-
【Mysql】 InnoDB引擎深入- 内存结构之ChangeBuffer | Log Buffer
ChangeBuffer
ChangeBuffer是InsertBuffer 的升级版本,InsertBuffer主要是针对insert 操作进行缓存,而ChangeBuffer是针对 insert、update、delete 操作都进行缓存。
ChangeBuffer是InnoDB引擎中比较关键的特性功能。它是一种特数据的数据结构。
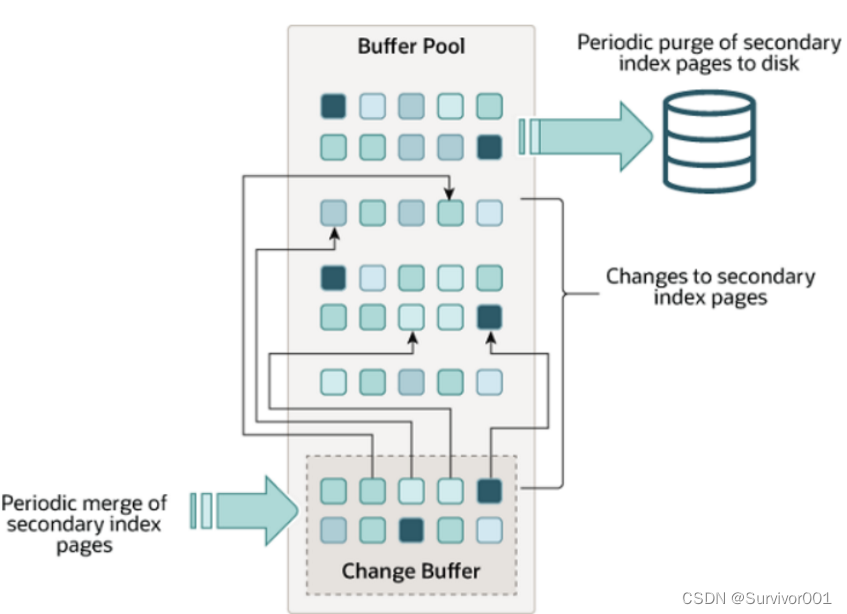
官方描述:更改缓冲区是一种特殊的数据结构,当这些页面不在 缓冲池中时 ,它会缓存对 二级索引页面的更改。可能由 、 或 操作 (DML) 导致的缓冲更改 稍后 在 页面通过其他读取操作加载到缓冲池中时被合并。
通过之前的学习,我们知道,当DML数据时,并不是直接去写入磁盘,而是先判断再缓冲池中判断是否有该页,如果有则直接修改(后续通过checkpoint刷新到磁盘中)。如果缓冲池中不存在该页,则先读取到缓冲池,然后进行修改(从磁盘离散型读取页到内存会导致性能地下)。
但是我们要知道通常来说应用程序中行记录的插入顺序时按照主键递增的顺序进行插入的,所以不需要随机磁盘读取页到内存然后插入,这时效率其实时挺快的。但是,不可能一张表上只会有一个聚集索引,更多的情况下,一张表上还会存在多个非聚集索引,它是非聚集索引顺序排序的。所以插入数据不仅会对聚集索引进行维护,仍需要对非聚集索引进行维护。
在这样的情况下进行插入数据操作时,它依旧是按照主键顺序进行顺序存放的,但是对于非聚集索引它就是不是顺序的了(某些情况下,也可能是循序的,比如非聚集索引是递增的时间之类的),此时就需要离散性地去访问磁盘中非聚集索引页,读取到内存中进行插入操作,像这种随机读取的操作就导致了性能的下降。
写入数据时,大致过程如下:
-
先判断缓冲池中是否存在该数据页 和 涉及到的非聚集索引页,如果存在直接插入。
-
如果不存在,则去磁盘读取数据页(因为插入时按照主键顺序插入的,可以很快的找到索引页,索引对于聚集索引页的维护效率很快),同时从磁盘离散性的读取非聚集索引页(因为此时对于非聚集索来说,插入并不是按照非聚集索引顺序来的,需要随机读取到索引页),所以为了优化这种情况下性能问题,使用了changebuffer。
ChangeBuffer的目的就是当对于非聚集索引的DML操作,不是每一次直接插入到索引页中,而是当缓冲池中不存在索引页时,则先放入changebuffer的数据结构中。稍后 在 页面通过其他读取操作加载到缓冲池中时被合并。 通常能将多个插入合并到一个操作中,同时也避免了频繁的IO操作,提高了性能。
InnoDB引擎会使用ChangeBuffer的条件:
-
索引是辅助索引:这个不需要再解释了....
-
索引不是唯一的:因为如果索引是唯一的,那么再插入时必然少不了唯一性的校验的操作,即少不了离散型访问索引页的操作,这样ChangeBuffer 就失去了意义,因为它本身就是为了避免离散读取操作。
Log Buffer
重做日志(redo Log):重做日志是一种基于磁盘的数据结构,用于在崩溃恢复期间纠正由不完整事务写入的数据。
Log Buffer是保存要写入磁盘日志文件的数据的内存区域。也就是说,当发生DML操作时,会先写入Log Buffer中,其内容会定期的刷新到磁盘日志文件。
-
-
相关阅读:
Elasticsearch(十五)搜索---搜索匹配功能⑥--基于地理位置查询
卡塔尔.巴林:海外媒体投放-宣发.发稿效果显著提高
vue3 ref和reactive使用watch属性的方法和区别
隔离出来的“陋室铭”
react中遇到的分页问题
设计模式学习笔记(四)单例模式的实现方式和使用场景
【论文阅读】DPLVO: Direct Point-Line Monocular Visual Odometry
【无标题】
typescript中interface和type学习
List接口(集合)
- 原文地址:https://blog.csdn.net/qq_31142237/article/details/125448756