-
Linux-Ubuntu lxml库导入失败 解决方法
问题描述
一开始是报这个错,也就是找不到lxml这个包。
bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library?
因为我这个python程序是在windows运行好好的,放到服务器上说少包。解决方法
- 错误方法
首先sudo apt-get install python3-lxml不管用,报找不到包。然后看其他人的博客知道是因为源的问题,我替换了镜像源代码是:sudo vim /etc/apt/sources.list,用的阿里的,把内容文件内容注释掉
deb https://mirrors.aliyun.com/ubuntu/ trusty main restricted universe multiverse deb-src https://mirrors.aliyun.com/ubuntu/ trusty main restricted universe multiverse deb https://mirrors.aliyun.com/ubuntu/ trusty-security main restricted universe multiverse deb-src https://mirrors.aliyun.com/ubuntu/ trusty-security main restricted universe multiverse deb https://mirrors.aliyun.com/ubuntu/ trusty-updates main restricted universe multiverse deb-src https://mirrors.aliyun.com/ubuntu/ trusty-updates main restricted universe multiverse deb https://mirrors.aliyun.com/ubuntu/ trusty-backports main restricted universe multiverse deb-src https://mirrors.aliyun.com/ubuntu/ trusty-backports main restricted universe multiverse- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
然后呢还是不行,我又看到要用pip,然后安装pip,
sudo apt-get install python3-pip。安装好了之后,pip3 install -i 阿里的镜像地址 lxml。
依旧是不行,然后我注意到是不是操作系统和python的事。有一篇文章是说操作系统是linux64位,python软件是32位的,所以需要32位的lxml包,然后去官网下载。
这个去网上自己排除就可以,其实大部分应该不是这个问题。还有就是下载lxml的时候版本还是有讲究的,下载地址
需要看你的pip的版本是多少,然后参考这个文章看自己应该下载多少版本号:manylinux1和其他的区别
我下载的是这个:
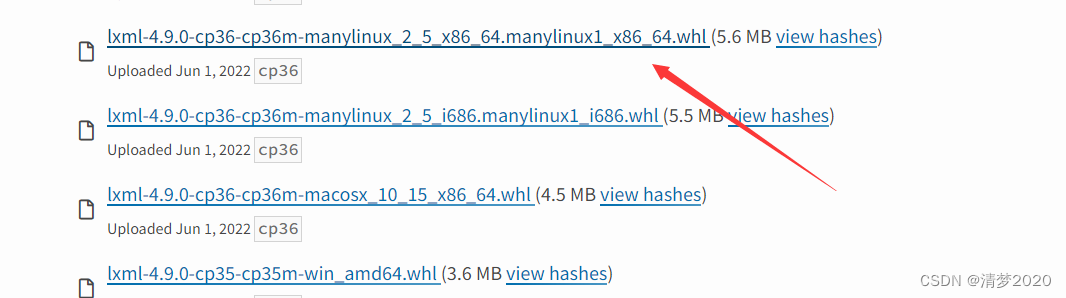
cp36的意思是python版本为3.6,我的pip版本是9.0的,所以选manylinux1,64位的python版本。
下载后,你的python先安装wheel,pip3 install wheel,这个是用于解压这个轮子的。
最后我发现,这种第三方库,你安装到python的包的根目录是没用的,应该放在和运行程序在同一文件夹才行,不然我发现程序找不到。因为中间经历过长达几个小时的,lxml安装了但还是程序说找不到lxml。真的会谢…
pip3 install lxml-4.9.0-cp36-cp36m-manylinux_2_5_x86_64.manylinux1_x86_64.whl,最后发现他还是提示我我已经安装了。
2. 最后的解决方法
我把Python包的根目录的lxml文件复制到了程序文件夹里,结果完美运行。
cp -r /usr/local/lib/python3.6/dist-packages ././代表当前文件夹- 当然其中还有一个方式,就是舍弃用lxml,用html.parser。但是效率会降低,
soup = BeautifulSoup(html, 'lxml')改为soup = BeautifulSoup(html, 'html.parser')
真是鼓捣了一下午,看了各种各样别人写的博客。最后发现自己的问题太低级了…
- 错误方法
-
相关阅读:
CUDA驱动深度学习发展 - 技术全解与实战
基于HFSS的T型功分波导设计
如何应用Python助你在股票中获利?
Java开发备战 - JavaSe(基础篇)
打印机不能正常打印怎么办
ps打开找不到MSVCP140.dll重新安装方法,安装ps出现msvcp140.dll缺失解决方法
usb 命名乱的一批,怎么破
shell编程流程控制语句case和select
【展讯】安卓修改音量等级曲线
Windows 中 Chrome / Edge / Firefox 浏览器书签文件默认存储路径
- 原文地址:https://blog.csdn.net/m0_52238102/article/details/125425762