-
深入浅出计算机组成原理(五)-I/O
目录
43 | 输入输出设备:我们并不是只能用灯泡显示“0”和“1”
43 | 输入输出设备:我们并不是只能用灯泡显示“0”和“1”
接口和设备:经典的适配器模式
- 大部分的输入输出设备,都有两个组成部分。第一个是它的接口(Interface),第二个才是实际的 I/O 设备(Actual I/O Device)
- 硬件设备并不是直接接入到总线上和 CPU 通信的,而是通过接口,用接口连接到总线上,再通过总线和 CPU 通信。
- 平时听说的并行接口(Parallel Interface)、串行接口(Serial Interface)、USB 接口,都是计算机主板上内置的各个接口
- 接口本身就是一块电路板。CPU 其实不是和实际的硬件设备打交道,而是和这个接口电路板打交道。
- 设备里面有三类寄存器,其实都在这个设备的接口电路上,而不在实际的设备上。
CPU 是如何控制 I/O 设备的?
- 打印机打印:CPU发送命令和数据到接口的寄存器,接口接受到后修改状态寄存器(not ready),然后开始打印,打印完后状态改为ready,CPU才能再次发送命令和数据

信号和地址:发挥总线的价值
- 内存映射IO(Memory-Mapped I/O,简称 MMIO):计算机会把 I/O 设备的各个寄存器,以及 I/O 设备内部的内存地址,都映射到主内存地址空间里来
- 我们的 I/O 设备呢,就会监控地址线,并且在 CPU 往自己地址发送数据的时候,把对应的数据线里面传输过来的数据,接入到对应的设备里面的寄存器和内存里面来

- 端口映射 I/O(Port-Mapped I/O,简称 PMIO)或者也可以叫独立输入输出(Isolated I/O):新增in、out指令不用内存映射的方式
- 对 CPU 来说,它看到的并不是一个个特定的设备,而是一个个内存地址或者端口地址。CPU 只是向这些地址传输数据或者读取数据。所需要的指令和操作内存地址的指令其实没有什么本质差别
44 | 理解IO_WAIT:I/O性能到底是怎么回事儿?
IO 性能、顺序访问和随机访问
-
HDD机械硬盘(SATA 3.0接口)、SSD固态硬盘(PCI Express接口、SATA 3.0接口)
-
输入输出性能的核心指标:
- IOPS (每秒读写的次数):每次随机读写4kB;HDD 硬盘的 IOPS 通常也就在 100 左右
- DTR(Data Transfer Rate,数据传输率)

如何定位 IO_WAIT?
- SSD 硬盘,IOPS 也就是在 2 万左右;CPU 的主频通常在 2GHz 以上,也就是每秒可以做 20 亿次操作。
- top的wa指标:CPU 等待 IO 完成操作花费的时间占 CPU 的百分比
- iotop:各个进程的IO读写
- 在应用响应慢的时候,我们可以先通过top 命令来看服务器的整体负载,看 CPU 是否在等待 I/O 完成自己的操作。进一步地,我们可以通过 iostat 这个命令,来看到各个硬盘这个时候的读写情况。而 iotop 这个命令,能够帮助我们定位到到底是哪一个进程在进行大量的 I/O 操作。
45 | 机械硬盘:Google早期用过的“黑科技”
拆解机械硬盘
- 盘面(Disk Platter):存储数据。盘面上有一层磁性的涂层。我们的数据就存储在这个磁性的涂层上。盘面中间有一个受电机控制的转轴。这个转轴会控制我们的盘面去旋转。
- 每分钟的旋转圈数(Rotations Per Minute):7200转
- 磁头(Drive Head):读取数据。我们的数据并不能直接从盘面传输到总线上,而是通过磁头,从盘面上读取到,然后再通过电路信号传输给控制电路、接口,再到总线上的。
- 一块硬盘上下堆叠了很多个盘面,各个盘面之间是平行的。每个盘面的正反两面都有对应的磁头。
- 悬臂(Actutor Arm):把磁头定位到盘面的某个特定的磁道(Track)

- 磁道,会分成一个一个扇区(Sector)。上下平行的一个一个盘面的相同扇区呢,我们叫作一个柱面(Cylinder)。
- 一次硬盘上的随机访问,需要的时间由两个部分组成
- 平均延时(Average Latency):把我们的盘面旋转,把几何扇区对准悬臂位置的时间。根据转速推断平均为5ms
- 平均寻道时间(Average Seek Time):盘面选转之后,我们的悬臂定位到扇区的的时间。平均5ms
- 我们可以选择把顺序存放的数据,尽可能地存放在同一个柱面上。这样,我们只需要旋转一次盘面,进行一次寻道,就可以去写入或者读取,同一个垂直空间上的多个盘面的数据。
- 其实对于 HDD 硬盘的顺序数据读写,吞吐率还是很不错的,可以达到 200MB/s 左右。
46 | SSD硬盘(上):如何完成性能优化的KPI?
SSD 的读写原理
- 电容 + 电压计

- SLC 的颗粒,全称是 Single-Level Cell,也就是一个存储单元中只有一位数据。
- MLC(Multi-Level Cell)、TLC(Triple-Level Cell)以及 QLC(Quad-Level Cell):一个存储单元中根据不同的电压来表示位。

P/E 擦写问题
- 由很多个裸片(Die)叠在一起

- 对于 SSD 硬盘来说,数据的写入叫作 Program。写入不能像机械硬盘一样,通过覆写(Overwrite)来进行的,而是要先去擦除(Erase),然后再写入。
- SSD写入的基本单位是页(4k);擦除的基本单位是块(几百 KB 到几 MB )
- SSD 的使用寿命,是每一个块(Block)的擦除的次数。
- SLC 的芯片,可以擦除的次数大概在 10 万次,MLC 就在 1 万次左右,而 TLC 和 QLC 就只在几千次了
SSD 读写的生命周期

- SSD 硬盘的厂商,预留了一部分空间,专门用来做这个“磁盘碎片整理”工作的。
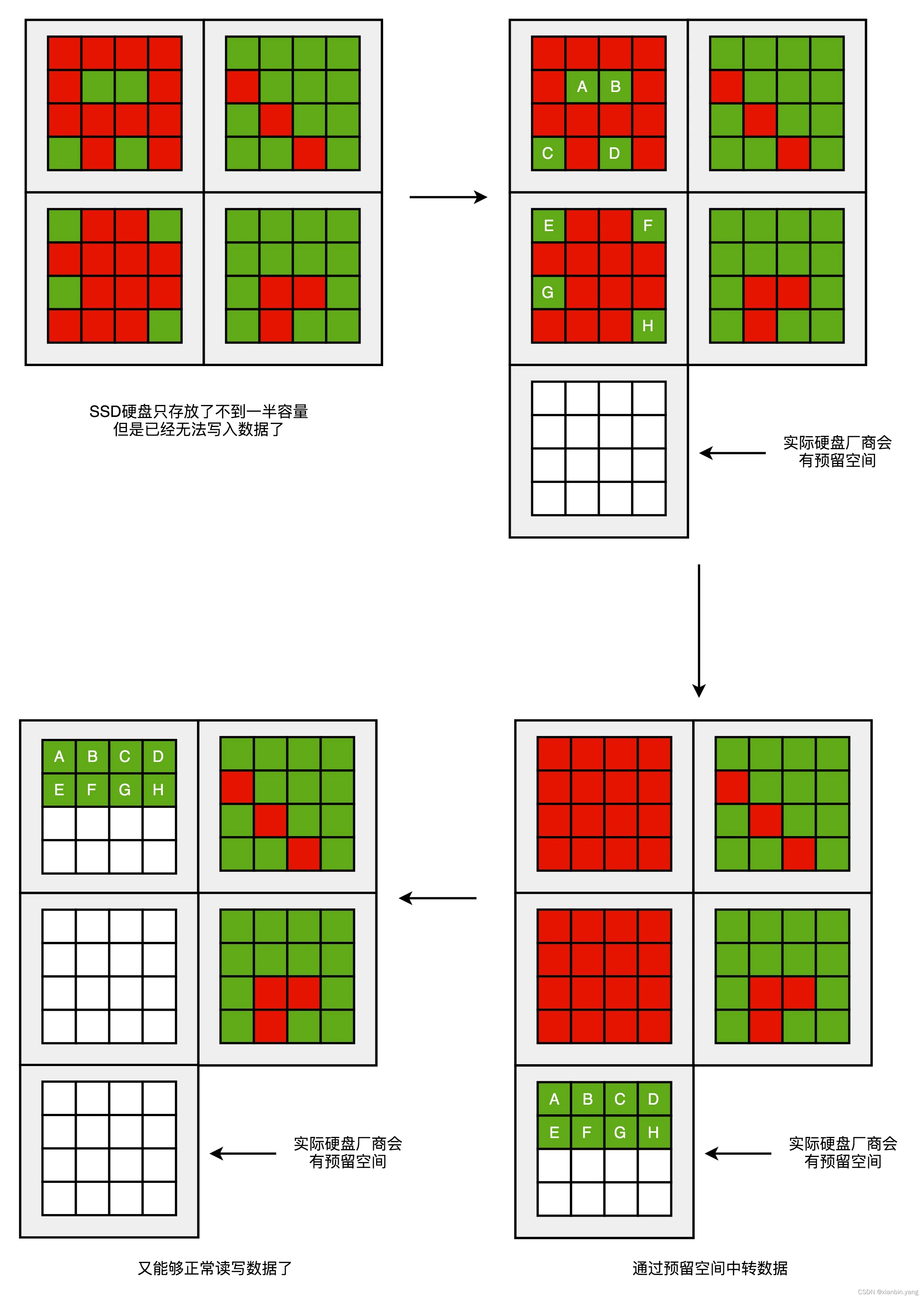
- SSD 适合读多写少的场景:适合系统盘、数据库、不适合下载数据、大数据处理
47 | SSD硬盘(下):如何完成性能优化的KPI?

磨损均衡、TRIM 和写入放大效应
- FTL 这个闪存转换层,让 SSD 硬盘各个块的擦除次数,均匀分摊到各个块上。这个策略呢,就叫作磨损均衡(Wear-Leveling)

- TRIM命令:在文件被删除的时候,让操作系统去通知 SSD 硬盘,对应的逻辑块已经标记成已删除
- 写入放大 = 实际的闪存写入的数据量 / 系统通过 FTL 写入的数据量;磁盘空间不足,导致每次写入都需要垃圾回收;解决写入放大,需要我们在后台定时进行垃圾回收
AeroSpike:如何最大化 SSD 的使用效率?
- 没有通过操作系统的文件系统。而是直接操作 SSD 里面的块和页
- 在写入数据的时候, 尽可能去写一个较大的数据块,顺序写入和避免磁盘碎片;
- 读小块,减少网络IO
- 持续地进行磁盘碎片整理,确保磁盘始终有足够的空间可以写入
48 | DMA:为什么Kafka这么快?
- 直接内存访问(Direct Memory Access)技术,来减少 CPU 等待的时间
理解 DMA,一个协处理器
- DMA 技术就是我们在主板上放一块独立的芯片。在进行内存和 I/O 设备的数据传输的时候,我们不再通过 CPU 来控制数据传输,而直接通过 DMA 控制器(DMA Controller,简称 DMAC)。这块芯片,我们可以认为它其实就是一个协处理器(Co-Processor)。
- DMAC的作用是为了解决IO操作和cpu运算能力之间的差异,减少cpu的等待。
- DMAC 最有价值的地方体现在,当我们要传输的数据特别大、速度特别快,或者传输的数据特别小、速度特别慢的时候。
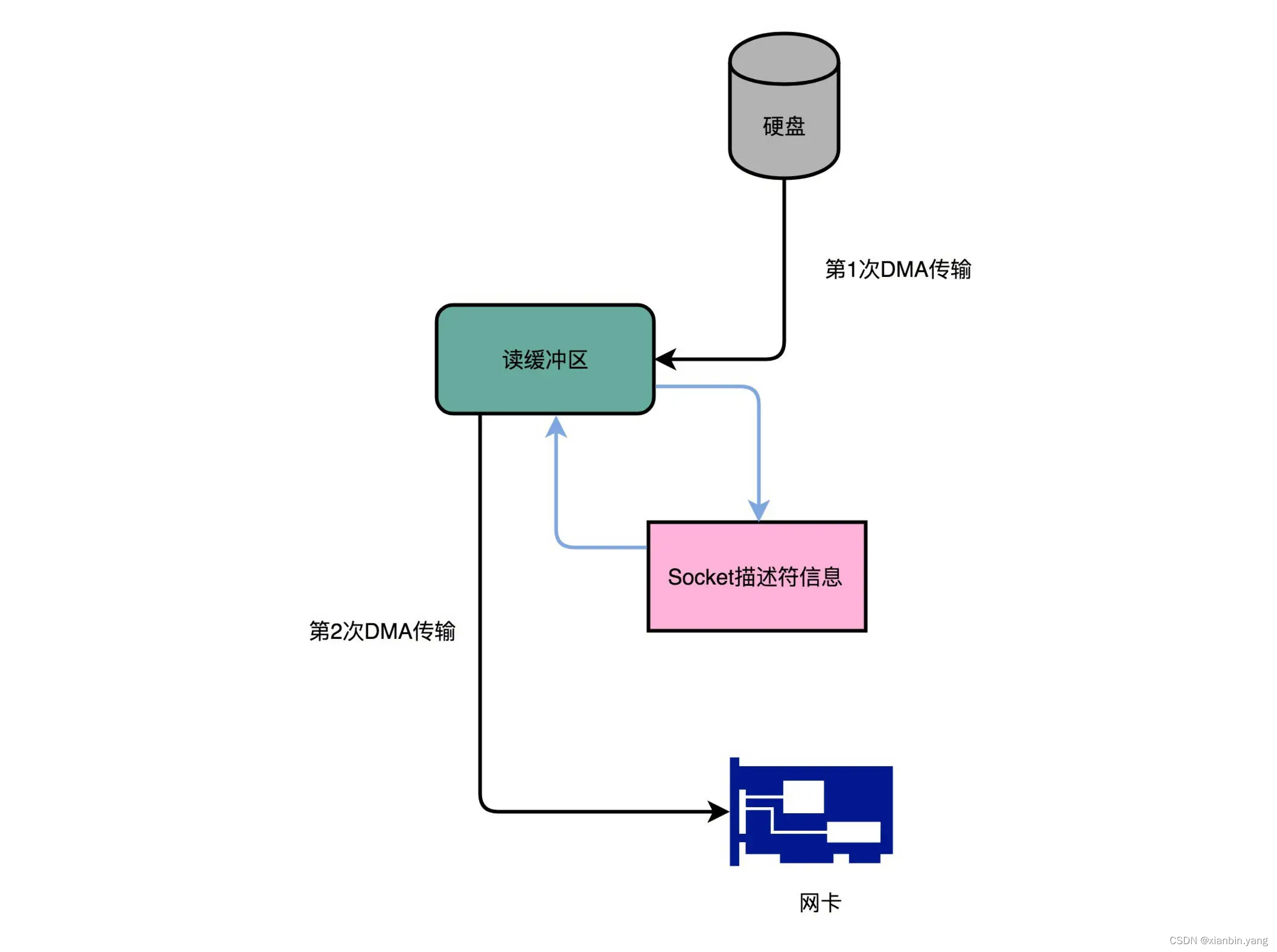
- 硬盘到内存的读写流程
- 1、cpu通知DMAC帮忙读写数据
- 2、数据从硬盘经过DMAC写到内存

- 显示器、网卡、硬盘对于数据传输的需求都不一样,所以各个设备里面都有自己的 DMAC 芯片了
- DMAC 就很有意思了,它既是一个主设备,又是一个从设备。对于 CPU 来说,它是一个从设备;对于硬盘这样的 IO 设备来说呢,它又变成了一个主设备。

为什么那么快?一起来看 Kafka 的实现原理

- java nio:FileChannel
- 在这个方法里面,我们没有在内存层面去“复制(Copy)”数据,所以这个方法,也被称之为零拷贝(Zero-Copy)。
- public static void main(String[] args) throws Exception {
- //1.5G的文件: nio是10毫秒,io是10秒
- FileInputStream ins = new FileInputStream("~/Downloads/StarRocks-2.2.1.tar.gz");
- FileOutputStream outs = new FileOutputStream("~/StarRocks-2.2.1-2.tar.gz");
- long s = System.currentTimeMillis();
- io(ins, outs);//11943
- // nio(ins, outs);10
- long e = System.currentTimeMillis();
- System.out.println(e - s);
- }
- public static void io(FileInputStream ins, FileOutputStream outs) throws Exception {
- byte[] buf = new byte[1024];
- while (ins.read(buf) != -1) {
- outs.write(buf);
- }
- }
- public static void nio(FileInputStream ins, FileOutputStream outs) throws Exception {
- ins.getChannel().transferTo(0, outs.getChannel().size(), outs.getChannel());
- }
49 | 数据完整性(上):硬件坏了怎么办?
单比特翻转:软件解决不了的硬件错误
- 无论是因为内存的制造质量造成的漏电,还是外部的射线,都有一定的概率,会造成单比特错误
- ECC 内存的全称是 Error-Correcting Code memory,中文名字叫作纠错内存

奇偶校验和校验位:捕捉错误的好办法
- 校验码位:8个数据位中1的个数是奇数还是偶数
- 只需要遍历一遍需要校验的数据,通过一个 O(N) 的时间复杂度的算法,就能把校验结果计算出来。
- md5 文件

51 | 分布式计算:如果所有人的大脑都联网会怎样?
从硬件升级到水平扩展
- 而因为我们最终必然要进行水平扩展,我们需要在系统设计的早期就基于消息传递而非共享内存来设计系统。即使这些消息只是在同一台服务器上进行传递。

-
相关阅读:
布隆过滤器(Bloom Filter)从入门到出土
Linux 进程间通信(IPC)详解:匿名管道、命名管道与共享内存
实践6 WDG
获取今天包括未来几天数据
Vue3记录
Flink流数据生成器(DataGenerator)
kernel 劫持seq_operations && 利用pt_regs
C++静态成员&友元&命名空间介绍
如何做好测试用例设计
RabbitMQ--Docker安装Rabbit单机与集群
- 原文地址:https://blog.csdn.net/laughing_yang/article/details/125457771