-
java多线程面试相关的一些问题
- java中System.out.println()会影响到内存得可见性。
答:因为 println这个语句 ,看源码得知,这个玩意外面包了一层synchronized
1.获得同步锁
2.清空工作内存
3.从主内存中拷贝对象副本到本地内存
4.执行代码(打印语句或加加操作)
5.刷新主内存数据
6.释放同步锁
这也就是System.out.println()为何会影响内存可见性的原因了。 - volatile这个关键字是用来使得变量强制从内存中读取。只能修饰变量,他是用来解决变量在多个线程之间得可见性。而synchronized关键字解决得是多个线程之间访问公共资源得同步性。
- cas是什么?
答:cas是一种思想。他得思路是,有一个公共变量,多个线程去操作。每个线程先把这个值拿到,放到本地中,然后进行一番操作,操作结束后,此时再比对,最开始拿到得这个变量和内存得公共变量进行比对,如果相同,则进行更新。如果不相同,则撤销刚才得操作,重新执行代码。
package test1; public class Test1 { public static void main(String[] args) throws InterruptedException { Test2 test2 = new Test2(); for (int i = 0; i < 100; i++) { new Thread(()->{ for (int j = 0; j < 100; j++) { test2.bidaxiao(); } }).start(); } Thread.sleep(3000); System.out.printf(""+test2.getValue()); } } class Test2{ public long getValue() { return value; } private synchronized boolean bianhua(long oldValue,long newValue){ if(oldValue==value){ value=newValue; return true; } return false; } private volatile long value; public long bidaxiao(){ long oldValue; long newValue; do{ oldValue=value; newValue=oldValue+1; }while (!bianhua(oldValue,newValue)); return newValue; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- cas中会产生ABA问题,那什么是ABA问题,这种问题该如何规避呢?
答:首先说ABA问题,假设有单位给员工发福利,给每个员工存200块钱,此时假设判断依据就是所有员工账号内为0元,那么就给该员工存200,如果为账户余额为200,那么就代表存过了,不是200就代表没存过,但是会有这么一种情况,如果该员工刚好把这200块钱花了,但是此时线程判断依据是不是200就代表没存过,那么就又给这个账号存了200,此时就是说给这个账号存了400块钱,就会产生错误。这就是ABA问题,ABA问题也是可以解决的,就是引入辅助参数,就相当于给这个账号再增加一个辅助参数,如果存了,那就改边这个参数为true(已经存了),那么下次其他线程进来一看,哎已经存了,就不会给这个账号存钱了。这也是乐观锁的解决办法。 - 基于cas这种思想java中提供了很多这样的原子类,
5.1 原子更新基本类型类
AtomicBoolean:原子更新布尔类型
AtomivInteger:原子更新整型
AtomicLong:原子更新长整型
5.2 原子更新数组
AtomicIntegerArray:原子更新整型数组里的元素
AtomicLongArray:原子更新长整型数组里的元素
AtomicReferenceArray:原子更新引用类型数组中的元素
5.3 原子更新引用类型
AtomicReference:原子更新引用类型
AtomicReferenceField:原子更新引用类型的字段
AtomicMarkableReference:原子更新带有标记位的引用类型
5.4 原子更新字段类
AtomicIntegerFieldUpdate:原子更新整型字段的更新器
AtomicLongFieldUpdate:原子更新长整型字段的更新器
AtomicStampedReference:原子更新带有版本号的引用类型
// AtomicLong 代码示例 public class AutomicL { private AutomicL() {} private static AutomicL automicL=new AutomicL(); public static AutomicL getAutomicL() { return automicL; } private final AtomicLong count=new AtomicLong(0); private final AtomicLong success=new AtomicLong(0); private final AtomicLong fail=new AtomicLong(0); public void countAdd(){ //相当于增加1 count.incrementAndGet(); } public void successAdd(){ success.incrementAndGet(); } public void failAdd(){ fail.incrementAndGet(); } public long getCount() { return count.get(); } public long getSuccess() { return success.get(); } public long getFail() { return fail.get(); } } //测试类 public class Test4 { public static void main(String[] args) throws InterruptedException { AutomicL automicL = AutomicL.getAutomicL(); for (int i = 0; i < 1000; i++) { new Thread(()->{ automicL.countAdd(); Random random=new Random(); if(random.nextInt(10)%2==0){ automicL.successAdd(); }else { automicL.failAdd(); } }).start(); } Thread.sleep(3000); System.out.println(""+automicL.getCount()); System.out.println(""+automicL.getSuccess()); System.out.println(""+automicL.getFail()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- wait()方法只能在同步代码块中由锁对象调用,调用wait方法,当前线程会释放锁,notify可以唤醒线程,该方法也必须在同步代码块中由锁对象调用,如果有多个等待线程,notify方法只能唤醒一个,而且必须是当前代码块执行完毕,才会唤醒wait()线程,notify不会立刻释放锁对象。
- await()和signal()这是干什么得?
答:await是用来等待得。会释放掉锁,他是Condition里面得方法,还有一个类似得叫wait方法。他是obeject得方法。同样是等待释放锁。sinnal是唤醒锁。await和signal它两有个特别得地方就是得需要先获取锁对象。 - 读写锁的互斥性?
答:读写锁允许读读共享,读写互斥,写写互斥。 - 线程池的应用
线程池一个比较顶级的接口就是ExecutorService,下面是关于Excutors这个工具类的一些应用,而最顶级的线程池接口是Excutor接口。我们常用到的就是Excutors生成出来的一些线程池。这个工具类生成的实现类就是ExcutorService。
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(10); // scheduledExecutorService.schedule(()->{ // System.out.println(Thread.currentThread().getName()+Thread.currentThread().getId()+System.currentTimeMillis()); // },3, TimeUnit.SECONDS); //这个玩意相当于是个定时执行的家伙 /** * 下面说的是在3秒后开始执行改任务,以后每隔2秒再执行一次,如果线程运行时长超过间隔时长,那么就会运行完毕后,立马投入下个线程运行 */ // scheduledExecutorService.scheduleAtFixedRate(new Runnable() { // @Override // public void run() { // System.out.println("现在的执行时间是"+System.currentTimeMillis()); // } // },3,2,TimeUnit.SECONDS); /** * 下面这个方法是说,运行完线程后,在间隔后继续执行线程 */ scheduledExecutorService.scheduleWithFixedDelay(()->{ System.out.println("当前线程为:"+Thread.currentThread().getId()+"时间为:"+System.currentTimeMillis()); try { Thread.sleep(4000); } catch (InterruptedException e) { e.printStackTrace(); } },3,2,TimeUnit.SECONDS);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 线程池底层原理代码怎么说?
答:Excutors工具类中返回线程池的方法底层都返回的是ThreadPoolExcutor线程池,其中大部分方法都是ThreadPoolExcutor进行封装的。 - ThreadPoolExcutor线程池的构造方法参数讲解。
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { ...... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
corePoolSize 这个是说线程池中核心线程的数量
maximumPoolSize 这个是说线程池中最大的线程数量
keepAliveTime 当线程池线程的数量超过corePoolSize时,多余的空闲线程的存活时长,即空余线程多长时间会销毁。
unit 指keepAliveTime时长的单位
workQueue 任务队列,把任务提交到该任务队列中等待执行
threadFactory 线程工厂,用于创建线程
handler 拒绝策略,当任务太多的时候,如何拒绝
说明 workQueue工作队列是指提交执行的任务队列,他是BlockingQueue接口的对象,仅用于存储Runnable任务,根据队列功能分类,在ThreadPoolExcutor构造方法中可以使用以下几种阻塞队列:
11.1. 直接提交队列, 由SynchronousQueue对象提供,该队列没有容量,提交给线程池的任务不会被真实的保存,总是将新的任务提交给线程执行,如果没有空余线程,则尝试创建新的线程,如果线程数量已经达到maximumPoolSize就执行线程拒绝策略。
11.2. 有界任务队列,由ArrayBlockingQueue实现在创建这个对象的时候,可以指定一个容量,当有新任务执行的时候,如果我们线程池中的线程数小于核心线程数,如果大于核心线程数,则加入队列。如果队列已满,则无法加入,在线程数小于maximumPoolSize 指定的最大线程数前提下会创建新的线程来执行,如果线程数大于maximumPoolSize 最大线程数则执行拒绝策略。
11.3. 无界任务队列,由LinkedBlokingQueue对象实现,与有界队列相比,除非系统资源耗尽,否则不存在任务入队失败的情况,在系统线程数小于核心线程数,则会创建新的线程来执行任务;当线程池线程数量大于核心线程数则把任务加入阻塞队列中。
11.4. 优先任务队列,是由PriorityBlockingQueue实现的。是带有任务优先级的队列,是一个特殊的无界队列,上面ArrayBlockingQueue还是LinkedBlockingQueue,都是按照先进先出的原则来处理任务的。-
线程池是如何新建和进入队列得?
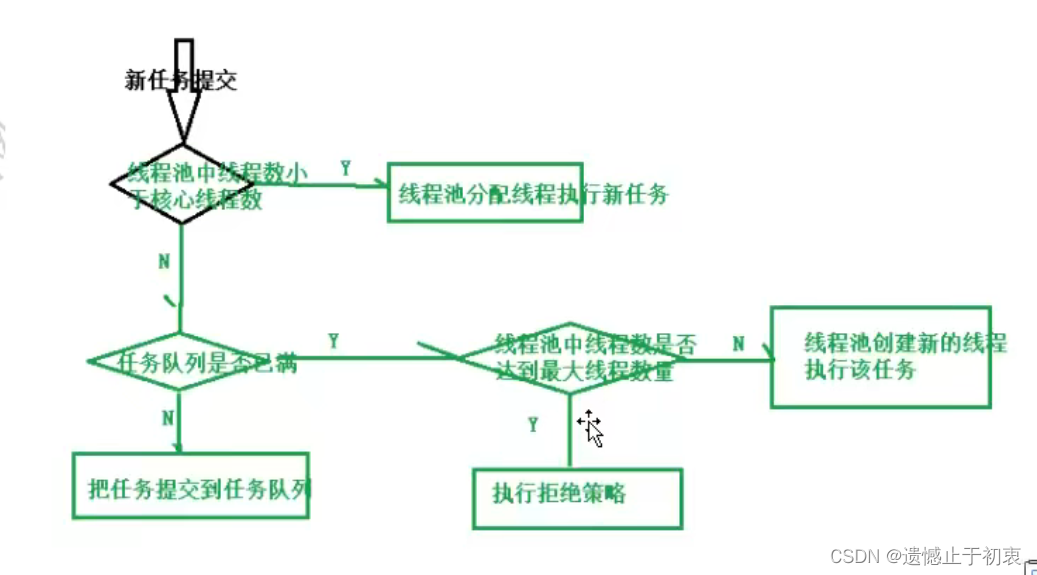
-
ThreadPoolExcutor中的拒绝策略介绍
答:RejectedExecutionHandler是拒绝策略的顶级接口,
AbortPolicy这个类是线程池默认的拒绝策略,如果任务无法处理,那么就抛出异常。
CallerRunsPolicy这个类的作用是说只要线程池关闭,会调用线程被丢弃的任务。
DiscardOldestPolicy 将线程池中最老的任务丢弃掉,尝试继续提交新的线程。
DiscardPolicy 直接丢弃这个无法处理的线程。 -
ThreadPoolExcutor中存在吃异常得现象。
答:ThreadPoolExcutor中得submit提交线程得方法。如果线程中有异常产生,他会把线程异常吃了。而如果使用excute提交线程,则会把线程得异常进行一个抛出。当然了我们也可以重写它的方法,我们继承ThreadPoolExcutor这个线程类,然后重写这个类的方法submit和这个excutor方法。就可以重新定义这个方法。进行方法异常的捕获处理。 -
栈、堆、元空间。
答:堆空间和元空间是线程可以共享的空间,即实例变量和静态变量是线程可以共享的。可能存在线程安全问题,栈空间是线程私有的存储空间,局部变量存储在栈空间中,局部变量是固定的。 -
锁的优化。
答:
1. 减少锁的持有时间
2. 减少锁的粒度,一个锁保护的共享数据的大小,称为锁的粒度。如果一个锁保护共享数据的数据量大,称为锁的粒度粗。反之称为锁的粒度细。
3. 使用读写分离锁来代理独占锁。使用readwriteLock读写分离锁可以提高系统性能。
4. 锁分离,比如说LinkedBlockQueue这个类从头部取,从尾部插入 -
偏向锁的概念。
答:锁偏向,是说如果一个线程获得了锁,那么锁就进入了偏向模式,当这个线程在请求锁的时候,无需任何同步操作,这样可以节省有关锁申请的时间,提高程序的性能。
锁偏向在没有竞争的时候,可以有较好的效果,对于锁竞争比较激烈的场景效果不佳,锁竞争比较激烈的时候,可能是每次请求的锁都不一样,这是偏向模式失效。 -
锁升级的概念。
答:如果锁偏向失败,jvm并不会立即挂起线程,还会使用一种称为轻量锁的优化手段,会将共享对象(可以理解为就是synchronized锁的对象)的头部作为指针,指向持有锁的堆栈内部,来判断一个线程是否持有对象锁,如果线程获得轻量锁成功,那么就进入临界区,如果获得轻量锁失败,表示其他线程抢到了该锁,那么当前线程的锁的请求就升级为重量级锁,当前线程就转到阻塞队列中,变为阻塞状态。
偏向锁和轻量锁两个都是乐观锁,重量锁是悲观锁。
一个对象刚开始实例化时,没有任何线程访问它,它是可偏向的,即 它认为只可能有一个线程来访问它,所以当第一个线程来访问它的时候,它会偏向这个线程.偏向第一个线程,这个线程在修改对象头成为 偏向锁时使用0X5操作,将对象头中油宫姻改成自己的16之后再访 问这个对象时,只需要对比ID即可.一旦有第二个线程访问该对象,因 为偏向锁不会主动释放,所以第二个线程可以查看对象的偏向状态,当 第二个线程访问对象时,表示在这个对象上已经存在竞争了,检查原来 持有对象锁的线程是否存活,如果挂了则将对象变为无锁状态,然后重新偏向新的线程;如果原来的线程依然存活,则马上执行原来线程的栈,检查该对象的使用情况,如果仍需要偏向锁,则偏向锁升级为轻量锁。
轻量锁认为竞争存在,但是竞争的程度很轻,一般两个线程对同一个锁的操作会错开,或者是稍微等待一下(这个稍微等待一下叫自旋)另外一个线程就会释放锁,当自旋超过一定的次数,或者一个线程持有锁,一个线程在自旋,又来第三个线程方法时,轻量级锁会膨胀为重量锁,重量锁除了持有锁的线程外,其他的线程都阻塞 -
线程不同步的代码。
public class ThreadLo { private String content; public String getContent() { return content; } public void setContent(String content) { this.content = content; } public static void main(String[] args) { ThreadLo threadLo = new ThreadLo(); for (int i = 0; i < 5; i++) { new Thread(()->{ threadLo.setContent(Thread.currentThread().getName()+"的数据"); System.out.println("------------"); System.out.println(Thread.currentThread().getName()+"线程的内容为"+threadLo.getContent()); }).start(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
使用ThreadLocal版的时候
public class ThreadLo { private ThreadLocal<String> threadLocal=new ThreadLocal<>(); private String content; public String getContent() { return threadLocal.get(); } public void setContent(String content) { this.threadLocal.set(content); } public static void main(String[] args) { ThreadLo threadLo = new ThreadLo(); for (int i = 0; i < 5; i++) { new Thread(()->{ threadLo.setContent(Thread.currentThread().getName()+"的数据"); System.out.println("------------"); System.out.println(Thread.currentThread().getName()+"线程的内容为"+threadLo.getContent()); }).start(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
当然了synchronized 也是可以解决问题的。但是此时就造成了线程不能并发了。
public class ThreadLo { private String content; public String getContent() { return content; } public void setContent(String content) { this.content = content; } public static void main(String[] args) { ThreadLo threadLo = new ThreadLo(); for (int i = 0; i < 5; i++) { new Thread(()->{ synchronized (threadLo){ threadLo.setContent(Thread.currentThread().getName()+"的数据"); System.out.println("------------"); System.out.println(Thread.currentThread().getName()+"线程的内容为"+threadLo.getContent()); } }).start(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
-
ThreadLocal的讲解。
答:在很早以前,threadLocal确实是在内部维持了一个map结构,这个mapkey放的是线程id,而value放的是要保存的值。从而做隔离。在java8以后翻了个个,就是在thread中维护这个threadLocalmap.相当于自己的线程,存自己的变量。也就是说由线程本身去维护这个变量。可以看ThreadLocal中的set方法。他会在set的同时,给当前线程存一份ThreadLocalMap

-
String 、Stringbuffer、Stringbuilder有什么区别?
答:
Java9改进了字符串(包括String、StringBuffer、StringBuilder)的实现。在Java9以前字符串采用char[]数组来保存字符,因此字符串的每个字符占2字节;而Java9的字符串采用byte[]数组再加一个encoding-flag字段来保存字符,因此字符串的每个字符只占1字节。所以Java9的字符串更加节省空间,字符串的功能方法也没有受到影响。
StringBuffer中它里面得方法都是由synchronized实现得。所以呢StringBuffer是线程安全得。而StringBuilder非线程安全得。 -
jvm内存模型详解。
答:jvm内存是由五个部分构成得。栈、本地方法栈、程序计数器、堆、方法区。
栈、本地方法栈、程序计数器这三个部分都是线程独占的。堆、方法区是线程共享得。栈:也叫方法栈,是线程私有的,线程在执行每个方法时都会同时创建一个栈帧,用来存储局部变量表、操作栈、动态链接、方法出口等信息。调用方法时执行入栈,方法返回时执行出栈。
本地方法栈:本地方法栈与栈类似,也是用来保存线程执行方法时的信息,不同的是,执行 Java 方法使用栈,而执行 native 方法使用本地方法栈。这个native方法也就是相当于java调用c++、c方法。
程序计数器:程序计数器保存着当前线程所执行的字节码位置,每个线程工作时都有一个独立的计数器。程序计数器为执行 Java 方法服务,执行 native 方法时,程序计数器为空。
堆:堆是JVM管理的内存中最大的一块,堆被所有线程共享,目的是为了存放对象实例,几乎所有的对象实例都在这里分配。当堆内存没有可用的空间时,会抛出OOM异常。根据对象存活的周期不同,JVM把堆内存…
方法区:方法区也是各个线程共享的内存区域,又叫非堆区。用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据,JDK1.7中的永久代和JDK1.8中的Metaspace都是… -
堆的细分。
答:堆如果再细分一下又可以细化分为3个部分:年轻代(Young)、年老代(Tenured)、永存区(Perm),其中年轻代又分为伊甸园(Eden space),幸存者0区(Survivor 0 space)和幸存者1区(Survivor 1 space)。
Young(年轻代)
Young 区被划分为三部分,Eden(伊甸园) 区和两个大小相同的 Survivor(幸存者)区,其中 Survivor 区间中,某一时刻只有其中一个是被使用的,另外一个留做垃圾收集时复制对象用(后面垃圾回收策略中会说明)。
在 Young 区间变满的时候,minor GC 就会将存活的对象移到空闲的 Survivor 区间中,根据 JVM 的策略,在经过几次垃圾收集后,仍然存活于 Survivor 的对象将被移动到 Tenured 区间。
Tenured(年老代)
Tenured 区主要保存生命周期长的对象,一般是一些老的对象,当一些对象在 Young 复制转移一定的次数以后,对象就会被转移到 Tenured 区,如果系统中用了 Application 级别的缓存,缓存中的对象往往会被转移到这一区间。
Perm(永久区)
Perm 代主要保存 class(类,包括接口等),method(方法),filed(属性) 等元数据,这部分的空间一般不会溢出,除非一次性加载了很多的类,不过在涉及到热部署的应用服务器的时候,有时候会遇到 java.lang.OutOfMemoryError : PermGen space 的错误,造成这个错误的很大原因就有可能是每次都重新部署,但是重新部署后,类的 class 没有被卸载掉,这样就造成了大量的 class 对象保存在了 perm 中,这种情况下,一般重新启动应用服务器可以解决问题。 -
jvm是如何保证内存分配中线程安全的。
答:1,堆是JVM中所有线程共享的,因此在其上进行对象内存的分配均需要进行加锁,这也导致了new对象的开销是比较大的
2、JVM为了提升对象内存分配的效率,对于所创建的线程都会分配一块独立的空间TLAB(Thread Local Allocation Buffer), 其大 小由JVM根据运行的情况计算而得,在TLAB上分配对象时不需要加锁,因此JVM在给线程的对象分配内存时会尽量的在TLAB上分配,
在这种情况下JVM中分配对象内存的性能和C基本是一样高效的,但如果对象过大的话则仍然是直接使用堆空间分配
3、TLAB仅作用于新生代的Eden Space,因此在编写Java程序时,通常多个小的对象比大的对象分配起来更加高效。
4 、所有新创建的Object 都将会存储在新生代Yong Generation中。如果Young Generation的数据在一次或多次GC后存活下来,那么将被转移到OldGeneration。 新的Object总是创建在Eden Space。
说人话就是说,除了在new的时候分配到堆中的操作加锁之外,但是这样频繁的创建对象就会造成性能的降低。其次就是tlab,就是对于方法中新建的对象,此时的对象会随着方法的开始而创建,随着方法的结束而结束,此时的对象会可能会建立在栈中,这样就可以保证线程安全也保证了性能的提高。也可以这么说就是new对象的时候不全是放在堆中,也有可能放在栈中。 -
java中锁的不同种维度的分类。
可重入锁指在同一个线程在外层方法获取锁的时候,进入内层方法会自动获取锁。JDK 中基本都是可重入锁,避免死锁的发生。上面提到的常见的锁都是可重入锁。 公平锁 / 非公平锁 公平锁,指多个线程按照申请锁的顺序来获取锁。如 java.util.concurrent.lock.ReentrantLock.FairSync 非公平锁,指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程先获得锁。如 synchronized、java.util.concurrent.lock.ReentrantLock.NonfairSync 独享锁 / 共享锁 独享锁,指锁一次只能被一个线程所持有。synchronized、java.util.concurrent.locks.ReentrantLock 都是独享锁 共享锁,指锁可被多个线程所持有。ReadWriteLock 返回的 ReadLock 就是共享锁 悲观锁 / 乐观锁 悲观锁,一律会对代码块进行加锁,如 synchronized、java.util.concurrent.locks.ReentrantLock 乐观锁,默认不会进行并发修改,通常采用 CAS 算法不断尝试更新 悲观锁适合写操作较多的场景,乐观锁适合读操作较多的场景 粗粒度锁 / 细粒度锁 粗粒度锁,就是把执行的代码块都锁定 细粒度锁,就是锁住尽可能小的代码块,java.util.concurrent.ConcurrentHashMap 中的分段锁就是一种细粒度锁 粗粒度锁和细粒度锁是相对的,没有什么标准 偏向锁 / 轻量级锁 / 重量级锁 JDK 1.5 之后新增锁的升级机制,提升性能。 通过 synchronized 加锁后,一段同步代码一直被同一个线程所访问,那么该线程获取的就是偏向锁 偏向锁被一个其他线程访问时,Java 对象的偏向锁就会升级为轻量级锁 再有其他线程会以自旋的形式尝试获取锁,不会阻塞,自旋一定次数仍然未获取到锁,就会膨胀为重量级锁 自旋锁 自旋锁是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环占有、浪费 CPU 资源- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
-
详细说明一下什么是可重入锁和什么是不可重入锁。
首先先看一段代码
这段代码讲的是方法中方法A的执行需要方法B,但是如果此时方法B也要被运行,那么如果该锁是不可重入锁就会发生死锁的现象,这个就是不可重入锁。
public class Test{ Lock lock = new Lock(); public void methodA(){ lock.lock(); ...........; methodB(); ...........; lock.unlock(); } public void methodB(){ lock.lock(); ...........; lock.unlock(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
那我们就来看看这个不可重入锁的一种实现方式。这段代码说明如果同一线程执行上面那个方法的时候,首先会在A方法开始执行阶段拿到锁,然后继续执行B方法,但是B方法的开始也需要拿到锁。所以会造成死锁的现象。
public class Lock{ private boolean isLocked = false; public synchronized void lock() throws InterruptedException{ while(isLocked){ wait(); } isLocked = true; } public synchronized void unlock(){ isLocked = false; notify(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
那我们在来看看可重入锁的情况。是如何避免死锁的发生的。
public class Lock{ boolean isLocked = false; Thread lockedBy = null; int lockedCount = 0; public synchronized void lock() throws InterruptedException{ Thread thread = Thread.currentThread(); while(isLocked && lockedBy != thread){ wait(); } isLocked = true; lockedCount++; lockedBy = thread; } public synchronized void unlock(){ if(Thread.currentThread() == this.lockedBy){ lockedCount--; if(lockedCount == 0){ isLocked = false; notify(); } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
其中上面的变量lockedCount为0的时候是获取释放锁的一个标志。细细品。这个代码完美的阐述了什么是可重入锁,和不可重入锁的情况。
- 集合初始容量以及扩容系数
arraylist 10 0.5 16 非安全
vector 10 1 20 安全的
hashset 16 1 32 非安全
hashmap 16 1 32 非安全
- 讲一下单例模式中得安全问题,这里用得是双重检验锁方式实现单例模式
public class Test2 { private Test2(){} private volatile static Test2 test2; public static Test2 getTest2(){ if(test2==null){ synchronized (Test2.class){ if(test2==null){ return new Test2(); } } } return test2; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- java中System.out.println()会影响到内存得可见性。
-
相关阅读:
一点点金融 5
模块化echarts图表
QGC 参数设置中关于param_union的使用
一、PostgreSQL软件安装
ChatGPT Word 大师
齐岳离子液体[C1MIm]SbF6/cas:885624-41-9/1,3-二甲基咪唑六氟锑酸盐
Qt资源使用的方式
【DesignMode】设计模式简介
Java 不同数据类型内容比较,是否相同
Java Web之Servlet技术
- 原文地址:https://blog.csdn.net/baidu_40492134/article/details/122856284