-
13-Hive的基本操作和查询语法以及案例
7.2.5 Hive分区表
- 理解
- 在大数据中,最常见的思想就是分而治之,我们可以把大的文件切割划分成一个个小的文件,这样每次操作一个个小的文件就会很容易了,同样的道理,在hive当中也是支持这种思想的,就是我们可以把大的数据,按照每天或者每个小时切分成一个个的小的文件,这样去操作小的文件就会容易很多
- 假如现在我们公司一天产生3亿的数据量,那么为了方便管理和查询
- 建立分区(可以按日期 部门等具体业务分区)
- 分门别类的管理
1. 静态分区(SP)
-
创建静态分区语法
CREATE TABLE IF NOT EXISTS t_student ( sno int, sname string ) partitioned by(grade int) row format delimited fields terminated by ',';- 1
- 2
- 3
- 4
- 5
- 数据信息
1,zhangsanfeng01,1 2,zhangsanfeng02,1 3,zhangsanfeng03,1 4,zhangsanfeng04,1 5,zhangsanfeng05,1 6,zhangsanfeng06,1 7,zhangsanfeng07,2 8,zhangsanfeng08,2 9,zhangsanfeng09,2 10,zhangsanfeng10,2 11,zhangsanfeng11,2 12,zhangsanfeng12,2 13,zhangsanfeng13,3 14,zhangsanfeng14,3 15,zhangsanfeng15,3 16,zhangsanfeng16,3 17,zhangsanfeng17,3 18,zhangsanfeng18,3 19,zhangsanfeng19,4 20,zhangsanfeng20,4 21,zhangsanfeng21,4- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 载入数据
load data inpath '/yjx/student.txt' into table t_student partition(grade=1);- 1
-
创建多分区表语法
CREATE TABLE IF NOT EXISTS t_teacher ( tno int, tname string ) partitioned by(grade int,clazz int) row format delimited fields terminated by ',';- 1
- 2
- 3
- 4
- 5
注意:前后两个分区的关系为父子关系,也就是grade文件夹下面有多个clazz子文件夹。
- 数据信息
1,jueyuan01,1,1 2,jueyuan02,1,1 3,jueyuan03,1,2 4,jueyuan04,1,2 5,jueyuan05,1,3 6,jueyuan06,1,3 7,jueyuan07,2,1 8,jueyuan08,2,1 9,jueyuan09,2,2- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 载入数据
load data inpath '/yjx/teacher11.txt' into table t_teacher partition(grade=1,clazz=1);- 1
-
查询数据
- 分区表查询语句
select * from t_student where grade = 1 ;- 1
通过建立分区表,可以更加高效的查询出结果(因为已经分区过,相当于直接查找分区里的内容,而不是查询操作)
- 查看分区
show partitions t_student;- 1
- 添加分区
alter table t_student add partition (day='99990102'); alter table t_student add partition (day='99990103') location '99990103';- 1
- 2
- 删除分区
alter table salgrade2 drop partition (day='99990102');- 1
2. 动态分区(DP)
-
定义理解
- 动态分区(dynamic partition)和静态分区的主要区别是静态分区是手动指定分区,而动态分区是通过数据来进行判断
- 具体来说,静态分区的列就是在编译时期通过用户传递来决定的;动态分区只有在SQL执行时才能决定
-
开启动态分区的首先要在Hive会话中设置如下参数
set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict;- 1
- 2
-
其余的参数详细配置如下
设置为true表示开启动态分区的功能(默认为false) --hive.exec.dynamic.partition=true; 设置为nonstrict,表示允许所有分区都是动态的(默认为strict) -- hive.exec.dynamic.partition.mode=nonstrict; 每个mapper或reducer可以创建的最大动态分区个数(默认为100) 比如:源数据中包含了一年的数据,即day字段有365个值,那么该参数就需要设置成大于365,如果使用默认 值100,则会报错 --hive.exec.max.dynamic.partition.pernode=100; 一个动态分区创建可以创建的最大动态分区个数(默认值1000) --hive.exec.max.dynamic.partitions=1000; 全局可以创建的最大文件个数(默认值100000) --hive.exec.max.created.files=100000; 当有空分区产生时,是否抛出异常(默认false) -- hive.error.on.empty.partition=false;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
-
案例1:动态插入学生年级班级信息
- 创建分区表
CREATE TABLE IF NOT EXISTS t_student_d ( sno int, sname string ) partitioned by (grade int,clazz int) row format delimited fields terminated by ',';- 1
- 2
- 3
- 4
- 5
- 创建外部表
CREATE EXTERNAL TABLE IF NOT EXISTS t_student_e ( sno int, sname string, grade int, clazz int ) row format delimited fields terminated by ',' location "/yjx/student";- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
注意:如果静态分区的话,我们插入数据必须指定分区的值。如果想要插入多个班级的数据,我们要写很多的SQL并且执行很多次很麻烦,而且静态分区有可能会产生数据错误
-
静态分区导入数据
insert overwrite table t_student partition (grade=1) select * from t_student_e where grade=1;- 1
- 2
-
动态分区导入数据,动态分区会根据select的结果自动判断数据应该load到哪个分区
insert overwrite table t_student_d partition (grade,clazz) select * from t_student_e ;- 1
- 2
7.2.6 Hive载入数据和导出数据
1.Hive载入数据
-
基本语法
load data [local] inpath 'datapath' [overwrite] into table student [partition (partcol1=val1,…)];- 1
- load data
加载数据 - [local]
本地,不加Local就是从HDFS,如果是HDFS,将会删除掉原来的数据 - inpath
数据的路径 - ‘datapath’
具体的路径,要参考本地还是HDFS - [overwrite]
覆盖 - into table
加入到表 - student
表的名字 - [partition (partcol1=val1,…)]
分区
-
加载linux本地数据
-
切记必须和hiveserver2在同一个节点才可以上传否则会出现如下错误
SemanticException Line 1:23 Invalid path ‘’/root/d3.txt’': No files matching path file
-
load data local inpath ‘/root/user.txt’ into table t_user;
-
-
加载HDFS数据
- load data inpath ‘/yjx/user.txt’ into table t_user;
-
加载并覆盖已有数据
- load data inpath ‘/yjx/user.txt’ overwrite into table t_user;
-
通过查询插入数据
- 创建表
create table t_user1( id int, uname string ) row format delimited fields terminated by ',' lines terminated by '\n'; create table t_user2( id int, pwd string ) row format delimited fields terminated by ',' lines terminated by '\n';- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 插入查询结果
-将查询结果插入一张表 insert overwrite table t_user1 select id,uname from t_user; insert overwrite table t_user2 select id,pwd from t_user; --将查询结果一次性存放到多张表 from t_user insert overwrite table t_user1 select id,uname insert overwrite table t_user2 select id,pwd;- 1
- 2
- 3
- 4
- 5
- 6
- 7
2. Hive导出数据
-
将表中的数据备份
-
将查询结果存放到本地
- 现在本地创建一个存放目录
- mkdir -p /root/yjx
- 再将查询结果的数据导出到node01节点上
- insert overwrite local directory ‘/root/person_data’ select * from t_person;
- 现在本地创建一个存放目录
-
按照指定的方式将数据输出到本地
-
先创建一个存放数据的目录
- mkdir -p /root/yjx
-
再导出查询结果的数据
insert overwrite local directory '/root/yjx/person' ROW FORMAT DELIMITED fields terminated by ',' collection items terminated by '-' map keys terminated by ':' lines terminated by '\n' select * from t_person;- 1
- 2
- 3
- 4
- 5
- 6
-
将查询到的结果输出到HDFS
//创建存放数据的目录 hdfs dfs -mkdir -p /yjx/copy //导出查询结果的数据 insert overwrite directory '/yjx/copy/user' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' select * from t_user;- 1
- 2
- 3
- 4
- 5
- 6
-
-
-
或者直接用HDFS命令保存表到对应的文件夹中
//创建存放数据的目录 hdfs dfs -mkdir -p /yjx/person //使用HDFS命令拷贝文件到其他目录 hdfs dfs -cp /hive/warehouse/t_person/* /yjx/person- 1
- 2
- 3
- 4
-
将表结构和数据同时备份
-
将数据导出到HDFS
//创建存放数据的目录 hdfs dfs -mkdir -p /yjx/copy //导出查询结果的数据 export table t_person to '/yjx/copy';- 1
- 2
- 3
- 4
-
删除表结构
drop table t_person;- 1
-
恢复表结构和数据
import from '/yjx/copy';- 1
-
需要注意的是:时间不同步,会导致导入导出失败
-
7.2.7 分桶表
-
概念理解
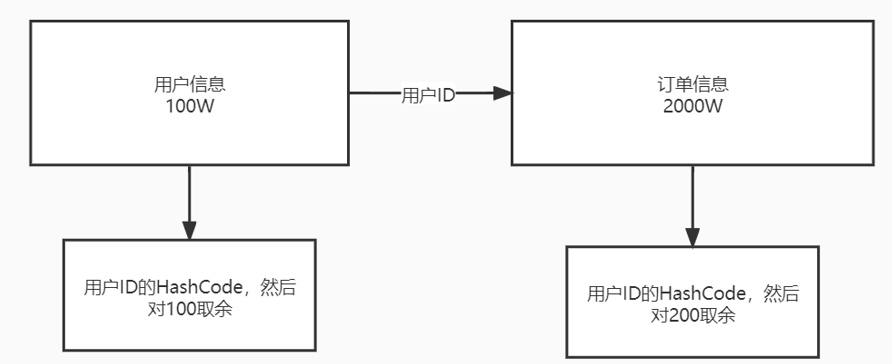
- 我们可以将Hive中的分桶原理理解成MapReduce中的HashPartitioner的原理。都是基于hash值对数据进行分桶。
- MR:按照key的hash值除以reduceTask个数进行取余(reduce_id = key.hashcode % reduce.num)
- Hive:按照分桶字段(列)的hash值除以分桶的个数进行取余(bucket_id = column.hashcode % bucket.num)
- 我们可以将Hive中的分桶原理理解成MapReduce中的HashPartitioner的原理。都是基于hash值对数据进行分桶。
-
分桶表出现的原因
- 分区提供了一个隔离数据和优化查询的便利方式,不过并非所有的数据都可以形成合理的分区,尤其是需要确定合适大小的分区划分方式
- 不合理的数据分区划分方式可能导致有的分区数据过多,而某些分区没有什么数据的尴尬情况,而分桶的出现就是解决这种数据分布不均匀的情况
-
数据分桶的原理
- 分桶就是将数据分解为更容易管理的若干部分的一种技术
- 具体就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件中
- Hive采用对列值哈希,然后除以桶的个数再求余来确定该条记录存放在哪个桶中
- bucket num = hashcode(列值bucketing_column) mod num_buckets
- 列的值做哈希取余,决定数据应该存储到哪个桶
- 例如对用户ID进行hash之后对100取余,然后得到的不同的结果分到不同的桶里
- 原理:两个数据相同,hashcode就相同,那么余数也相同,就会在一个桶里
- 分桶就是将数据分解为更容易管理的若干部分的一种技术
-
数据分桶的原理
-
方便抽样
- 是取样(sampling)更高校,在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便
-
提高join查询效率
-
获得更高的查询处理效率。桶为表加上了额外的结构,Hive在处理有些查询时能够利用这个结构。
-
具体而言,连接在两个(包含连接列)相同列上划分了桶的表,可以使用Map端连接(Map-side join)高效的实现
- 比如老师上课举的例子,对于join操作,两个表有一个相同的列,如果对这两个表都进行了桶操作,那么将保存相同列值的桶进行join操作就可以大大减少join的数据量
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uZxv4hij-1656257995434)(https://s2.loli.net/2022/06/26/PZ9H5YjfoSUtiNh.png)]
-
-
-
数据分桶实战
-
开启分桶功能
set hive.enforce.bucketing=true;
-
设置Reduce个数
我们需要确保reduce 的数量与表中的bucket 数量一致bucket个数会决定在该表或者该表的分区对应的hdfs目录下生成对应个数的文件,而mapreduce的个数是根据文件块的个数据确定的map个数。
set mapreduce.job.reduce=3;
-
创建表
CREATE TABLE t_citizen_bucket( idcard int, pname string, province int )clustered by(idcard) sorted by (pname desc) into 16 buckets row format delimited fields terminated by ',' lines terminated by '\n'; create EXTERNAL table t_citizen( idcard int, pname string, province int )row format delimited fields terminated by ',' lines terminated by '\n' location '/yjx/citizen';- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
-
数据导入(用idea得出来的数据)
for (int i = 1000; i < 10000; i++) { System.out.println(i + "," + "admin" + (new Random().nextInt(89999) + 10000) + "," + i % 34); }- 1
- 2
- 3
- 4
-
将外部表的数据导入到分桶表
insert overwrite table t_citizen_bucket select * from t_citizen ;

-
7.2.8 数据抽样算法
1. 数据块抽样
-
定义与语法规范:
- 该方式允许Hive随机抽取N行数据,数据总量的百分比(n百分比)或N字节的数据。
SELECT * FROM <Table_Name> TABLESAMPLE(N PERCENT|ByteLengthLiteral|N ROWS) s;
-
具体语法理解:
- tablesample(n percent) 根据hive表数据的大小按比例抽取数据,并保存到新的hive表中。如:
抽取原hive表中10%的数据- 注意:测试过程中发现,select语句不能带where条件且不支持子查询,可通过新建中间表或使用随机抽样解决
- create table xxx_new as select * from xxx tablesample(10 percent)
- tablesample(n M) 指定抽样数据的大小,单位为M
- tablesample(n rows) 指定抽样数据的行数,其中n代表每个map任务均取n行数据
- tablesample(n percent) 根据hive表数据的大小按比例抽取数据,并保存到新的hive表中。如:
2.桶表抽样
- 定义语法理解:
- tablesample是抽样语句,分桶语句中的分母表示的是数据将会被散列的桶的个数,分子表示将会选择的桶的个数
- 语法:TABLESAMPLE(BUCKET x OUT OF y)
- X和Y的理解
- x表示从哪个bucket开始抽取。
- 例如,table总bucket数为32,tablesample(bucket 3 out of 16)
- 表示总共抽取(32/16=)2个bucket的数据,分别为第3个bucket和第第(3+16=)19个bucket的数据
- y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。
- 例如,table总共分了64份,当y=32时,抽取(64/32=)2个bucket的数据,当y=128时,抽取(64/128=)1/2个bucket的数据
- x表示从哪个bucket开始抽取。
- 示例:
- select * from t_citizen_bucket tablesample(bucket 1 out of 16 on idcard);
- select * from t_citizen_bucket tablesample(bucket 2 out of 4 on idcard);
3. 随机抽样
-
定义语法理解:
- 使用RAND()函数和LIMIT关键字来获取样例数据,使用DISTRIBUTE和SORT关键字来保证数据是随机分散到mapper和reducer的
- ORDER BY RAND()语句可以获得同样的效果,但是性能没这么高。
-
语法:
-
SELECT * FROM <Table_Name> DISTRIBUTE BY RAND() SORT BY RAND() LIMIT
< N rows tosample>;
-
-
示例:
- select * from t_citizen_bucket DISTRIBUTE BY RAND() SORT BY RAND() LIMIT 10;
🔖 Day13-Hive的操作与优化
重点掌握
1、掌握Hive中开窗函数和自定义函数的应用
2、掌握Hive的行式存储和列式存储的区别理解内容
1、Hive的同比与环比练习 -40
2、Hive的优化 -41~42
3、Hive的配置参数 -44
4、Hive的数据倾斜 -457.3 Hive查询语法
7.3.1 Hive独占的排序
1.全局排序
-
理解:
order by会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间
-
排序语法
- 使用order by排序
- ASC升序(默认)
- DESC降序
select * from t_student_d order by sno;- 1
- 按照字段别名排序
select grade,count(sno) cs from t_student_d group by grade order by cs;- 1
- 多个列排序
select grade,count(sno) cs from t_student_d group by grade order by cs,grade;- 1
2. 局部排序
-
理解:
- sort by 不是全局排序,其在数据进入reducer前完成排序
- 如果用 sort by 进行排序,并且设置 mapred.reduce.tasks>1 ,则sort by 只保证每个reducer的输出有序,不保证全局有序
-
设置reduce的个数
set mapreduce.job.reduce=3;- 1
-
查看reduce的个数
set mapreduce.job.reduce;- 1
-
排序
select * from t_student_d sort by sname;- 1
-
将查询结果导入到文件中
insert overwrite local directory '/root/student' select * from t_student_d sort by clazz asc, grade desc;- 1
3. 分区排序
-
理解
- distribute by (字段)根据指定的字段将数据分到不同的reducer,且分发算法是hash散列
- 类似MR中partition,进行分区,结合sort by使用。(注意:distribute by 要在sort by前)
- 对于distrbute by 进行测试,一定要多分配reduce进行处理,否则无法看到distribute by的效果。
-
设置reduce个数
set mapreduce.job.reduce=7;- 1
-
排序
insert overwrite local directory '/data/student' select * from t_student_d distribute by sname;- 1
4. 分区并排序
-
理解
- cluster by(字段)除了具有Distribute by的功能外,还会对该字段进行排序
- cluster by = distribute by + sort by 只能默认升序,不能使用倒序
select * from t_student_d sort cluster by sname; select * from t_student_d distribute by sname sort by sname;- 1
- 2
7.3.2 Hive内置函数
-
内置函数
- https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
- 查看系统自带函数
- show functions;
- 显示自带函数的用法
- desc function upper;
- 详细显示自带函数用法
- desc function extended upper;
-
内置函数分类
-
UDTF函数
- 创建数据库表
create table t_movie1( id int, name string, types string ) row format delimited fields terminated by ',' lines terminated by '\n';- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 电影数据信息
1,这个杀手不太冷,剧情-动作-犯罪 2,七武士,动作-冒险-剧情 3,勇敢的心,动作-传记-剧情-历史-战争 4,东邪西毒,剧情-动作-爱情-武侠-古装 5,霍比特人,动作-奇幻-冒险- 1
- 2
- 3
- 4
- 5
- 加载数据
load data inpath '/yjx/movie1.txt' into table t_movie1;- 1
- explode 可以将一组数组的数据变成一列表
select explode(split(types,"-")) from t_movie1;- 1
- lateral view 表生成函数,可以将explode的数据生成一个列表
select id,name,type from t_movie1,lateral view explode(split(types,"-"))typetable as type;- 1
- 创建数据库表
create table t_movie2( id int, name string, type string ) row format delimited fields terminated by ',' lines terminated by '\n';- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 电影数据信息
1,这个杀手不太冷,剧情 1,这个杀手不太冷,动作 1,这个杀手不太冷,犯罪 2,七武士,动作 2,七武士,冒险 2,七武士,剧情 3,勇敢的心,动作 3,勇敢的心,传记 3,勇敢的心,剧情 3,勇敢的心,历史 3,勇敢的心,战争 4,东邪西毒,剧情 4,东邪西毒,动作 4,东邪西毒,爱情 4,东邪西毒,武侠 4,东邪西毒,古装 5,霍比特人,动作 5,霍比特人,奇幻 5,霍比特人,冒险- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 加载数据
load data inpath '/yjx/movie2.txt' into table t_movie2;- 1
- collect_set()和collect_list()都是对列转成行,区别就是list里面可重复而set里面是去
重的 - concat_ws(‘:’,collect_set(type)) ‘:’ 表示你合并后用什么分隔,
- collect_set(stage)表示要合并表中的那一列数据
select id,concat_ws(':',collect_set(type)) as types from t_movie2 group by id;- 1
7.3.3 Hive窗口函数
-
窗口函数理解
- 普通的聚合函数每组(group by)只返回一个值,某列多行的值合并为一行,如sum,count等。而开窗函数则可以为窗口中的每一行都返回一个值
- 简单理解,窗口函数的就是对查询的结果多出一列,这一列可以是是聚合值,也可以是排序值
-
语法:
-
窗口函数的分类
- 聚合开窗函数
- 排序开窗函数
-
测试数据
-- 创建表 create table t_fraction( name string, subject string, score int) row format delimited fields terminated by "," lines terminated by '\n'; -- 测试数据 fraction.txt 孙悟空,语文,10 孙悟空,数学,73 孙悟空,英语,15 猪八戒,语文,10 猪八戒,数学,73 猪八戒,英语,11 沙悟净,语文,22 沙悟净,数学,70 沙悟净,英语,31 唐玄奘,语文,21 唐玄奘,数学,81 唐玄奘,英语,23 -- 上传数据 load data inpath '/yjx/fraction.txt' into table t_fraction;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
1. 聚合开窗函数
-
sum(求和)min(最小)max(最大)avg(平均值)count(计数)
- select name,subject,score,sum(score) over() as sumover from t_fraction;
- 从表中查询姓名,学科和分数的同时求出所有的分数的和作为新的一列sumover添加到表中
- 输出结果如下
+-------+----------+--------+----------+ | name | subject | score | sumover | +-------+----------+--------+----------+ | 唐玄奘 | 英语 | 23 | 321 | | 唐玄奘 | 数学 | 81 | 321 | | 唐玄奘 | 语文 | 21 | 321 | | 沙悟净 | 英语 | 31 | 321 | | 沙悟净 | 数学 | 12 | 321 | | 沙悟净 | 语文 | 22 | 321 | | 猪八戒 | 英语 | 11 | 321 | | 猪八戒 | 数学 | 73 | 321 | | 猪八戒 | 语文 | 10 | 321 | | 孙悟空 | 英语 | 15 | 321 | | 孙悟空 | 数学 | 12 | 321 | | 孙悟空 | 语文 | 10 | 321 | +-------+----------+--------+----------+- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- select name,subject,score,avg(score) over(partition by subject) as sumover from t_fraction;
- 从表中查询姓名,学科和分数的同时按照学科分组,求出每组分数的和作为新的一列sumover添加到表中
- 输出结果如下
+-------+----------+--------+----------+ | name | subject | score | sumover | +-------+----------+--------+----------+ | 唐玄奘 | 数学 | 81 | 185 | | 沙悟净 | 数学 | 19 | 185 | | 猪八戒 | 数学 | 73 | 185 | | 孙悟空 | 数学 | 12 | 185 | | 唐玄奘 | 英语 | 23 | 80 | | 沙悟净 | 英语 | 31 | 80 | | 猪八戒 | 英语 | 11 | 80 | | 孙悟空 | 英语 | 15 | 80 | | 唐玄奘 | 语文 | 21 | 94 | | 沙悟净 | 语文 | 22 | 94 | | 猪八戒 | 语文 | 41 | 94 | | 孙悟空 | 语文 | 10 | 94 | +-------+----------+--------+----------+- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- select name,subject,score,sum(score) over() as sumover from t_fraction;
-
语法顺序
rows必须跟在order by字句之后,对排序的结果进行排序,使用固定的行数来限制分区中的数据行数量
2.排序开窗函数
-
常见排序窗口函数及区别
- RANK()排序相同时会重复,总数不会减少
- DENSE_RANK()排序相同时会重复,总数会减少
- ROW_NUMBER() 会根据顺序计算(正常排序)
-
测试排序
select name,subject,score,rank() over(partition by subject order by score desc) rp, dense_rank() over(partition by subject order by score desc) drp, row_number() over(partition by subject order by score desc) rnp from t_fraction;- 1
- 2
- 3
- 4
- 测试结果
+-------+----------+--------+-----+------+------+ | name | subject | score | rp | drp | rnp | +-------+----------+--------+-----+------+------+ | 唐玄奘 | 数学 | 81 | 1 | 1 | 1 | | 猪八戒 | 数学 | 73 | 2 | 2 | 2 | | 孙悟空 | 数学 | 73 | 2 | 2 | 3 | | 沙悟净 | 数学 | 70 | 4 | 3 | 4 | | 沙悟净 | 英语 | 31 | 1 | 1 | 1 | | 唐玄奘 | 英语 | 23 | 2 | 2 | 2 | | 孙悟空 | 英语 | 15 | 3 | 3 | 3 | | 猪八戒 | 英语 | 11 | 4 | 4 | 4 | | 沙悟净 | 语文 | 22 | 1 | 1 | 1 | | 唐玄奘 | 语文 | 21 | 2 | 2 | 2 | | 猪八戒 | 语文 | 10 | 3 | 3 | 3 | | 孙悟空 | 语文 | 10 | 3 | 3 | 4 | +-------+----------+--------+-----+------+------+- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
-
percent_rank() 计算给定行的百分比排名,可以用来计算超过了百分之多少的人
- (当前行的rank值-1)/(分组内的总行数-1)
select name,subject,score, row_number() over(partition by subject order by score) as row_number, percent_rank() over(partition by subject order by score) as percent_rank from t_fraction;- 1
- 2
- 3
- 4
- 测试结果
+-------+----------+--------+-------------+---------------------+ | name | subject | score | row_number | percent_rank | +-------+----------+--------+-------------+---------------------+ | 沙悟净 | 数学 | 70 | 1 | 0.0 | | 猪八戒 | 数学 | 73 | 2 | 0.3333333333333333 | | 孙悟空 | 数学 | 73 | 3 | 0.3333333333333333 | | 唐玄奘 | 数学 | 81 | 4 | 1.0 | | 猪八戒 | 英语 | 11 | 1 | 0.0 | | 孙悟空 | 英语 | 15 | 2 | 0.3333333333333333 | | 唐玄奘 | 英语 | 23 | 3 | 0.6666666666666666 | | 沙悟净 | 英语 | 31 | 4 | 1.0 | | 猪八戒 | 语文 | 10 | 1 | 0.0 | | 孙悟空 | 语文 | 10 | 2 | 0.0 | | 唐玄奘 | 语文 | 21 | 3 | 0.6666666666666666 | | 沙悟净 | 语文 | 22 | 4 | 1.0 | +-------+----------+--------+-------------+---------------------+- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
7.3.4 自定义函数
- 官网: https://cwiki.apache.org/confluence/display/Hive/HivePlugins
- Hive自带的函数
- max/min等,但是数量有限,自己可以通过自定义的UDF来方便的扩展
- 自定义函数
- 当Hive提供的内置函数无法满足你的业务处理需要的时候,此时可以考虑使用用户自定义函数
- UDF(User-Defined-Function) 单行函数,一进一出
- size/sqrt
- UDAF(User- Defined Aggregation Funcation) 聚集函数,多进一出。
- count/max/min/sum/avg
- UDTF(User-Defined Table-Generating Functions) 一进多出
- lateral view explode()
7.4 经典案例
7.4.1 WordCount
7.4.2 天气系统
7.4.3 好友推荐
7.4.4 基站掉话率
7.5 Hive参数和数据倾斜
7.5.1 Hive参数
1. 设置参数的三种方式
Hive当中的参数、变量都是以命名空间开头的
命名空间 读写权限 含义 hiveconf 可读写 hive_site当中的各配置变量 system 可读写 系统变量,包含JVM运行参数等,例如:system:user.name=root env 只读 环境变量,例如:env:JAVA_HOME hivevar 可读写 sql中直接使用的变量,例如:hive -d val=key 通过 $ {}方式进行引用,其中system、env下的变量必须以前缀开头
-
配置文件方式
默认配置文件:hive-default.xml
用户自定义配置文件: ${HIVE_HOME}/conf/hive-site.xml
注意:用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为
Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效。 -
命令行参数方式
启动Hive时,可以在命令行添加-hiveconf param=value来设定参数。
例如:beeline -u jdbc:hive2://yjx103:10000 -n root -hiveconf mapred.reduce.tasks=10;- 1
2. 常用的Hive设置
- hive.fetch.task.conversion=more;将hive拉取的模式设置为more模式
- 1-hive.exec.mode.local.auto 决定 Hive 是否应该自动地根据输入文件大小,在本地运行(在
GateWay运行) ; - hive.auto.convert.join :是否根据输入小表的大小,自动将 Reduce 端的 Common Join 转化为
Map Join,从而加快大表关联小表的 Join 速度。 默认:false。 - mapred.reduce.tasks :所提交 Job 的 reduer 的个数,使用 Hadoop Client 的配置。 默认
是-1,表示Job执行的个数交由Hive来分配;
mapred.map.tasks:设置提交Job的map端个数; - hive.map.aggr=true 开启map端聚合;
hive.groupby.skewindata=true :决定 group by 操作是否支持倾斜的数据。
原理是,在Group by中,对一些比较小的分区进行合并,默认是false; - hive.merge.mapredfiles :是否开启合并 Map/Reduce 小文件,对于 Hadoop 0.20 以前的版
本,起一首新的 Map/Reduce Job,对于 0.20 以后的版本,则是起使用 CombineInputFormat 的
MapOnly Job。 默认是:false; - hive.mapred.mode :Map/Redure 模式,如果设置为 strict,将不允许笛卡尔积。 默认
是:‘nonstrict’; - hive.exec.parallel :是否开启 map/reduce job的并发提交。
默认Map/Reduce job是顺序执行的,默认并发数量是8,可以配置。默认是:false; - hive.exec.dynamic.partition =true:是否打开动态分区。 需要打开,默认:false;
set hive.exec.dynamic.partition.mode=nonstirct
7.5.2 数据倾斜
1. 定义
- 数据倾斜,即单个节点任务所处理的数据量远远大于同类型任务所处理的数据量,导致该节点成为整个作业的瓶颈,这是分布式系统不可能避免的问题
2. 原因
从本质来说,导致数据倾斜有两种原因:
-
任务读取大文件,最常见的就是读取压缩的不可分割的大文件
- 当集群的数据量增长到一定规模,有些数据需要归档或者转储,这时候往往会对数据进行压缩;
- 当对文件使用GZIP压缩等不支持文件分割操作的压缩方式,在日后有作业涉及读取压缩后的文件时,该压缩文件只会被一个任务所读取。
- 如果该压缩文件很大,则处理该文件的Map需要花费的时间会远多于读取普通文件的Map时间,该Map任务会成为作业运行的瓶颈。
- 这种情况也就是Map读取文件的数据倾斜
- 为免因不可拆分大文件而引发数据读取的倾斜,在数据压缩的时候可以采用bzip2和Zip支持文件分割的压缩算法,或者使用像orc、SequenceFile等列式存储
-
任务需要处理大量相同键的数据
-
数据含有大量无意义的数据,例如空值,字符串等
-
含有倾斜数据在进行聚合计算时无法聚合中间结果,大量数据都需要经过Shuffle阶段的处理,引起数据倾斜
-
数据在计算时做多维数据集合,导致维度膨胀引起的数据倾斜
-
两个表进行join时,都含有大量相同的倾斜数据键
-
7.6 Hive企业级优化
7.6.1 Fetch
7.6.2 本地模式
7.6.3 并行执行
7.6.4 严格模式
7.6.5 JVM重用
7.6.6 表的优化(小表与大表)
7.6.7 表的优化(大表与大表)
7.6.8 mapside聚合
7.6.9 Count(Distinct)
7.6.10 防止笛卡尔积
7.7 Hive的文件存储格式
7.7.1文件存储方式
-
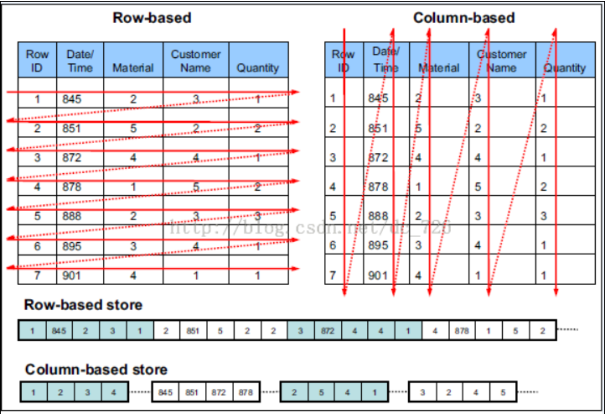
行式存储
- 把一整行存在一起,包含所有的列,数据读取的时候以行为单位读取
- 优点:存储格式简单、方便写入数据
- 缺点:不支持压缩、并且不支持列裁剪、数据分析开销较大
- 基于多个列做压缩时,由于不同列数据类型和取值范围不同,压缩比不会太高
- 当 一行中有很多列,而我们只需要其中的很少的一部分列,采用行存储的方式就不得不读取把一行中所有的列读进来,然后从中取出一些列,这样就大大降低了查询执行的效率
- 常见行式存储文件格式: TextFile、SequenceFile
- 把一整行存在一起,包含所有的列,数据读取的时候以行为单位读取
-
列式存储
- 将不同的列存放在不同的块中,每列单独存储或者某几个列作为列组存在一起,列存储在执行查询时可以避免读取不必要的列
- 优点:支持列裁剪、减少数据查询范围、数据支持压缩,节省空间
- 一般同列的数据类型一致,取值范围相对多列混合更小,在这种情况下压缩数据能达到较高的压缩比
- 缺点:写入数据相对困难、并且查询整行数据时开销相对较大
- 一行中的不同的列可能存储在不同的HDFS块上,拼接查询整个数据时开销较大
- 常见的列式存储文件格式:ORC、PARQUET、RCFILE
-
图解:

insert into t_stored_orc select * from t_stored_text;
7.7.2 文件存储格式
-
TextFile
- Hive默认的存储格式,数据不做压缩
- 可结合Gzip、Bzip2、Snappy等使用(系统自动检查,执行查询时自动解压)
- 缺点:
- 使用TextFile格式,Hive不会对数据进行切分,从而无法对数据进行并行操作
-
SequenceFile
- 定义理解
- SequenceFile是Hadoop API 提供的一种二进制文件,它将数据以<key,value>的形式序列化到文件中,具有方便、可分割、可压缩的特点
- 缺点:
- 需要一个合并文件的过程,且合并后的文件不方便查看
- 优点:
- 支持基于记录(Record)或块(Block)的数据压缩
- 支持splitable,能够作为MapReduce的输入分片
- 修改简单:主要负责修改相应的业务逻辑,而不用考虑具体的存储格式
- 定义理解
-
RCFile
-
定义理解:
- RCFile 文件格式是 FaceBook 开源的一种 Hive 的文件存储格式,首先将表分为几个行组,对每个行组内的数据进行按列存储,每一列的数据都是分开存储,正是先水平划分,再垂直划分的理念
-
特点
- RCFile 是行划分,列存储,采用游程编码,相同的数据不会重复存储,很大程度上节约了存储空间,尤其是字段中包含大量重复数据的时候。
- 懒加载
- 数据存储到表中都是压缩的数据,Hive 读取数据的时候会对其进行解压缩,但是会针对特定的查询跳过不需要的列,这样也就省去了无用的列解压缩。

-
-
ORCFile
-
定义理解:
- ORC的全称是(Optimized Row Columnar),ORC文件格式是一种Hadoop生态圈中的列式存储格式,它的产生早在2013年初,最初产生自Apache Hive,用于降低Hadoop数据存储空间和加速Hive查询速度。和Parquet类似,它并不是一个单纯的列式存储格式,仍然是首先根据行组分割整个表,在每一个行组内进行按列存储
-
相比RCFile的优点
- 在一定程度上扩展了RCFile,是对RCFile的优化
- ORC 扩展了 RCFile 的压缩,除了 Run-length(游程编码),引入了字典编码和 Bit 编码。
- 每个 task 只输出单个文件,这样可以减少 NameNode 的负载;
- 支持各种复杂的数据类型,比如:datetime,decimal,以及一些复杂类型(struct, list, map,等);
- 文件是可切分(Split)的。在 Hive 中使用 ORC 作为表的文件存储格式,不仅节省 HDFS 存储资源,查询任务的输入数据量减少,使用的 MapTask 也就减少了
-
-
Block-Compressed SequenceFile格式
参考资料:Hive 文件存储格式 - hyunbar - 博客园 (cnblogs.com)
Hive数据存储格式详细讲解(好文点赞收藏!)_KG大数据的博客-CSDN博客_数据存储格式
7.7.3 文件压缩练习
-
TextFile
- 建表
create table t_stored_text ( c1 string, c2 string, c3 string, c4 string, c5 string, c6 string, c7 string )ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 导入数据
- 加载数据
load data inpath '/yjx/test.data' into table t_stored_text ;- 1
- 查看数据大小

-
ORCFile
- 建表
create table t_stored_orc ( c1 string, c2 string, c3 string, c4 string, c5 string, c6 string, c7 string )ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS ORC ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 导入数据
- 加载数据
insert into t_stored_orc select * from t_stored_text;- 1
- 查看数据大小
7.8 HQL练习题
- 理解
-
相关阅读:
python基础07——函数,想重复使用自己的代码就写个函数吧
Mysql分页、SSM项目分页实战
鸿蒙应用开发-第一章-CSS3的grid布局
【大数据】Hive SQL语言(学习笔记)
【pytorch】关于OpenCV和PIL.Image读取图片的区别
Node 进阶学习
Python入门 | 是循环,也是遍历
SpringCloud:Gateway之限流、熔断
延时任务(三)-基于redis zset的完整实现
为互连智能合约Connected Contracts使用Axelar SDK
- 原文地址:https://blog.csdn.net/weixin_50627985/article/details/125476193
