-
[Pandas] 数据连接pd.concat

美图欣赏2022/06/25
Pandas数据可以实现纵向和横向连接,将数据连接后会形成一个新对象(Series或DataFrame)
连接是最常用的多个数据合并操作
pd.concat()是专门用于数据连接合并的函数,它可以沿着行或列进行操作,同时可以指定非合并轴的合并方式(如合集、交集等)
pd.concat()会返回一个合并后的DataFrame
语法
- pd.concat(objs, axis=0, join='outer', ignore_index=False,
- keys=None, levels=None, names=None, sort=False,
- verify_integrity=False, copy=True)
参数
objs: 需要连接的数据,可以是多个DataFrame或者Series,它是必传参数
axis: 连接轴的方法,默认值为0,即按行连接,追加在行后面;值为1时追加到列后面(按列连接:axis=1)
join: 合并方式,其他轴上的数据是按交集(inner)还是并集(outer)进行合并
ignore_index: 是否保留原来的索引
keys: 连接关系,使用传递的键作为最外层级别来构造层次结构索引,就是给每个表指定一个一级索引
names: 索引的名称,包括多层索引
verify_integrity: 是否检测内容重复;参数为True时,如果合并的数据与原数据包含索引相同的行,则会报错
copy: 如果为False,则不要深拷贝
1.按行连接
pd.concat()的基本操作可以实现df.append()功能
操作中ignore_index和sort参数的作用是一样的,axis默认取值为0,即按行连接
- import pandas as pd
- df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
- df2 = pd.DataFrame({'x':[5,6],'y':[7,8]})
- res1 = pd.concat([df1,df2])
- # 效果同上
- res2 = df1.append(df2)
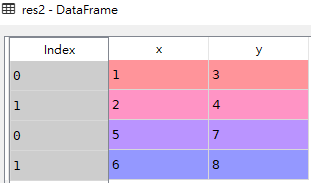
df1

df2

res1

res2
2.按列连接
如果要将多个DataFrame按列拼接在一起,可以传入axis=1参数,这会将不同的数据追加到列的后面,索引无法对应的位置上将值填充为NaN
- import pandas as pd
- df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
- df2 = pd.DataFrame({'x':[5,6,0],'y':[7,8,0]})
- res = pd.concat([df1,df2], axis=1)
df1

df2
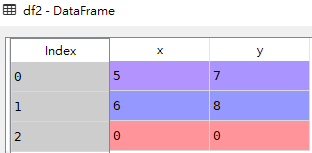
res
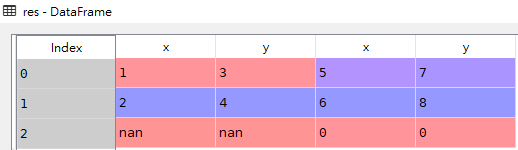
该例子中,df2比df1多一行,合并后df1的部分为NaN
3.合并交集
上述两个练习案例的连接操作会得到两个表内容的并集(默认是join='outer')
合并交集需要将join参数进行改变 join='inner'
- import pandas as pd
- df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
- df2 = pd.DataFrame({'x':[5,6,0],'y':[7,8,0]})
- # 按列合并交集
- # 传入join=’inner’取得两个DataFrame的共有部分,去除了df1没有的第三行内容
- res = pd.concat([df1,df2], axis=1, join='inner')
df1

df2

res

扩展
通过reindex()方法也可以实现取交集功能
- # 两种方法
- res1 = pd.concat([df1,df2],axis=1).reindex(df1.index)
- res2 = pd.concat([df1,df2.reindex(df1.index)],axis=1)
res1

res2

4.与序列合并
- import pandas as pd
- z = pd.Series([9,9],name='z')
- df = pd.DataFrame({'x':[1,2],'y':[3,4]})
- # 将序列加到新列
- res = pd.concat([df,z],axis=1)
z

df
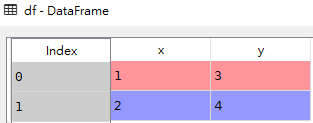
res

5.指定索引
- import pandas as pd
- df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
- df2 = pd.DataFrame({'x':[5,6],'y':[7,8]})
- # 指定索引名
- res1 = pd.concat([df1,df2], keys=['a','b'])
- # 以字典形式传入
- dict = {'a':df1, 'b':df2}
- res2 = pd.concat(dict)
- # 横向合并,指定索引
- res3 = pd.concat([df1,df2], axis=1, keys=['a','b'])
df1

df2

res1
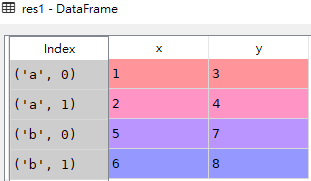
res2
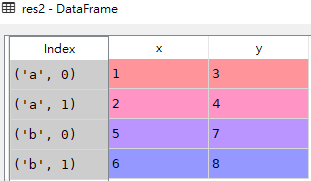
res3

-
相关阅读:
一个基本的BERT模型框架
神经网络模型的基本原理,如何建立神经网络模型
Typora 自定义样式(mac 风代码块、引用块、加粗、高亮、图片默认居左、行内代码)
JavaScript与jQuery(下篇)
《GPT与AI助手:技术进步与就业前景》
Java版工程行业管理系统源码-专业的工程管理软件- 工程项目各模块及其功能点清单
【LeetCode刷题(数据结构与算法)】:二叉树之左叶子之和
SAP S4后的一些注意点(一)(更新中)
Dubbo中@EnableDubbo注解原理
linux-自定义进程通信方式
- 原文地址:https://blog.csdn.net/Hudas/article/details/123009834