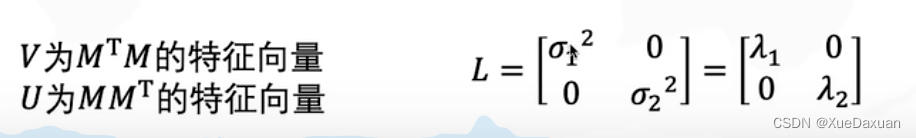-
机器学习基础知识
监督学习:回归和分类
无监督学习:聚类 用一张image去聚类然后生成一个3D空间图
强化学习:利用一个学习算法,通过一系列的决策,让他学会什么是好什么是坏。程序操控直升机,当他下降给他说:bad ,如果做了正确的事情,上升就说good,有一个reward函数,需要找一个更多的good和更少的bad。这样直升机就会学会更多的good操作来获取更多的奖励。
梯度下降:假设在一个三维小山坡,去找一个方向能让你下坡速度更快,就是梯度的方向,站到新的方向继续思考。(不同的初始起点,会造成不同的方向)

随机梯度下降:用每一个样本计算一次误差然后走一步,顺序进行。所以整个过程都是无限接近最小值。
最小二乘法:

朴素贝叶斯:朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。

经验风险最小化:
机器学习笔记8: 经验风险最小化 - 简书
 https://www.jianshu.com/p/216feebdfdb7
https://www.jianshu.com/p/216feebdfdb7特征选择:之所以要考虑特征选择,是因为机器学习经常面临过拟合的问题。 过拟合的表现是模型参数太贴合训练集数据,模型在训练集上效果很好而在测试集上表现不好,也就是在高方差。简言之模型的泛化能力差。过拟合的原因是模型对于训练集数据来说太复杂,要解决过拟合问题,一般考虑如下方法:
误差=偏差+方差,偏差=期望-真实值 方差:离散程度
- 收集更多数据
- 通过正则化引入对复杂度的惩罚
- 选择更少参数的简单模型
- 对数据降维(降维有两种方式:特征选择和特征抽取)
我们需要考虑删除哪一列信息可以使得损失最小?或者是通过变换数据就能使得损失信息更小?又如何度量信息的丢失量?原始数据的处理降维有哪些步骤?

找一个新坐标系。能够找到一个主成分一(也就是新坐标X轴)上投影分布的方差最大的时候,说明主成分一保留着更多的原始信息,这个方向就是最好的一个坐标系。



-
相关阅读:
Pwn 学习 fmt_test_2格式化字符串
18-spring 事务
JavaWeb开发了解
Unity 时间格式 12小时制与24小时制
0基础学习VR全景平台篇 第108篇:全景图细节处理(下,航拍)
网工内推 | 上市公司,云平台运维,IP认证优先,13薪
SRT服务端的搭建
在任何机器人上实施 ROS 导航堆栈的指南
QT常用快捷键
自动驾驶信息安全方案
- 原文地址:https://blog.csdn.net/daxuan1881/article/details/125394143
 https://zhuanlan.zhihu.com/p/74198735#:~:text=【机器学习】特征选择%20%28Feature%20Selection%29方法汇总%201%20收集更多数据,2%20通过正则化引入对复杂度的惩罚%203%20选择更少参数的简单模型%204%20对数据降维(降维有两种方式:特征选择和特征抽取)
https://zhuanlan.zhihu.com/p/74198735#:~:text=【机器学习】特征选择%20%28Feature%20Selection%29方法汇总%201%20收集更多数据,2%20通过正则化引入对复杂度的惩罚%203%20选择更少参数的简单模型%204%20对数据降维(降维有两种方式:特征选择和特征抽取) https://www.bilibili.com/video/BV1E5411E71z?spm_id_from=333.337.search-card.all.click&vd_source=1d56bba3304958bfdb80c190ceff8f70
https://www.bilibili.com/video/BV1E5411E71z?spm_id_from=333.337.search-card.all.click&vd_source=1d56bba3304958bfdb80c190ceff8f70
 https://www.bilibili.com/video/BV16A411T7zX?spm_id_from=333.337.search-card.all.click&vd_source=1d56bba3304958bfdb80c190ceff8f70
https://www.bilibili.com/video/BV16A411T7zX?spm_id_from=333.337.search-card.all.click&vd_source=1d56bba3304958bfdb80c190ceff8f70