌面机器人简易定位方案(上篇)
值得注意的: c++动态库、静态库、弱符号__attribute__((weak))以及extern之间的关系
Qt安装使用
- 原文地址:https://blog.csdn.net/yifei_345678/article/details/125483171