-
C和指针 第12章 使用结构和指针 12.7 问题
1. 能够进行改写程序12.3,使其不使用current变量?如果可以,把你的答案和原先的函数进行比较。
解析:
可以。但是改写后的可读性变差了,除了删除声明处的current变量外,所有出现的current都必须使用*linkp代替,并使用括号括起来,避免因为操作符优先级造成编译不通过的问题。/*
** problem_1_sll_node.h。
*/
#ifndef SLL_NODE_H
#define SLL_NODE_Htypedef struct NODE {
struct NODE *link;
int value;
} Node;extern int sll_insert( register Node **linkp, int new_value );
#endif
/*
**插入到一个有序单链表。函数的参数是一个指向链表根指针的指针,以及一个需要插入的新值。
**problem_1_sll_insert.cpp。
*/
#include <stdlib.h>
#include <stdio.h>
#include "problem_1_sll_node.h"#define FALSE 0
#define TRUE 1int sll_insert( register Node **linkp, int new_value ){
Node *new2;
/*
**寻找正确的插入位置,方法是按序访问链表,直到到达一个其值大于或等于新值的节点。
*/
while( *linkp != NULL && (*linkp)->value < new_value ){
linkp = &(*linkp)->link;
}
/*
**为新节点分配内存,并把新值存储到新节点中,如果内存分配失败,函数返回FALSE。
*/
new2 = (Node *)malloc( sizeof(Node) );
if( new2 == NULL ){
return FALSE;
}
new2->value = new_value;
/*
**把新节点插入到链表中,并返回TRUE。
*/
new2->link = *linkp;
*linkp = new2;
return TRUE;
}/*
** problem_1_main.cpp。
*/
#include <stdio.h>
#include <stdlib.h>
#include "problem_1_sll_node.h"
int main( void ){
Node *root;
Node *pt;
Node *node, *node2, *node3;
int result, result2, result3, result4;
node = (Node *)malloc( sizeof(Node) );
node2 = (Node *)malloc( sizeof(Node) );
node3 = (Node *)malloc( sizeof(Node) );
if( node && node2 && node3 ){
root = node;
node->value = 5;
node->link = node2;
node2->value = 10;
node2->link = node3;
node3->value = 15;
node3->link = NULL;
}
printf( "print original elements in linked list:\n" );
pt = root;
while( pt ){
printf( "%d ", pt->value );
pt = pt->link;
}
printf( "\n" );
/*
** the second version of insert.
** right version.
*/
result = sll_insert( &root, 12 );
printf( "after result = sil_insert( root, 12 ), result = %d\n", result );
printf( "print elements in linked list:\n" );
pt = root;
while( pt ){
printf( "%d ", pt->value );
pt = pt->link;
}
printf( "\n" );
result = sll_insert( &root, 20 );
printf( "after result = sil_insert( root, 20 ), result = %d\n", result );
printf( "print elements in linked list:\n" );
pt = root;
while( pt ){
printf( "%d ", pt->value );
pt = pt->link;
}
printf( "\n" );
result = sll_insert( &root, 4 );
printf( "after result = sil_insert( root, 4 ), result = %d\n", result );
printf( "print elements in linked list:\n" );
pt = root;
while( pt ){
printf( "%d ", pt->value );
pt = pt->link;
}
printf( "\n" );
return EXIT_SUCCESS;
}
/* 输出:
*/
2. 有些数据结构图书建议在单链表中使用“头节点”。这个哑点始终是链表的第一个元素,这就消除了插入到这个链表起始位置这个特殊情况。讨论这个技巧的利与弊。
解析:
与不用处理任何特殊情况代码的sll_insert函数相比,这种使用头结点的技巧没有任何优越之处。而且自相矛盾的是,这个声称用于消除特殊情况的技巧,实际上将引入用于处理特殊情况的代码。如果链表被创建,必须添加哑节点。其它操纵这个链表的函数必须跳过这个哑节点。最后,这个哑节点还会浪费内存。3. 在程序12.3中,插入函数会把重复的值插入到什么地方?如果把比较操作符由<改为<=会有什么效果?
解析:
插入函数会把重复的值插入到重复的值的最前面。如果把比较操作符由<改为<=会导致把重复的值插入到重复的值的最后面。(很容易验证,添加一个计数器,观察计数器的值就能知道插入函数把重复的值插入到重复的值最前面还是最后面)4. 讨论怎样省略双链表中根节点的值字段的一些技巧。
解析:
Node *root;
root = (Node *)malloc( sizeof(Node) - sizeof(ValueType) );
一种更安全的方式是声明一个只包含指针的结构。根指针就是这类结构之一,每个节点只包含这类结构的一个。这种方法的有趣之处在于结构之间的相互依赖,每个结构都包含了一个对方类型的字段。这种相互依赖性就在声明它们时产生了一个“先有鸡还是先有蛋”的问题:那个结构先声明呢?这个问题只能通过其中一个结构标签的不完整声明来解决。
struct DLL_NODE;struct DLL_POINTERS {
struct DLL_NODE *fwd;
struct DLL_NODE *bwd;
};struct DLL_NODE {
struct DLL_POINTERS pointers;
int value;
};5. 如果程序12.7中对malloc的调用在函数的起始部分执行,会有什么结果?
解析:
可能导致内存泄漏。如果插入的元素在链表中已经存在,则会操作内存泄漏;否则,不会造成内存泄漏。
6. 能不能对一个无序的单链表中进行排序?
解析:
可以进行排序。只是对单链表中的数值部分进行修改即可。
#include <stdio.h>
#include <stdlib.h>typedef struct Node{
struct Node *link;
int value;
} Node;void sort_list( Node *rootp );
int main( void ){
struct Node *head;
struct Node *p;
struct Node *pnode, *pnode2, *pnode3, *pnode4;
pnode = (struct Node *)malloc( sizeof(struct Node) );
pnode2 = (struct Node *)malloc( sizeof(struct Node) );
pnode3 = (struct Node *)malloc( sizeof(struct Node) );
pnode4 = (struct Node *)malloc( sizeof(struct Node) );
if( pnode && pnode2 && pnode3 && pnode4 ){
head = pnode;
pnode->value = 20;
pnode->link = pnode2;
pnode2->value = 10;
pnode2->link = pnode3;
pnode3->value = 15;
pnode3->link = pnode4;
pnode4->value = 13;
pnode4->link = NULL;
}
p = head;
while( p ){
printf( "%d ", p->value );
p = p->link;
}
printf( "\n" );
sort_list( head );
printf( "after sort_list( &head ):\n" );
p = head;
while( p ){
printf( "%d ", p->value );
p = p->link;
}
printf( "\n" );return EXIT_SUCCESS;
}void sort_list( Node *rootp ){
Node *outer_pointer;
Node *inner_pointer;
if( !rootp ){
printf( "rootp pointer can't be NULL.\n" );
return;
}
for( outer_pointer = rootp; outer_pointer; outer_pointer = outer_pointer->link ){
Node *ptemp = outer_pointer;
for( inner_pointer = outer_pointer->link;
inner_pointer;
inner_pointer = inner_pointer->link){
if( ptemp->value > inner_pointer->value ){
int temp = ptemp->value;
ptemp->value = inner_pointer->value;
inner_pointer->value = temp;
}
}
}
}
/* 输出: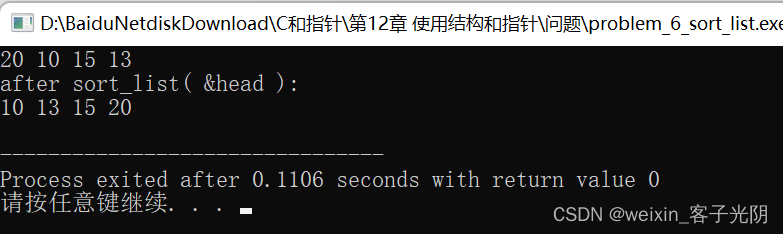
*/
7. 索引表(concordance list)是一种字母链表,表中的节点是出现于一本书或一篇文章中的单词。可以使用一个有序的字符串单链表实现索引表,使用插入函数时不插入重复的单词,与这种实现方法有关的问题是,搜索链表的时间将随着链表规模的扩大而急剧增长。
图12.1说明了另一种存储索引表的数据结构。它的思路是把一个大型的链表分解为26个小型的链表---每个链表中的所有单词都以同一个字母开头。最初链表中的每个节点包含一个字母和一个指向一个以该字母开头的单词的有序单链表(以字符串形式存储)的指针。使用这种数据结构搜索一个特定的单词所花费的时间与使用一个存储所有单词的单链表相比,有没有变化?
解析:
在多个链表的方案中进行查找比在一个包含所有单词的链表中进行查找效率要高得多。例如,查找一个以字母b开头的单词,我们就不需要在那些以a开头的单词中进行查找。在26个字母中,如果每个字母开头的单词出现频率相同,这种多个链表方案的效率几乎可以提高26倍。不过实际改进的幅度要比这小一些。
-
相关阅读:
FlyWeight(享元模式)
“华为杯”研究生数学建模竞赛2019年-【华为杯】F题:智能飞行器航迹规划模型(中)(附优秀论文及Pyhton代码实现)
Java开发之高并发必备篇(六)——Lock和ReentrantLock(2)
合宙Air724UG LuatOS-Air LVGL API控件-图片(Gif)
【无标题】
问题:关于醋酸钠的结构,下列说法错误的是() #媒体#媒体
scratch颜色搭配 电子学会图形化编程scratch等级考试四级真题和答案解析2022年9月
Kotlin 中的协程 flow
wordpress 上传附件中文文件名乱码解决办法(for Windows)
【初学人工智能原理】【3】梯度下降和反向传播:能改(上)
- 原文地址:https://blog.csdn.net/weixin_40186813/article/details/125483606