-
多模态数据也能进行MAE?伯克利&谷歌提出M3AE,在图像和文本数据上进行MAE!最优掩蔽率可达75%,显著高于BERT的15%...
关注公众号,发现CV技术之美
本文分享论文『Multimodal Masked Autoencoders Learn Transferable Representations』,思考:多模态数据也能进行MAE?UC Berkeley&Google提出M3AE,在图像和文本数据上进行MAE!文本的最优掩蔽率可达75%,显著高于BERT的15%!
详细信息如下:

论文链接:https://arxiv.org/abs/2205.14204
项目链接:未开源
01
摘要
构建可扩展的模型以从多样化、多模态的数据中学习仍然是一个开放的挑战。对于视觉语言数据,主要的方法是基于对比学习目标,即为每个模态训练单独的编码器。虽然有效,但对比学习方法会根据使用的数据增加引入抽样偏差,这会降低下游任务的性能。此外,这些方法仅限于成对的图像文本数据,无法利用广泛可用的未成对数据。
在本文中,作者研究了一个仅通过掩蔽token预测训练的大型多模态模型,在不使用模态特定编码器或对比学习的情况下,可以学习下游任务的可迁移表示。作者提出了一种简单且可扩展的网络架构,即多模态掩蔽自动编码器(Multimodal Masked Autoencoder,M3AE),它通过掩蔽token预测学习视觉和语言数据的统一编码器。
作者对在大规模图像文本数据集上训练的M3AE进行了实证研究,发现M3AE能够学习可迁移的表示,并能很好地迁移给下游任务。由于两种数据模式的联合训练,与标准掩蔽率为15%的BERT相比,M3AE受益于更高的文本掩蔽率(50-90%)。作者还提供了定性分析,表明学习到的表征融合了来自图像和语言的有意义信息。最后,作者展示了M3AE的可扩展性,它具有更大的模型大小和训练时间,以及在成对图像文本数据和未成对数据上训练的灵活性。
02
Motivation
随着神经结构和硬件性能的快速发展,自监督预训练在自然语言处理(NLP)和视觉方面取得了巨大的进步。基本思想通常被称为掩蔽token预测,概念上很简单:模型学习预测删除的部分数据。mask token预测为NLP和vision中的预训练提供了非常成功的方法,包括Transformer、GPT、BERT和MAE。这些经过预训练的表示方法已被证明可以很好地推广到各种下游任务。随着预训练数据多样性和模型容量的扩大,对各种下游任务的泛化仍然没有停滞的迹象。
在NLP和vision成功的推动下,人们对通过对包含图像和文本的大型和多样的多模态数据集进行训练来改进视觉表征学习产生了极大的兴趣。这些数据集,如CC12M和YFCC100,通常更具可扩展性,多样的语言数据可以提供丰富的监督,以训练更具普遍性的表示。
多模态预训练的主要范式是跨模态对比学习,如CLIP和ALIGN。这些方法表明,在庞大的图像和文本配对语料库上训练的跨模态对比学习模型能够很好地推广到各种下游任务。尽管取得了这些进展,但对比学习的一个主要限制是它需要成对的图像和文本数据,因此无法利用广泛可用的不成对数据。
此外,基于对比学习的方法对图像和文本使用单独的编码器,使得模型很难同时访问不同模态的信息。图像和文本编码器的分离阻碍了图像和文本的联合理解。为了解决视觉表征学习的上述限制,作者提出了一种简单且可扩展的架构,称为多模态掩蔽自动编码器(M3AE),用于在大型图像和语言数据上学习单个统一模型,而无需使用特定于模态的编码器或对比学习。基于MAE,M3AE纯粹通过掩蔽token预测进行训练。
本文的关键思想是将图像和文本对视为一个由图像patch和文本嵌入组成的长序列token。通过掩蔽输入图像和语言token的随机patch,并学习重建被掩蔽的像素和文本,可以简单地训练M3AE。在本文中,作者对在多模态CC12M数据集上训练的M3AE进行了实验研究,发现M3AE能够学习可迁移的表示,并能很好地转移到下游任务中,如图像分类和out-of-distribution detection。
作者发现,与仅对图像进行预训练(MAE)相比,在CC12M上对M3AE进行多模态预训练在ImageNet-1k线性分类基准上取得了显著更高的性能。M3AE的有力研究结果表明,多模态训练对于学习跨数据集的可迁移表示具有泛化优势。
令人惊讶的是,作者发现,当对语言应用高掩蔽率(75%)时,M3AE表现最好,而相比之下,像BERT这样的语言模型通常使用低掩蔽率(15%),因为语言数据具有高度的语义和信息密集性。作者认为,M3AE得益于文本上较高的掩蔽率,因为它在mask token预测期间加强了对视觉和语言的更好的联合理解。作者还提供了定性分析,表明学习到的表征融合了来自图像和语言的有意义信息。此外,作者还展示了M3AE的可扩展性,模型尺寸和训练时间更大,以及它在成对图像文本数据和未成对数据上训练的灵活性。
03
方法

多模态掩蔽自动编码器(multimodal masked autoencoder,M3AE)由一个将图像和语言映射到表示空间的编码器和一个从表示中重建原始图像和语言的解码器组成。上图展示了M3AE的主要架构。
Image-language masking
M3AE的第一步是将语言和图像输入组合成一个序列。按照标准的自然语言处理处理方法,作者将输入文本token为一系列离散token。对于图像输入,作者按照ViT的做法将其划分为规则的非重叠像素块,然后将文本token和图像patch连接成一个序列。
对于patch和token,作者从均匀分布中采样s个随机子集,不进行替换,并移除其余的子集。对文本token和图像patch都应用了高掩蔽率,以消除信息冗余,并使任务变得非常困难,无法通过从可见的相邻patch和token进行外推轻松解决。
M3AE encoder
M3AE结构由两个网络组成:编码器和解码器。编码器是一个大型Transformer,遵循ViT和BERT的架构。编码器只接受未掩蔽语言token和图像patch作为输入。对于语言token,首先将其转换为可学习的嵌入向量,然后应用1D位置编码。对于图像patch,使用可学习的线性投影将其转换为与语言嵌入具有相同维度的图像嵌入,然后按照MAE的实践应用2D位置编码。
为了区分这两种不同的模态,作者在相应的模态嵌入中添加了两个分别代表语言和图像的可学习向量。作者称之为“模态类型编码”。此外,可学习的CLS嵌入被预先设置到序列的开头。然后,通过一系列Transformer块对组合语言和图像嵌入进行处理,以获得最终表示。虽然输入由长序列的图像patch和文本token组成,但仍然可以有效地训练非常大的Transformer编码器,因为相同的编码器只在整个集合的一小部分(例如25%)上运行。
M3AE decoder
基于MAE的工作,作者在全部token上使用了一个基于Transformer的轻量级解码器,该token包括(1)编码的可见图像patch、(2)编码的可见文本token和(3)mask token。每个mask token都是一个共享的学习向量,指示是否存在要预测的缺失patch或token。
作者向这个完整集合中的所有token添加位置嵌入,以便在mask token中编码位置信息。作者还向可见token添加了一组不同的模态类型嵌入,类似于编码器。在解码器之后,使用两个线性投影输出头来计算重建。图像输出头将对应于图像patch的解码器输出投影到与原始图像块中的像素相同的维度。语言输出头将语言的解码器输出投影到token logits。这些输出头随后用于M3AE自监督训练期间的监督。
Self-supervised training of M3AE
本文的M3AE通过预测掩蔽图像块的像素值和掩蔽语言token的token概率来重建输入。对于图像重建,作者计算了像素空间中重建图像和原始图像之间的均方误差(MSE)。对于语言重建,作者在重建文本和原始文本之间应用了交叉熵损失。损失是图像损失和文本损失的加权和。
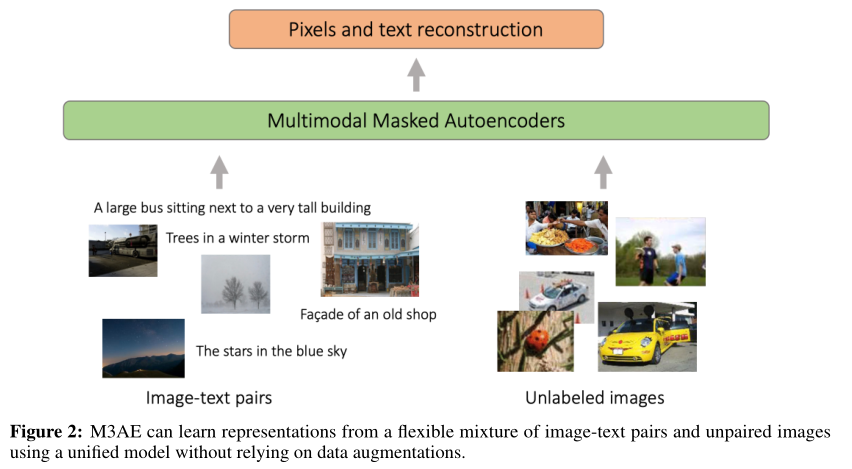
与MAE和BERT类似,作者只计算了掩蔽图像块和语言token的损失。由于M3AE通过将图像和语言数据组合成一个单一序列来统一处理它们,因此本文的模型的一个自然优势是,它可以成对和非成对数据的混合数据上以完全相同的损失进行训练(如上图所示),大大扩展了模型的适用性,超出了对比学习的可用范围。
04
实验
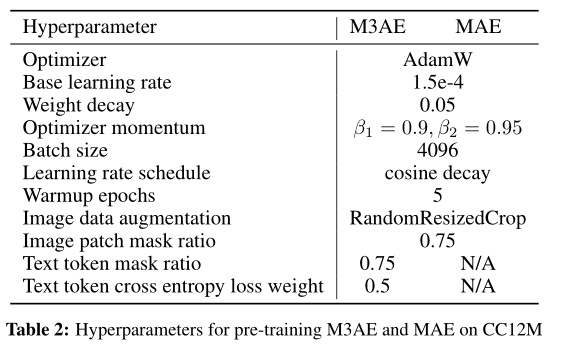
上表展示了本文模型预训练时候的超参数,其超参数大部分与MAE相同。

上图显示了M3AE和baseline之间的比较。M3AE的表现明显优于MAE近10%。CLIP是基于跨模态对比学习的强大baseline。虽然它实现了比M3AE更高的精度,但它不如本文的模型灵活,因为它只能使用成对的图像文本数据。相反,M3AE可以在不修改训练过程的情况下利用成对图像文本和未配对图像数据,如上图所示,这使得本文的模型很有可能利用未配对单模态和多模态数据的不同组合。值得注意的是,通过M3AE预训练,即使在文本标注中添加10%的噪声,也会显著提高MAE的准确性(53.3%vs45.2%)。
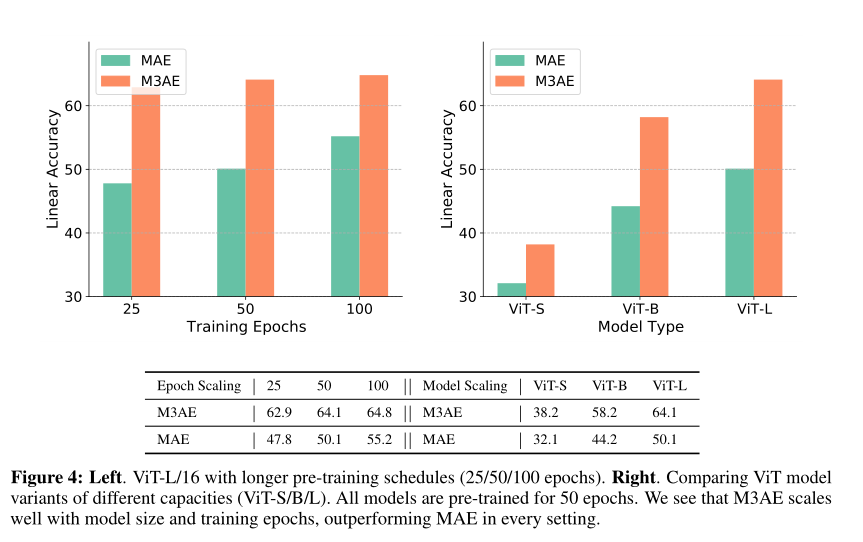
作者还研究了具有更多训练时间和更大Transformer模型的M3AE的缩放行为。作者注意到,由于CC12M比ImageNet-1K大10倍,因此在CC12M上进行100个epoch训练,梯度步长的数量相当于在ImageNet-1K上进行大约800个epoch的训练。上图显示不同训练时间和模型大小的实验结果。结果表明,M3AE在较长的训练时间和较大的模型中都能很好地扩展。

之前的一些工作表明,自监督学习方法显著提高了OOD检测性能,其中自监督预训练严重依赖于特定领域的数据扩充。因此,作者希望MAE在OOD基准上表现良好,并希望研究M3AE与MAE相比的表现。结果如上图所示,M3AE在Mahalanobis离群值得分max over softmax得分方面均优于MAE。

作者还研究了M3AE在不同文本掩蔽率下的性能。上图显示了保持图像patch mask比率固定(75%),并针对各种文本mask比率进行训练。令人惊讶的是,结果表明M3AE受益于较高的文本掩蔽率(50%-90%),而BERT的典型掩蔽率为15%。作者认为,这是两种数据模式联合训练的结果,其中掩蔽语言预测可以利用来自可见语言token和图像patch的信息。


作者对M3AE在多模态注意权重中捕捉到的内容感兴趣。为此,可视化了给定文本token和所有图像patch之间的M3AE encoder注意,以及给定图像patch和所有文本token之间的注意,结果如上图所示。
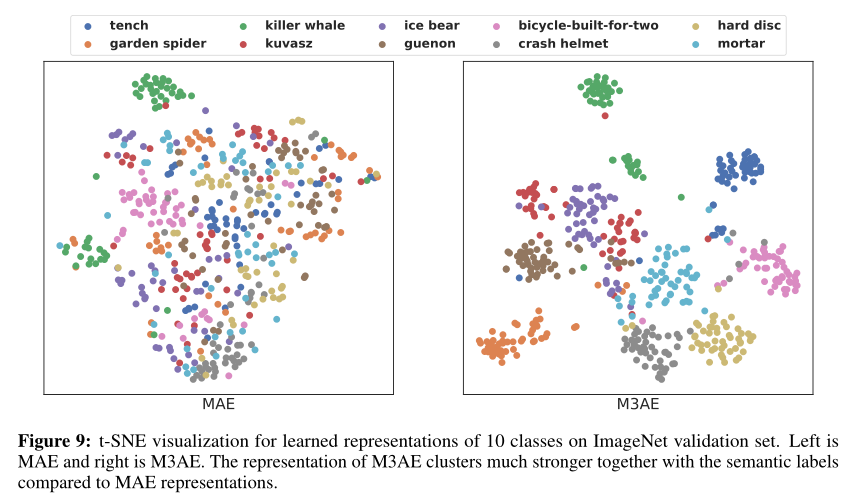
作者在上图中的ImageNet验证集上对10个类的M3AE和MAE的学习表示进行t-SNE可视化。与MAE相比,M3AE成功地将对应于相同语义标签的图像聚类在一起。

作者从CC12M和ImageNet的验证集中随机抽取图像进行重建,结果如上图所示。在每个重建图像中,都包含原始的未掩蔽token,以获得更好的视觉质量。作者观察到,本文的模型推断了CC12M和ImageNet数据集的整体重建,表明它已经学习了许多语义概念。
05
总结
在本文中,作者提出了一个简单而有效的模型M3AE,它可以从图像和语言数据中学习多模态表示,而不需要对比目标。通过使用不同的图像和语言数据进行预训练,本文的模型可以学习共享表示,从而很好地推广到下游任务。由于其灵活性和可扩展性,M3AE特别适合从超大规模的数据集学习,作者认为这种预训练好的模型可以广泛应用于许多实际的下游任务,如视觉推理、对话系统和语言引导的图像生成。
参考资料
[1https://arxiv.org/abs/2205.14204

END
欢迎加入「计算机视觉」交流群👇备注:CV

-
相关阅读:
VB.NET 三层登录系统实战:从设计到部署全流程详解
2022谷粒商城学习笔记(十六)检索服务
基于情感分析的网络舆情热点分析系统 计算机竞赛
看看Python 3.9中即将推出的令人敬畏的新功能
好用的办公软件有哪些
MySQL索引设计与选择
Cyanine5-COOH,Cy5 COOH荧光染料146368-11-8星戈瑞
探索 Wall-E 的寻路算法
EasyUI-Resizable 可调整尺寸
基于词典的正向最大匹配和逆向最大匹配中文分词
- 原文地址:https://blog.csdn.net/moxibingdao/article/details/125454468