-
机器学习(7)——特征工程(1)
目录
特征工程是机器学习数据准备过程的核心任务,主要通过变换数据集的特征空间,从而提高数据集的预测建模性能。
首先导入库和相关模块:
- ## 图像显示中文的问题
- import matplotlib
- matplotlib.rcParams['axes.unicode_minus']=False
- import seaborn as sns
- sns.set(font= "Kaiti",style="ticks",font_scale=1.4)
- ## 导入会使用到的库
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- from mpl_toolkits.mplot3d import Axes3D
- from sklearn import preprocessing
- from scipy.stats import boxcox
- import re
- from sklearn.metrics.pairwise import cosine_similarity
- from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
以下程序需要使用的数据文件:
链接:https://pan.baidu.com/s/1Oz5VdQ82Pk3KFGKkaWOAMg
提取码:whj61 特征变换
特征变换的主要内容是针对一个特征,使用合适的方法,对数据的分布、尺度等进行变换,以满足建模时对数据的需求。特征变换可以分为数据的无量纲化处理和数据特征变换等。
1.1 数据的无量纲化处理
数据的无量纲化处理常用的方法有数据标准化、数据缩放、数据归一化等方式。
下面使用鸢尾花数据集的4个数值特征为例,介绍如何进行数据无量纲化处理,并将数据处理前后的结果可视化之后进行对比分析:
- ## 使用鸢尾花数据来演示
- Iris = pd.read_csv("E:/PYTHON/Iris.csv")
- Iris2 = Iris.drop(["Id","Species"],axis = 1)
- print(Iris2.head())
运行结果如下:
- SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm
- 0 5.1 3.5 1.4 0.2
- 1 4.9 3.0 1.4 0.2
- 2 4.7 3.2 1.3 0.2
- 3 4.6 3.1 1.5 0.2
- 4 5.0 3.6 1.4 0.2
数据变量
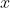 标准化的公式
标准化的公式 ,即每个数值减去变量的均值后再除以标准差。可以通过sklearn库中的preprocessing模块的scale()和StandardScale()函数来完成,其中会通过with_mean和with_std两个参数来控制是否减去均值和是否除以标准差。
,即每个数值减去变量的均值后再除以标准差。可以通过sklearn库中的preprocessing模块的scale()和StandardScale()函数来完成,其中会通过with_mean和with_std两个参数来控制是否减去均值和是否除以标准差。- ## 使用鸢尾花数据来演示
- Iris = pd.read_csv("E:/PYTHON/Iris.csv")
- Iris2 = Iris.drop(["Id","Species"],axis = 1)
- ## 将4个数值变量进行标准化,并可视化标准化前后的数据变化情况
- ## 只减去均值
- data_scale1 = preprocessing.scale(Iris2,with_mean = True,with_std=False)
- ## 减去均值后除以标准差
- data_scale2 = preprocessing.scale(Iris2,with_mean = True,with_std=True)
- ## 另一种减去均值后除以标准差的方式
- data_scale3 = preprocessing.StandardScaler(with_mean = True,with_std=True).fit_transform(Iris2)
- ## 将获得的结果使用箱线图进行可视化分析
- ## 可视化原始数据和变换后的数据分布
- labs = Iris2.columns.values
- plt.figure(figsize = (16,10))
- plt.subplot(2,2,1)
- plt.boxplot(Iris2.values,notch=True,labels = labs)
- plt.grid()
- plt.title("原始数据")
- plt.subplot(2,2,2)
- plt.boxplot(data_scale1,notch=True,labels = labs)
- plt.grid()
- plt.title("with_mean = True,with_std=False")
- plt.subplot(2,2,3)
- plt.boxplot(data_scale2,notch=True,labels = labs)
- plt.grid()
- plt.title("with_mean = True,with_std=True")
- plt.subplot(2,2,4)
- plt.boxplot(data_scale3,notch=True,labels = labs)
- plt.grid()
- plt.title("with_mean = True,with_std=True")
- plt.subplots_adjust(wspace = 0.1)
- plt.show()
运行结果如下:

图中的4幅子图分别为原始数据、原始数据减去均值、 原始数据减去均值后除以标准差和原始数据减去均值后除以标准差(这两幅图竟然一样)。对比分析可以发现,只减去均值的数据分布和原始数据一致,只是取值范围发生了变化;减去均值后除以标准差的数据和原始数据相比,不仅在取值范围上发生了变化,每个数据的分布也发生了变化。
常用的数据缩放方式为min-max标准化,可以将数据缩放到指定的空间,例如,0~1标准化时将数据缩放到0~1,计算公式为:
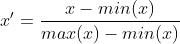 。针对相关变换可以使用preprocessing模块下的MinMaxScale()来完成,并且可以使用feature_range参数指定缩放范围。下面使用鸢尾花数据集的4个数值特征为例,分别将数据缩放到0~1和1~10,并可视化出数据的分布情况:
。针对相关变换可以使用preprocessing模块下的MinMaxScale()来完成,并且可以使用feature_range参数指定缩放范围。下面使用鸢尾花数据集的4个数值特征为例,分别将数据缩放到0~1和1~10,并可视化出数据的分布情况:- ## 将数据说缩放到指定的区间
- data_minmax1 = preprocessing.MinMaxScaler(feature_range = (0,1)).fit_transform(Iris2)
- data_minmax2 = preprocessing.MinMaxScaler(feature_range = (1,10)).fit_transform(Iris2)
- ## 可视化数据缩放后的结果
- labs = Iris2.columns.values
- plt.figure(figsize = (50,6))
- plt.subplot(1,3,1)
- plt.boxplot(Iris2.values,notch=True,labels = labs)
- plt.grid()
- plt.title("原始数据")
- plt.subplot(1,3,2)
- plt.boxplot(data_minmax1,notch=True,labels = labs)
- plt.grid()
- plt.title("MinMaxScaler(feature_range = (0,1))")
- plt.subplot(1,3,3)
- plt.boxplot(data_minmax2,notch=True,labels = labs)
- plt.grid()
- plt.title("MinMaxScaler(feature_range = (1,10))")
- plt.subplots_adjust(wspace = 0.1)
- plt.show()
- ## 数据的分布趋势是不变的,但是数据的取值范围发生了改变
运行结果如下:

preprocessing模块还提供了MaxAbsScaler()函数,其通过最大绝对值缩放每个特征:
- ## 通过最大绝对值缩放每个特征
- data_maxabs = preprocessing.MaxAbsScaler().fit_transform(Iris2)
- ## 使训练集中每个特征的最大绝对值为1.0
- ## 可视化数据缩放后的结果
- labs = Iris2.columns.values
- plt.figure(figsize = (16,6))
- plt.subplot(1,2,1)
- plt.boxplot(Iris2.values,notch=True,labels = labs)
- plt.grid()
- plt.title("原始数据")
- plt.subplot(1,2,2)
- plt.boxplot(data_maxabs,notch=True,labels = labs)
- plt.grid()
- plt.title("MaxAbsScaler()")
- plt.show()
运行结果如下:
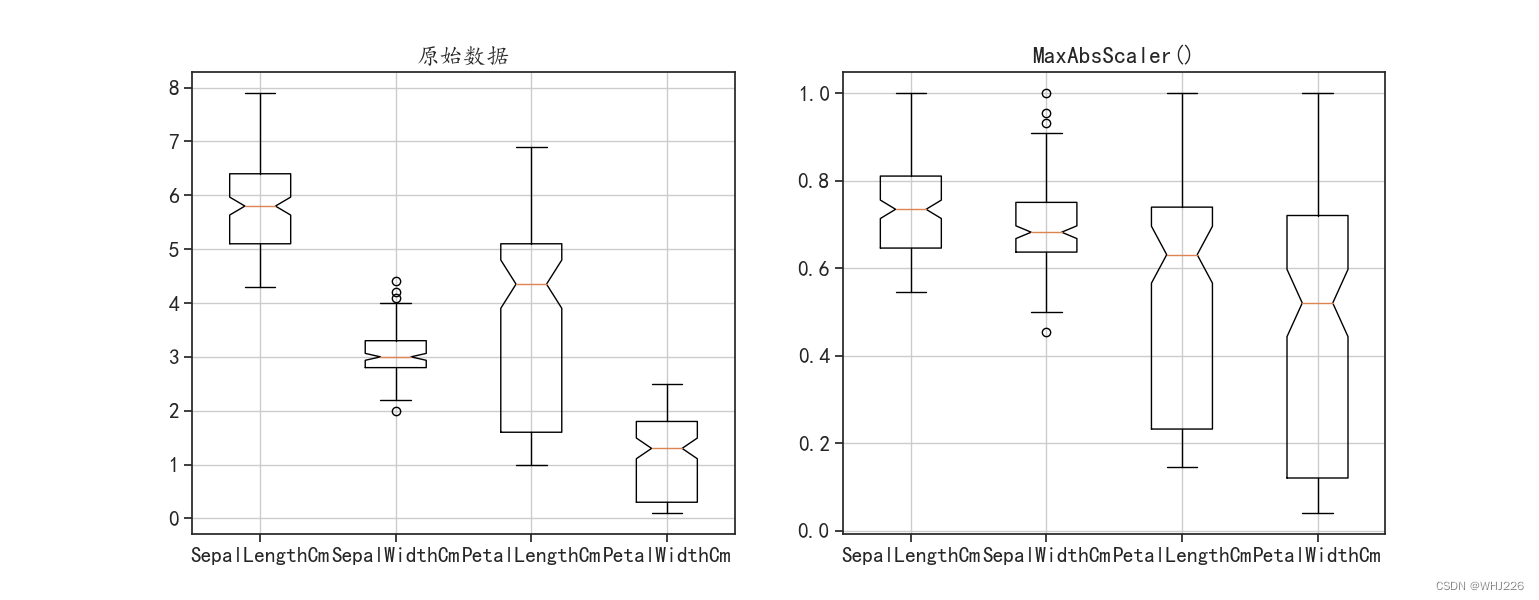
通过对比变换前后的图像可以发现,变换后的数据取值范围为0~1,但是4个特征的整体取值大小的分布和原始特征的空间分布变化比较大。
如果数据中可能存在异常值,对其进行标准化变换时,可以使用preprocessing模块的RobustScaler()方法,使用以下程序对鸢尾花数据集的4个数值特征进行相应的数据变换:
- ## 对带有异常值的数据进行标准化
- data_robs = preprocessing.RobustScaler(with_centering = True,with_scaling=True).fit_transform(Iris2)
- ## 减去均值后除以标准差
- data_scale2 = preprocessing.scale(Iris2,with_mean = True,with_std=True)
- ## 可视化数据缩放后的结果
- labs = Iris2.columns.values
- plt.figure(figsize = (25,6))
- plt.subplot(1,3,1)
- plt.boxplot(Iris2.values,notch=True,labels = labs)
- plt.grid()
- plt.title("原始数据")
- plt.subplot(1,3,2)
- plt.boxplot(data_scale2,notch=True,labels = labs)
- plt.grid()
- plt.title("StandardScaler()")
- plt.subplot(1,3,3)
- plt.boxplot(data_robs,notch=True,labels = labs)
- plt.grid()
- plt.title("RobustScaler()")
- plt.subplots_adjust(wspace = 0.07)
- plt.show()
运行结果如下:

从左到右分别是原始数据箱线图、数据标准化箱线图、数据鲁棒标准化箱线图。其中数据鲁棒标准化箱线图和数据标准化箱线图的最大差异是:数据鲁棒标准化箱线图的每个特征的取值范围更小一些。
preprocessing模块的normalize()函数,可以利用正则化参数惩罚,对数据特征进行正则化和归一化。下面对鸢尾花数据的特征分别进行
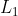 范数和
范数和 范数约束的正则化和归一化。
范数约束的正则化和归一化。- ## 正则化归一化,axis = 0表示针对特征进行操作
- data_normL1 = preprocessing.normalize(Iris2,norm = "l1",axis = 0)
- data_normL2 = preprocessing.normalize(Iris2,norm = "l2",axis = 0)
- ## 可视化数据缩放后的结果
- labs = Iris2.columns.values
- plt.figure(figsize = (15,6))
- plt.subplot(1,2,1)
- plt.boxplot(data_normL1,notch=True,labels = labs)
- plt.grid()
- plt.title("L1约束归一化(针对特征)")
- plt.subplot(1,2,2)
- plt.boxplot(data_normL2,notch=True,labels = labs)
- plt.grid()
- plt.title("L2约束归一化(针对特征)")
- plt.subplots_adjust(wspace = 0.15)
- plt.show()
运行结果如下:

从图中可以发现,两种数据变换后整体的取值范围相似,但是在某些特征的取值范围上有较明显的的差异。
针对normalize()函数进行的数据变换,参数axis=1表示针对每个样本进行操作,下面的程序对数据的样本进行了相关范数的约束操作,并可视化出数据变换后的情况。
- ## 正则化归一化,axis = 1表示针对每个样本进行操作
- data_normL1 = preprocessing.normalize(Iris2,norm = "l1",axis = 1)
- data_normL2 = preprocessing.normalize(Iris2,norm = "l2",axis = 1)
- ## 可视化数据缩放后的结果
- labs = Iris2.columns.values
- plt.figure(figsize = (15,6))
- plt.subplot(1,2,1)
- plt.boxplot(data_normL1,notch=True,labels = labs)
- plt.grid()
- plt.title("L1约束归一化(针对样本)")
- plt.subplot(1,2,2)
- plt.boxplot(data_normL2,notch=True,labels = labs)
- plt.grid()
- plt.title("L2约束归一化(针对样本)")
- plt.subplots_adjust(wspace = 0.15)
- plt.show()
运行结果如下:

以上介绍的相关方法,整体上是对数据的取值范围进行缩放,但是对数据的分布情况影响并不大。
1.2 数据特征变换
对数变换是常用的一种变换方式,很多时候数据的分布式拖尾的偏态分布,例如商品的价格,有少量的高价商品会造成其分布式左偏的,此时使用对数变换时一个不错的选择。下面将展示针对泊松分布的数据,使用对数变换,将其转化为接近正态分布的示例:
- ## 通过变换改变数据的分布等性质
- ## 对数变换
- np.random.seed(12)
- x = 1+np.random.poisson(lam = 1.5,size = 5000)+np.random.rand(5000)
- ## 对x进行对数变换
- lnx = np.log(x)
- ## 可视化变换前后的数据分布
- plt.figure(figsize=(12,5))
- plt.subplot(1,2,1)
- plt.hist(x,bins = 50)
- plt.title("原始数据分布")
- plt.subplot(1,2,2)
- plt.hist(lnx,bins = 50)
- plt.title("对数变换后数据分布")
- plt.show()
运行结果如下:
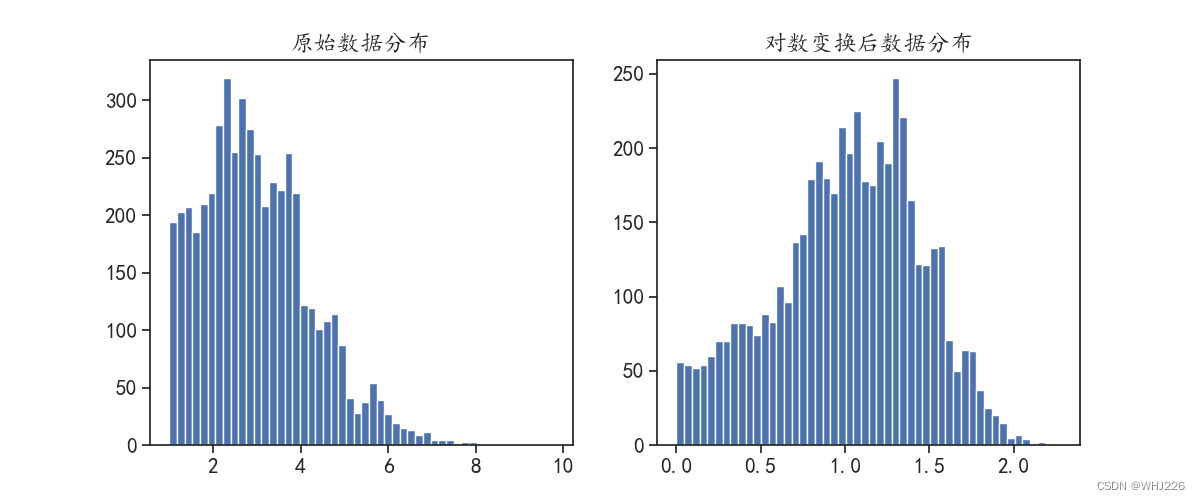
经过对数变换后,其分布更接近正态分布。
Box-Cox变换是一种自动寻找最佳正态分布变换函数的方法,其数据的计算公式:

其中在
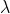 取不同值时,有不同的数据变换效果。该方法可以通过scipy.stats模块中的boxcox()函数来完成。
取不同值时,有不同的数据变换效果。该方法可以通过scipy.stats模块中的boxcox()函数来完成。- ## box-cox 变换 :自动寻找最佳正态分布变换函数的方法
- np.random.seed(12)
- x = 1+np.random.poisson(lam = 1.5,size = 5000)+np.random.rand(5000)
- ## 对x进行对数变换
- bcx1 = boxcox(x,lmbda = 0)
- bcx2 = boxcox(x,lmbda = 0.5)
- bcx3 = boxcox(x,lmbda = 2)
- bcx4 = boxcox(x,lmbda = -1)
- ## 可视化变换后的数据分布
- plt.figure(figsize=(14,10))
- plt.subplot(2,2,1)
- plt.hist(bcx1,bins = 50)
- plt.title("$ln(x)$")
- plt.subplot(2,2,2)
- plt.hist(bcx2,bins = 50)
- plt.title("$\sqrt{x}$")
- plt.subplot(2,2,3)
- plt.hist(bcx3,bins = 50)
- plt.title("$x^2$")
- plt.subplot(2,2,4)
- plt.hist(bcx4,bins = 50)
- plt.title("$ 1/x $")
- plt.subplots_adjust(hspace = 0.4)
- plt.show()
运行结果如下:

sklearn库中的preprocessing模块提供了几种将数据变换为指定数据分布的方法,例如QuantileTransformer是一种利用数据的分位数信息进行数据特征变换的方法,可以把数据变换为指定的分布。下面展示以下将数据x转换为标准正态分布并可视化:
- ## 使用分为数信息进行数据特征变换
- np.random.seed(12)
- x = 1+np.random.poisson(lam = 1.5,size = 5000)+np.random.rand(5000)
- ## 定义将数据变换为正太分布的方法
- QTn = preprocessing.QuantileTransformer(output_distribution = "normal",random_state=0)
- ## 对x进行对数变换,x要转化为二维数组
- QTnx = QTn.fit_transform(x.reshape(5000,1))
- ## 可视化变换前后的数据分布
- plt.figure(figsize=(12,5))
- plt.subplot(1,2,1)
- plt.hist(x,bins = 50)
- plt.title("原始数据分布")
- plt.subplot(1,2,2)
- plt.hist(QTnx,bins = 50)
- plt.title("变换后数据分布")
- plt.show()
运行结果如下:

2 特征
特征构建的主要目的是生成新的特征,而针对不同类型的特征,有多种方式可以生成新特征。
2.1 分类特征重新编码
针对类别标签数据,常用的方法是将其编码为常数,可以使用preprocessing模块中的QrdinalEncoder(),如下:
- ## 准备类别标签数据
- np.random.seed(12)
- label = np.random.choice(Iris.Species.values,size = 4,replace = False)
- label = label.reshape(-1,1)
- print("label:",label)
- ## 分类特征编码为常数
- OrdE = preprocessing.OrdinalEncoder()
- label_OrdE = OrdE.fit_transform(label)
- print("分类特征编码为常数:\n",label_OrdE)
运行结果如下:
- label: [['setosa']
- ['virginica']
- ['setosa']
- ['versicolor']]
- 分类特征编码为常数:
- [[0.]
- [2.]
- [0.]
- [1.]]
从运行结果可以看出,类别Iris-setosa被编码为0,类别Iris-virginica被编码为2,类别Iris-versicolor被编码为1。
离散特征可以通过preprocessing模块中的LabelEncoder(),将其编码为0~n-1的整数,或者使用OneHotEncoder()对特征进行One-Hot编码,如下:
- ## 分类特征编码为0~n-1的整数
- le = preprocessing.LabelEncoder()
- label_le = le.fit_transform([1,2,3,10,10])
- print("编码为0~n-1的整数:",label_le)
运行结果如下:
编码为0~n-1的整数: [0 1 2 3 3]对变量[1,2,3,10,10]进行LabelEncoder()操作后,数据重新编码后成了向量[0 1 2 3 3]。
- ## 准备类别标签数据
- np.random.seed(12)
- label = np.random.choice(Iris.Species.values,size = 4,replace = False)
- label = label.reshape(-1,1)
- ## One-Hot编码
- OneHotE = preprocessing.OneHotEncoder()
- label_OneHotE = OneHotE.fit_transform(label)
- print("One-Hot编码:\n",label_OneHotE.toarray())
运行结果如下:
- One-Hot编码:
- [[1. 0. 0.]
- [0. 0. 1.]
- [1. 0. 0.]
- [0. 1. 0.]]
使用OneHotEncoder()对特征进行One-Hot编码后,输出一个n×3的矩阵,其中[[1. 0. 0.]、
[0. 0. 1.]、 [0. 1. 0.]]分别表示3种类别标签。preprocessing模块还提供了LabelBinarizer(),可以对类别标签二值化,使用方式如下:
- ## 准备类别标签数据
- np.random.seed(12)
- label = np.random.choice(Iris.Species.values,size = 4,replace = False)
- label = label.reshape(-1,1)
- ## One-Hot编码
- OneHotE = preprocessing.OneHotEncoder()
- ## 以one vs all 的方式对标签进行二值化
- LB = preprocessing.LabelBinarizer()
- label_LB = OneHotE.fit_transform(label)
- print("one vs all的方式对标签二值化:\n",label_LB.toarray())
运行结果如下:
- one vs all的方式对标签二值化:
- [[1. 0. 0.]
- [0. 0. 1.]
- [1. 0. 0.]
- [0. 1. 0.]]
针对分类问题中的多标签预测,可以使用preprocessing模块中的MultiLabelBinarizer()。其输出结果可以理解为:先将每一个单独的标签进行One-Hot编码,如果一个样本由多个标签表示,那么就把它们对应的One-Hot编码相加,如下:
- ## 对多标签类别进行编码
- mlb = preprocessing.MultiLabelBinarizer()
- label_mlb = mlb.fit_transform([("A", "B"), ("B","C"), ("D")])
- print("多标签类别编码:\n",label_mlb)
运行结果如下:
- 多标签类别编码:
- [[1 1 0 0]
- [0 1 1 0]
- [0 0 0 1]]
2.2 数值特征重新编码
多项式特征经常用来生成数值特征,针对一个变量
的多项式特征,通常对其进行幂运算,获取![\left [ x,x^{2},x^{3},\cdots \right ]](https://1000bd.com/contentImg/2022/06/26/202140384.gif) 。多项式特征可以使用sklearn库中的preprocessing模块中的PolynomialFeatures函数来完成,下面给出一个最多获取3次幂多项式特征的计算方式,如下:
。多项式特征可以使用sklearn库中的preprocessing模块中的PolynomialFeatures函数来完成,下面给出一个最多获取3次幂多项式特征的计算方式,如下:- ## 生成新的特征,针对单个变量多项式特征
- X = np.arange(1,5).reshape(-1,1)
- polyF = preprocessing.PolynomialFeatures(degree=3,include_bias=False)
- polyFX = polyF.fit_transform(X)
- print(polyFX)
运行结果如下:
- [[ 1. 1. 1.]
- [ 2. 4. 8.]
- [ 3. 9. 27.]
- [ 4. 16. 64.]]
多个变量的多项式特征,可以使用现有的数据特征相互结合生成新的数据特征,如特征之间的相乘组成新特征,特征的平方组成新特征,同样可以使用PolynomialFeatures函数来完成。下面的程序针对两个变量[a,b]生成多项式特征,并且指定幂为2,所以生成的polyFXm将会包括
![\left [ a,b,a^{2},a*b,b^{2} \right ]](https://1000bd.com/contentImg/2022/06/26/202142133.gif) 等变量。
等变量。- ## 生成新的特征,针对多个变量多项式特征
- ## X2 = [a,b]
- ## polyFX = [a,b,a^2,a*b,b^2]
- X2 = np.arange(1,11).reshape(-1,2)
- polyFm = preprocessing.PolynomialFeatures(degree=2,interaction_only=False,include_bias=False)
- polyFXm = polyFm.fit_transform(X2)
- print(polyFXm)
运行结果如下:
- [[ 1. 2. 1. 2. 4.]
- [ 3. 4. 9. 12. 16.]
- [ 5. 6. 25. 30. 36.]
- [ 7. 8. 49. 56. 64.]
- [ 9. 10. 81. 90. 100.]]
针对数值特征,在使用以树为基础的模型时(例如决策树等),常常需要将数值特征进行分箱操作,将其切分为一个个小的模块,每个模块使用一个离散值来表示。在对连续的数值编码进行分箱操作时,最常用的方式就是每隔一定的距离对数据进行切分。分箱操作可以使用preprocessing模块中的KBinsDiscretizer()函数,其可以通过控制参数strategy的取值,使用不同的分箱方式,例如参数strategy="quantile"表示利用分位数进行分箱;strategy="kmeans"表示每个变量执行k-均值聚类过程的分箱策略。
下面以鸢尾花的数值变量为例,利用每种分箱策略进行数据分箱,并可视化出分箱结果。
首先,使用strategy="quantile"分箱策略。在数据分箱时,使用Kbins.bin_edges_获取分箱所需要的分界线,在可视化时,第一行图像分别使用直方图可视化出4个特征的分布情况,并在直方图添加垂直线作为分界线;第二行图像则使用条形图可视化出每个箱所包含的样本数量。
- ## 使用鸢尾花数据来演示
- Iris = pd.read_csv("E:/PYTHON/Iris.csv")
- ## 连续变量分箱,使用鸢尾花数据展示
- X = Iris.iloc[:,1:5].values
- n_bin = [2,3,4,5]
- Kbins = preprocessing.KBinsDiscretizer(n_bins=n_bin, #每个变量分别分为2,3,4,5份
- encode="ordinal",#分箱后的特征编码为整数
- strategy = "quantile") ## 利用分位数的分箱策略
- X_Kbins = Kbins.fit_transform(X)
- ## 获取划分区间时的临界线
- X_Kbins_edges = Kbins.bin_edges_
- ## 对分箱前后的数据进行可视化
- plt.figure(figsize=(16,8))
- ## 可视化分箱前的特征
- for ii in range(4):
- plt.subplot(2,4,ii+1)
- plt.hist(Iris.iloc[:,ii+1],bins = 30)
- plt.title(Iris.columns[ii+1])
- ## 可视化划分箱的临界线
- edges = X_Kbins_edges[ii]
- for edge in edges:
- plt.vlines(edge,0,25,colors="r",linewidth= 3,
- linestyle='dashed')
- ## 可视化分箱后的特征
- for ii,binsii in enumerate(n_bin):
- plt.subplot(2,4,ii+5)
- ## 计算每个元素出现的次数
- barx, height = np.unique(X_Kbins[:,ii], return_counts=True)
- plt.bar(barx,height)
- plt.show()
运行结果如下:

使用下面的程序可以获得strategy="kmeans"分箱策略的结果。
- ## 连续变量分箱,使用鸢尾花数据展示
- X = Iris.iloc[:,1:5].values
- n_bin = [2,3,4,5]
- Kbins = preprocessing.KBinsDiscretizer(n_bins=n_bin, #每个变量分别分为2,3,4,5份
- encode="ordinal",#分箱后的特征编码为整数
- strategy = "kmeans")##每个变量执行k均值聚类过程的分箱策略
- X_Kbins = Kbins.fit_transform(X)
- ## 获取划分区间时的临界线
- X_Kbins_edges = Kbins.bin_edges_
- ## 对分箱前后的数据进行可视化
- plt.figure(figsize=(16,8))
- ## 可视化分箱前的特征
- for ii in range(4):
- plt.subplot(2,4,ii+1)
- plt.hist(Iris.iloc[:,ii+1],bins = 30)
- plt.title(Iris.columns[ii+1])
- ## 可视化划分箱的临界线
- edges = X_Kbins_edges[ii]
- for edge in edges:
- plt.vlines(edge,0,25,colors="r",linewidth= 3,
- linestyle='dashed')
- ## 可视化分箱后的特征
- for ii,binsii in enumerate(n_bin):
- plt.subplot(2,4,ii+5)
- ## 计算每个元素出现的次数
- barx, height = np.unique(X_Kbins[:,ii], return_counts=True)
- plt.bar(barx,height)
- plt.show()
运行结果如下:

2.3 文本数据的特征构建
文本数据作为一种非结构化数据也会经常出现在机器学习应用中。例如,对新闻的类型进行分类,判断邮件是否为垃圾邮件等。但是算法并不能理解文字的意思,因此需要使用相应的数据特征对文本数据进行表示。
首先,获取文本数据:
- ## 读取一个文本文件
- textdf = pd.read_table("E:/PYTHON/文本数据.txt",header=0)
- print(textdf)
运行结果如下:
- text
- 0 I come from China.
- 1 My maijor is math.
- 2 Life is short, I use Python.
- 3 Python is a programming language.
- 4 Python, R and Matlab, I love Python.
- 5 My maijor is computer. He maijor is computer t...
- 6 I come from Shanghai China.
- 7 Life is short and happy in time.
获取文本特征之前需要对文本数据进行预处理,保留有用的文本,剔除不必要的内容等,下面对数据进行大写字母转化为小写、剔除多余的空格和标点符号两个预处理操作:
- ## 读取一个文本文件
- textdf = pd.read_table("E:/PYTHON/文本数据.txt",header=0)
- # print(textdf)
- ## 将所有的大写字母转化为小写
- textdf["text"] = textdf.text.apply(lambda x: x.lower())
- ## 剔除多余的空格和标点符号
- textdf["text"] = textdf.text.apply(lambda x: re.sub('[^\w\s]','',x))
- print(textdf)
运行结果如下:
- text
- 0 i come from china
- 1 my maijor is math
- 2 life is short i use python
- 3 python is a programming language
- 4 python r and matlab i love python
- 5 my maijor is computer he maijor is computer te...
- 6 i come from shanghai china
- 7 life is short and happy in time
计算文本数据中的词频特征,即计算每个词语出现的次数,可以使用下面的程序进行计算,并进行可视化:
- ## 读取一个文本文件
- textdf = pd.read_table("E:/PYTHON/文本数据.txt",header=0)
- # print(textdf)
- ## 将所有的大写字母转化为小写
- textdf["text"] = textdf.text.apply(lambda x: x.lower())
- ## 剔除多余的空格和标点符号
- textdf["text"] = textdf.text.apply(lambda x: re.sub('[^\w\s]','',x))
- # print(textdf)
- ## 统计词频
- text = " ".join(textdf.text) # 拼接字符串
- text = text.split(" ") # 分割字符串
- ## 计算每个词出现的次数
- textfre = pd.Series(text).value_counts()
- ## 使用条形图可视化词频
- textfre.plot(kind = "bar",figsize = (10,6),rot = 90)
- plt.ylabel("频数")
- plt.xlabel("单词")
- plt.title("文本数据的词频条形图")
- plt.show()
运行结果如下:

针对一条文本数据,使用词袋模型生成一个向量,该向量可以表示文本特征,因此多个文本内容可以使用一个矩阵来表示。 词袋模型是文本表示的常用方法,该模型只关注文档中是否出现给定的单词和单词出现的频率,舍弃了文本的结构、单词出现的位置和顺序等信息。
下面利用词袋模型获取文本数据的文档——词项的词频矩阵。
- ## 读取一个文本文件
- textdf = pd.read_table("E:/PYTHON/文本数据.txt",header=0)
- # print(textdf)
- ## 将所有的大写字母转化为小写
- textdf["text"] = textdf.text.apply(lambda x: x.lower())
- ## 剔除多余的空格和标点符号
- textdf["text"] = textdf.text.apply(lambda x: re.sub('[^\w\s]','',x))
- # print(textdf)
- # ## 统计词频
- # text = " ".join(textdf.text) # 拼接字符串
- # text = text.split(" ") # 分割字符串
- # ## 计算每个词出现的次数
- # textfre = pd.Series(text).value_counts()
- # ## 使用条形图可视化词频
- # textfre.plot(kind = "bar",figsize = (10,6),rot = 90)
- # plt.ylabel("频数")
- # plt.xlabel("单词")
- # plt.title("文本数据的词频条形图")
- # plt.show()
- ## 词袋模型(BoW)
- ## 是用于文本表示的最简单的方法, BoW把文本转换为文档中单词出现次数的矩阵,
- ## 该模型只关注文档中是否出现给定的单词和单词出现频率,而舍弃文本的结构、单词出现的顺序和位置
- cv = CountVectorizer(stop_words = "english") # 处理时会去除停用词
- cv_matrix = cv.fit_transform(textdf.text)
- ## 为了便于分析,将得到的结果处理为数据表
- cv_matrixdf = pd.DataFrame(data = cv_matrix.toarray(),
- columns = cv.get_feature_names())
- print(cv_matrixdf)
运行结果如下:
- china come computer happy ... short technology time use
- 0 1 1 0 0 ... 0 0 0 0
- 1 0 0 0 0 ... 0 0 0 0
- 2 0 0 0 0 ... 1 0 0 1
- 3 0 0 0 0 ... 0 0 0 0
- 4 0 0 0 0 ... 0 0 0 0
- 5 0 0 2 0 ... 0 1 0 0
- 6 1 1 0 0 ... 0 0 0 0
- 7 0 0 0 1 ... 1 0 1 0
针对获得的矩阵,可以根据不同的分析目的,使用不同的分析方法,例如,想要知道每个样本之间的相似性,可以利用上面的矩阵,计算文本之间的余弦相似性。在程序中同时将余弦相似性使用热力图进行可视化:
- ## 通过余弦相似性计算文本之间的相关系数
- from sklearn.metrics.pairwise import cosine_similarity
- textcosin = cosine_similarity(cv_matrixdf)
- ## 使用热力图可视化相关性
- plt.figure(figsize=(8,6))
- ax = sns.heatmap(textcosin,fmt=".2f",annot=True,cmap="YlGnBu")
- plt.title("文本TF特征余弦相似性热力图")
- plt.show()
运行结果如下:

从运行结果可以发现,文本0和文本6的相似性最大。
针对该数据还可以计算文本数据的文档——词项TF-IDF矩阵,TF-IDF是一种用于信息检索与数据挖掘的加权技术,经常用于评估一个词项对于一个文件集或一个语料库中的一份文件的重要程度。词的重要性随着他在文件中出现的次数成正比增加,但会随着它在语料库中出现的频率成反比下降。
- ## 获取文本的tf-idf特征
- TFIDF = TfidfVectorizer(stop_words = "english")
- TFIDF_mat = TFIDF.fit_transform(textdf.text).toarray()
- ## 计算余弦相似性并可视化
- textcosin = cosine_similarity(TFIDF_mat)
- ## 使用热力图可视化相关性
- plt.figure(figsize=(8,6))
- ax = sns.heatmap(textcosin,fmt=".2f",annot=True,cmap="YlGnBu")
- plt.title("文本TF-IDF特征余弦相似性热力图")
- plt.show()
运行结果如下:

从运行结果可以发现,文本0和文本6的相似性还是最大。
3 特征选择
特征选择是使用某些统计方法,从数据中选择出有用的特征,把数据中无用的特征抛弃,该方法不会产生新的特征,常用的方式有基于统计方法的特征选择、利用递归消除法选择有用的特征、利用机器学习算法选择重要的特征等。本节将以一个关于酒的多分类数据集为例。
- from sklearn.feature_selection import VarianceThreshold,f_classif
- ## 导入取酒的多分类数据集,用于演示
- from sklearn.datasets import load_wine
- wine_x,wine_y = load_wine(return_X_y=True)
- print(wine_x.shape)
- print(np.unique(wine_y,return_counts = True))
运行结果如下:
- (178, 13)
- (array([0, 1, 2]), array([59, 71, 48], dtype=int64))
从运行结果来看,该数据集有178个样本、13个特征,包含3类数据,每类分别包含59、71和48个样本。
3.1 基于统计方法
基于统计方法的特征选择,常用的方法有剔除低方差特征;使用卡方值、互信息、方差分析等方式选择K个特征。
剔除低方差特征可以通过sklearn.feature_selection模块中的VarianceThreshold来完成,如下:
- from sklearn.feature_selection import VarianceThreshold,f_classif
- ## 导入取酒的多分类数据集,用于演示
- from sklearn.datasets import load_wine
- wine_x,wine_y = load_wine(return_X_y=True)
- # print(wine_x.shape)
- # print(np.unique(wine_y,return_counts = True))
- ## 删除低方差的特征
- from sklearn.feature_selection import VarianceThreshold
- VTH = VarianceThreshold(threshold = 0.5)
- VTH_wine_x = VTH.fit_transform(wine_x)
- print(VTH_wine_x.shape)
- ## 可见只保留了8个方差大于0.5的特征
运行结果如下:
(178, 8)通过下面的方式确定哪些特征被保留,再输出结果中True表示对应的特征被保留。
- ## 保留的变量
- print(VTH.variances_ > 0.5)
运行结果如下:
- [ True True False True True False True False False True False True
- True]
sklearn.feature_selection模块中提供了SelectKBest方式,其可以通过相关统计信息,从数据集中选择指定数目的特征数量,其中利用方差分析的F统计量选择5个特征的程序如下:
- from sklearn.feature_selection import VarianceThreshold,f_classif
- ## 导入取酒的多分类数据集,用于演示
- from sklearn.datasets import load_wine
- wine_x,wine_y = load_wine(return_X_y=True)
- ## 选择K个最高得分的变量,分类可使用chi2, f_classif,mutual_info_classif等
- from sklearn.feature_selection import SelectKBest, chi2, f_classif, mutual_info_classif
- ## 通过方差分析的F值选择K个变量
- KbestF = SelectKBest(f_classif, k=5)
- KbestF_wine_x = KbestF.fit_transform(wine_x,wine_y)
- print(KbestF_wine_x.shape)
运行结果如下:
(178, 5)使用SelectKBest方式,利用卡方值选择5个特征:
- ## 选择K个最高得分的变量,分类可使用chi2, f_classif,mutual_info_classif等
- from sklearn.feature_selection import SelectKBest, chi2, f_classif, mutual_info_classif
- ## 通过方差分析的F值选择K个变量
- KbestF = SelectKBest(f_classif, k=5)
- KbestF_wine_x = KbestF.fit_transform(wine_x,wine_y)
- # print(KbestF_wine_x.shape)
- ## 通过卡方值值选择K个变量
- KbestChi2 = SelectKBest(chi2, k=5)
- KbestChi2_wine_x = KbestF.fit_transform(wine_x,wine_y)
- print(KbestChi2_wine_x.shape)
运行结果如下:
(178, 5)使用SelectKBest方式,利用互相信息选择5个特征:
- ## 选择K个最高得分的变量,分类可使用chi2, f_classif,mutual_info_classif等
- from sklearn.feature_selection import SelectKBest, chi2, f_classif, mutual_info_classif
- ## 通过方差分析的F值选择K个变量
- KbestF = SelectKBest(f_classif, k=5)
- KbestF_wine_x = KbestF.fit_transform(wine_x,wine_y)
- # print(KbestF_wine_x.shape)
- ## 通过互信息选择K个变量
- KbestMI = SelectKBest(mutual_info_classif, k=5)
- KbestMI_wine_x = KbestMI.fit_transform(wine_x,wine_y)
- print(KbestMI_wine_x.shape)
运行结果如下:
(178, 5)针对回归问题的K个最高得分的选择,可以使用f_regression(回归分析的F统计量),mutual_info_regression(回归分析的互相信息)等统计量进行特征选择。
3.2 基于递归消除特征法
递归消除特征法是使用一个基模型进行多轮训练,每轮训练后,消除若干不重要的特征,再基于新的特征集进行下一轮训练。它使用模型精度来识别哪些属性(或属性组合)对预测目标属性的贡献最大,然后消除无用的特征。sklearn中提供了两种递归消除特征法,分别是递归消除特征法(RFE)和交叉递归消除特征法(RFECV)。
使用随机森林分类器作为基模型,利用递归消除特征法从数据中选择9个最佳特征,如下:
- from sklearn.feature_selection import VarianceThreshold,f_classif
- ## 导入取酒的多分类数据集,用于演示
- from sklearn.datasets import load_wine
- wine_x,wine_y = load_wine(return_X_y=True)
- ## 递归消除特征法
- ## 使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。
- ## 它使用模型精度来识别哪些属性(和属性组合)对预测目标属性的贡献最大
- from sklearn.feature_selection import RFE,RFECV
- from sklearn.ensemble import RandomForestClassifier
- model = RandomForestClassifier(random_state=0) #设置基模型为随机森林
- rfe = RFE(estimator = model,n_features_to_select = 9) #选择9个最佳特征变量
- rfe_wine_x = rfe.fit_transform(wine_x, wine_y) #进行RFE递归
- print("特征是否被选中:\n",rfe.support_)
- print("获取的数据特征尺寸:",rfe_wine_x.shape)
运行结果如下:
- 特征是否被选中:
- [ True False False True True True True False False True True True
- True]
- 获取的数据特征尺寸: (178, 9)
运行上面的程序后获得的数据集rfe_wine_x有9个特征,并且可以使用rfe。.support_输出被选中的特征,True表示对应的特征被选中。
递归消除特征法还可以使用交叉验证的方式进行特征选择。使用随机森林分类器作为基模型,然后使用5折交叉验证进行递归消除特征法的应用,同时利用参数min_features_to_select = 5指定要选择的最少特征数量。
- from sklearn.feature_selection import VarianceThreshold,f_classif
- ## 导入取酒的多分类数据集,用于演示
- from sklearn.datasets import load_wine
- wine_x,wine_y = load_wine(return_X_y=True)
- ## 递归消除特征法
- ## 使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。
- ## 它使用模型精度来识别哪些属性(和属性组合)对预测目标属性的贡献最大
- from sklearn.feature_selection import RFE,RFECV
- from sklearn.ensemble import RandomForestClassifier
- model = RandomForestClassifier(random_state=0) #设置基模型为随机森林
- rfe = RFE(estimator = model,n_features_to_select = 9) #选择9个最佳特征变量
- rfe_wine_x = rfe.fit_transform(wine_x, wine_y) #进行RFE递归
- # print("特征是否被选中:\n",rfe.support_)
- # print("获取的数据特征尺寸:",rfe_wine_x.shape)
- ## True表示对应的特征被选中
- #设置基模型为随机森林
- model = RandomForestClassifier(random_state=0)
- # 借助5折交叉验证最少选择5个最佳特征变量
- rfecv = RFECV(estimator = model,min_features_to_select = 5, cv = 5)
- rfecv_wine_x = rfecv.fit_transform(wine_x, wine_y) #进行RFE递归
- print("特征是否被选中:\n",rfecv.support_)
- print("获取的数据特征尺寸:",rfecv_wine_x.shape)
- ## True表示对应的特征被选中,可以发现选择了12个特征,只剔除了一个特征
运行结果如下:
- 特征是否被选中:
- [ True True False True True True True True True True True True
- True]
- 获取的数据特征尺寸: (178, 12)
选择了12个特征,剔除了1个特征。
3.3 基于机器学习的方法
sklearn.feature_selection模块的SelectFromModel方式,提供了一种通过模型进行特征选择的方法,可以使用该方法进行基于机器学习的特征选择。首先使用该方法,利用随机森林分类器进行特征选择:
- from sklearn.feature_selection import VarianceThreshold,f_classif
- ## 导入取酒的多分类数据集,用于演示
- from sklearn.datasets import load_wine
- wine_x,wine_y = load_wine(return_X_y=True)
- ## 根据特征的重要性权重选择特征
- from sklearn.feature_selection import SelectFromModel
- from sklearn.ensemble import RandomForestClassifier
- ## 利用随机森林模型进行特征的选择
- rfc = RandomForestClassifier(n_estimators=100,random_state=0)
- rfc = rfc.fit(wine_x,wine_y) # 使用模型拟合数据
- ## 定义从模型中进行特征选择的选择器
- sfm = SelectFromModel(estimator=rfc, ## 进行特征选择的模型
- prefit = True, ## 对模型进行预训练
- max_features = 10,##选择的最大特征数量
- )
- ## 将模型选择器作用于数据特征
- sfm_wine_x = sfm.transform(wine_x)
- print(sfm_wine_x.shape)
- ## 可见针对数据的分类问题选择出6个重要的数据特征
运行结果如下:
(178, 6)可见针对数据的分类问题选择出6个重要的数据特征。
SelectFromModel利用基础模型进行特征选择时,如果基础模型可以使用
 范数,则可以利用范数进行选择。利用支持向量机分类器,借助范数进行特征选择:
范数,则可以利用范数进行选择。利用支持向量机分类器,借助范数进行特征选择:- from sklearn.feature_selection import VarianceThreshold,f_classif
- ## 导入取酒的多分类数据集,用于演示
- from sklearn.datasets import load_wine
- wine_x,wine_y = load_wine(return_X_y=True)
- ## 在特征的选择时还可以利用L1范数进行选择
- from sklearn.feature_selection import SelectFromModel
- from sklearn.svm import LinearSVC
- ## 在构建支持向量机分类时使用L1范数约束
- svc = LinearSVC(penalty="l1",dual=False,C = 0.05)
- svc = svc.fit(wine_x,wine_y)
- ## 定义从模型中进行特征选择的选择器
- sfm = SelectFromModel(estimator=svc, ## 进行特征选择的模型
- prefit = True, ## 对模型进行预训练
- max_features = 10,##选择的最大特征数量
- )
- ## 将模型选择器作用于数据特征
- sfm_wine_x = sfm.transform(wine_x)
- print(sfm_wine_x.shape)
- ## 可见针对数据的分类问题选择出8个重要的数据特征
运行结果如下:
(178, 8)可见针对数据的分类问题选择出8个重要的数据特征。
笔记摘自——《Python机器学习算法与实战》
-
相关阅读:
hive指定字段插入数据,包含了分区表和非分区表
nacos源码编译打包
14届蓝桥青少STEMA-C++组12月评测
SQL注入之宽字节注入
码神之路项目总结(二)
一篇文章让你搞懂__str__和__repr__的异同?
操作系统原理实验一:进程与线程创建控制程序
数据链路层-可靠传输实现机制(回退N帧协议GBN)
elment-plus图标input上面带的图标为什么不显示
PyQt5_股票K线形态查看工具
- 原文地址:https://blog.csdn.net/WHJ226/article/details/125431179