-
[复现-ing|论文]YOLO-landmark detection
数据集:
【论文知识-补充】
可分离卷积
可分离卷积主要有两种类型:空间可分离卷积和深度可分离卷积。
空间可分离卷积:将一个卷积分成两部分(两个卷积核)的想法。之所以如此命名,是因为它主要处理图像和卷积核(kernel)的空间维度:宽度和高度。 (另一个维度,“深度”维度,是每个图像的通道数)。优点:比起卷积,空间可分离卷积要执行的矩阵乘法运算也更少。缺点:空间可分卷积的主要问题是并非所有卷积核都可以“分离”成两个较小的卷积核。 这在训练期间变得特别麻烦,因为网络可能采用所有可能的卷积核,它最终只能使用可以分成两个较小卷积核的一小部分。
 文中也给了几个例子
文中也给了几个例子深度可分离卷积:与空间可分离卷积不同,深度可分离卷积与卷积核无法“分解”成两个较小的内核。 因此,它更常用。 这是在keras.layers.SeparableConv2D或tf.layers.separable_conv2d中看到的可分离卷积的类型。|| 深度可分离卷积之所以如此命名,是因为它不仅涉及空间维度,还涉及深度维度(信道数量)。 输入图像可以具有3个信道:R、G、B。 在几次卷积之后,图像可以具有多个信道。 你可以将每个信道想象成对该图像特定的解释说明(interpret); 例如,“红色”信道解释每个像素的“红色”,“蓝色”信道解释每个像素的“蓝色”,“绿色”信道解释每个像素的“绿色”。 具有64个通道的图像具有对该图像的64种不同解释。
深度可分离卷积:一些轻量级的网络,如mobilenet中,会有深度可分离卷积depthwise separable convolution,由depthwise(DW)和pointwise(PW)两个部分结合起来,用来提取特征feature map.逐通道卷积和逐点卷积。


Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map.

扩张卷积
扩张卷积dilated conv:最早出现在DeeplLab系列中,作用是可以在不改变特征图尺寸的同时增大感受野,摈弃了pool的做法(丢失信息)。原理其实也比较简单,就是在kernel各个像素点之间加入0值像素点,变向的增大核的尺寸从而增大感受野。扩张卷积可用于图像分割、文本分析、语音识别等领域。
我们设: kernel size = k, dilation rate = d, input size = W1, output size = W2, stride=s, padding=p;

对于棋盘格问题,使用锯齿状的dilation rate如[1,2,3]
神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着它可能蕴含更为全局,语义层次更高的特征;相反,值越小则表示其所包含的特征越趋向局部和细节。因此感受野的值可以用来大致判断每一层的抽象层次。|| 卷积层(conv)和池化层(pooling)都会影响感受野,而激活函数层通常对于感受野没有影响,当前层的步长并不影响当前层的感受野,感受野和填补(padding)没有关系

 可爱万岁!
可爱万岁!
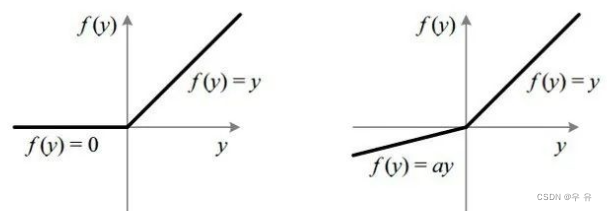
Leaky ReLU:首先ReLU对正数原样输出,负数直接置零。在正数不饱和,在负数硬饱和。|| 为了解决上述的dead ReLU现象。这里选择一个数,让负数区域不在饱和死掉。这里的斜率都是确定的。DL十大激活函数
机器学习中的数学 blog
-
相关阅读:
猿创征文 | 《深入浅出Vue.js》打卡Day2
微服务框架 案例
Exception | ShardingSphere | ShardingSphere引发的IndexOutOfBoundsException
SQL标识列实现自动编号的步骤和技巧以及优势
软考入门级了解(时间,费用,流程),无广告成分
hive最近的学习汇总-20221110
任意代码执行漏洞复现
深入理解Redis的淘汰策略
贪心算法实例(一):多任务分配问题
【牛客刷题专栏】0x02:带头节点单链表实现C数据结构栈
- 原文地址:https://blog.csdn.net/sinat_40759442/article/details/125447328