-
Android显示系统详解
一、显示系统的分类:
我们来思考一个问题:从普通用户角度来说,某个APP页面(例如购物APP首页)是怎么被显示到屏幕的?
首先看到的是物理屏幕,然后是屏幕中软件工程师编写的APP页面,也就是手机屏幕驱动+应用APP,能看出来必然要有一个中介将应用APP图像数据传递渲染到屏幕的驱动,投递到硬件屏幕去显示,这就是Android框架的作用,称之为Android显示系统模块。也就是说能分为以下几块:
1、硬件屏幕+驱动(我就知道个汇顶),驱动节点是 /dev/graphics/fb*,(fb0代表第一个monitor,当前系统只用到一个显示屏,这里也可以看出,Google预留了接口,以便日后扩展显示屏)
2、hal层,hal是显示系统、音频系统等等子系统与Linux kernel驱动之间统一的通信接口,Android系统中与屏幕驱动通信的hal叫Gralloc,Gralloc有两部分:fb和gralloc,fb0负责打开Linux内核中的framebuffer、初始化配置;gralloc负责管理framebuffer的分配和释放,显然上层只能通过Gralloc层来控制framebuffer,从而保证了系统对帧缓冲区(framebuffer)的有序使用和统一管理。
hal层另一个重要模块是composer,为厂商自定义合成提供接口,其直接使用者是surfaceflinger中的HWComposer,HWComposer除了管理composer的hal模块,还负责Vsync信号产生和控制(关于Vsync后续展开介绍)
3、OpenGL ES(可以理解为OpenGL的精简版),是一个跨平台的嵌入式2/3D图形渲染库,Android系统使用其渲染绘制图形,但OpenGL ES在Android中需要被本地化才能使用--------把它和具体平台中的窗口系统关联起来,才能正常使用,FramebufferNativeWindow负责OpenGL ES在Android平台上本地化的中介之一,为OpenGL ES配置本地窗口的是EGL,OpenGL ES更多的是一种协议,具体的实现可以是软件,也可以是硬件,那么运行的时候OpenGL ES如何取舍?这也是EGL的职责之一,读取egl.cfg配置来动态加载libagl(软件实现)或者libhgl(硬件实现),也就是说EGL是为OpenGL ES做环境搭配,本地化的。
4、从底层一路往上,现在是OpenGL ES提供接口api(接口以gl为前缀,如glViewport等),有模块调用后,经过OpenGL ES渲染后就会交给FramebufferNativeWindow去调用hal层Gralloc传递给驱动显示,surfaceFlinger就会调用OpenGL ES的接口,与OpenGL ES相关的模块按照功能可以分为三类:
配置类:即帮助OpenGL ES 完成配置的,EGL、DisplayHardware都算这一类;
依赖类:OpenGL ES要正常运行所依赖的本地化,也就是FramebufferNativeWindow
使用类:surfaceFlinger、DisplayDevice等
二、显示系统的hal层—Gralloc
驱动以及硬件的屏幕不是我们考虑的,简单的知道怎么调用驱动节点就成,接下来探讨Gralloc和framebuffer,从Linux角度来说,framebuffer是kernel内核提供的图形硬件抽象描述,起名叫buffer是因为它也占用系统内存,是一块包含屏幕显示信息的缓冲区。综上,framebuffer在一切都是文件的Linux系统中成为了终端显示设备的抽象化身。
Framebuffer借助Linux文件系统向上层提供一系列操作接口,这样用户控件运行的程序无需太多额外适配工作,无论是哪家厂商、型号都由framebuffer来适配,Android系统中其设备驱动节点是 dev/graphics/fb*,理论上支持多屏幕,fb按数字序号排列,fb0、fb1、fb2…,其中fb0是主屏幕,必须存在,Android各子系统通常不会直接调用内核中的硬件驱动,而是通过hal层引用底层架构,即Gralloc。2.1 Gralloc模块的加载
Gralloc模块是由FramebufferNativeWindow(OpenGL ES的本地窗口,由EGL管理)在构造函数中加载的:
//高版本好像换成了gralloc_device_open(const hw_module_t* module, const char* name,hw_device_t** device) //待验证,但不影响我们学习,不论是什么版本,hal模块的加载思想总是有借鉴意义 hw_get_module(GRALLOC_HAEDWARE_MODULE_ID,&module);- 1
- 2
- 3
hw_get_module是上层使用者加载hal库的入口,也就是说,不论哪个硬件厂商提供的HAL库(例如Gralloc库),只需要通过这个函数来加载,会在 “/system/lib/hw” 和 “ /vendor/lib/hw ”两个路径中寻找,lib库有几种形式:
- gralloc.[ro.hardware].so
- gralloc.[ro.product.board].so
- gralloc.[ro.board.platform].so
- gralloc.[ro.arch].so
当找不到上述的库文件时,就会使用默认的:gralloc.default.so,它由Android原生实现,源码路径在hardware/libhardware/modules/gralloc
2.2 Gralloc模块接口
Gralloc对应的hal库被成功加载后,我们来看下提供的一些重要接口,这里有一个问题,抽象的硬件也就是hal层是父类,具体实现的硬件则是子类(也就是说Gralloc是hal的子类),但是hal层上大多数是用C语音写的,没有继承的概念怎么办?
有一个办法可以模拟实现继承的概念:只要让子类数据结构的第一个成员变量是父类结构即可,也就是说,Gralloc是hw_module_t的子类,后者定义如下:/* hardware/libhardware/include/hardware/hardware.h*/ typedef struct hw_module_t { struct hw_module_methods_t* methods;//一个hal库必须要实现的接口 ... } typedef struct hw_module_methods_t { /** Open a specific device */ int (*open)(const struct hw_module_t* module, const char* id, struct hw_device_t** device); } hw_module_methods_t;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
也就是说,任何硬件设备的HAL库都必须要实现hw_module_methods_t,当前这个数据结构中只有一个函数指针变量 open。当上传使用者调用hw_module_t时,系统先在指定路径中查找并加载正确的HAL库,然后会通过open函数打开指定的设备。
在当前的Gralloc显示系统中,open接口可以打开两种设备,分别是:1、#define GRALLOC_HARDWARE_FB0 “fb0”
2、#define GRALLOC_HARDWARE_GPU0 “GPU0”fb0即为主屏幕,gpu0负责Framebuffer的分配和释放,这俩设备分别由FramebufferNativeWindow的fbDev和grDev成员变量来管理:
/* frameworks/native/libs/ui/FramebufferNativeWindow.cpp*/ FramebufferNativeWindow::FramebufferNativeWindow():BASE(),fbDev(0),grDev(0),... { .... err = framebuffer_open(module, &fbDev); err = gralloc_open(module, &grDev); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
上边两个open函数以及宏定义,分别来自hardware/libhardware/include/hardware目录下的fb.h和gralloc.h,是打开fb和gralloc便捷实现。可想而知,framebuffer_open和gralloc_open最终调用的还是hw_module_t中的open,只是传递的参数不同,也就是宏定义这俩。
在原生Gralloc实现中,hw_module_t中的open函数对应实现是gralloc_device_open()函数,函数中根据设备名判断打开fb还是gralloc设备/* hardware/libhardware/modules/gralloc/gralloc.cpp*/ int gralloc_device_open(const hw_module_t* module, const char* name,hw_device_t** device) { int status = -EINVAL; if (!strcmp(name, GRALLOC_HARDWARE_GPU0)) {//step1、打开gralloc设备 gralloc_context_t *dev; dev = (gralloc_context_t*)malloc(sizeof(*dev)); memset(dev, 0, sizeof(*dev)); dev->device.common.tag = HARDWARE_DEVICE_TAG; dev->device.common.version = 0; dev->device.common.module = const_cast<hw_module_t*>(module); dev->device.common.close = gralloc_close; dev->device.alloc = gralloc_alloc; dev->device.free = gralloc_free; *device = &dev->device.common; status = 0; } else { status = fb_device_open(module, name, device);//step2、打开fb设备 } return status; } /*hardware/libhardware/modules/gralloc/framebuffer.cpp*/ int fb_device_open(hw_module_t const* module, const char* name,hw_device_t** device) { int status = -EINVAL; if (!strcmp(name, GRALLOC_HARDWARE_FB0)) { fb_context_t *dev = (fb_context_t*)malloc(sizeof(*dev));//分配hw_device_t空间,是一个壳 memset(dev, 0, sizeof(*dev)); dev->device.common.tag = HARDWARE_DEVICE_TAG; dev->device.common.version = 0; dev->device.common.module = const_cast<hw_module_t*>(module); dev->device.common.close = fb_close; dev->device.setSwapInterval = fb_setSwapInterval; dev->device.post = fb_post; dev->device.setUpdateRect = 0; private_module_t* m = (private_module_t*)module; status = mapFrameBuffer(m);//内存映射 if (status >= 0) { int stride = m->finfo.line_length / (m->info.bits_per_pixel >> 3); int format = (m->info.bits_per_pixel == 32) ? (m->info.red.offset ? HAL_PIXEL_FORMAT_BGRA_8888 : HAL_PIXEL_FORMAT_RGBX_8888) : HAL_PIXEL_FORMAT_RGB_565; const_cast<uint32_t&>(dev->device.flags) = 0; const_cast<uint32_t&>(dev->device.width) = m->info.xres; const_cast<uint32_t&>(dev->device.height) = m->info.yres; const_cast<int&>(dev->device.stride) = stride; const_cast<int&>(dev->device.format) = format; const_cast<float&>(dev->device.xdpi) = m->xdpi; const_cast<float&>(dev->device.ydpi) = m->ydpi; const_cast<float&>(dev->device.fps) = m->fps; const_cast<int&>(dev->device.minSwapInterval) = 1; const_cast<int&>(dev->device.maxSwapInterval) = 1; *device = &dev->device.common; } else { free(dev); } } return status; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
2.2.1 gralloc设备的打开
step1、打开gralloc设备相对简单一些,其实gralloc本来就是管理分配和释放,这里给我的感觉实质上没有去open开启kernel的真实硬件设备节点,主要是malloc分配内存,memset初始化,并赋值给形参hw_device_t** device,提供俩个重要接口:gralloc_alloc、gralloc_free
2.2.2 fb设备的打开
step2、打开fb则复杂得多,fb_context_t是framebuffer内部使用的一个类,包含非常多的信息,而函数参数device,只是fb_context_t中的device.common。
fb_context_t里唯一的成员变量就是framebuffer_device_t这首对framebuffer设备的统一描述,一个标准fb设备一般需要提供如下接口:1、int (post)(struct framebuffer_device_t dev, buffer_handle_t buffer);将buffer数据post到显示屏,要求buffer必须和屏幕尺寸一致,且没有被locked,这样buffer内容将在下一次Vsync中被显示
2、int (setSwapInterval)(struct framebuffer_device_t window,int interval);设置两个缓冲区的交换时间间隔
3、int (setUpdateRect)(struct framebuffer_device_t window, int left, int top, int width, int height);设置刷新区域,也就是说,在此之外的区域很可以无效而不被刷新还有一些重要的成员变量:
变量 描述 uint32_t flags 标志位,指示framebuffer的属性配置 uint32_t width; uint32_t height; framebuffer的宽高,单位是像素 int format framebuffer的像素格式,RGB_565、888等 float xdpi、ydpi X、Y轴的密度 float fps 屏幕每s刷新频率,默认值为60Hz int minSwapInterval、 maxSwapInterval framebuffer支持的最小和最大缓冲交换时间 到现在我们还是看不到如何打开kernel层的fb设备以及配置,这些都是在mapFrameBuffer(m);//内存映射中做的,
//mapFrameBuffer(m)去调用mapFrameBufferLocked,并加进程锁 /*hardware/libhardware/modules/gralloc/framebuffer.cpp*/ int mapFrameBufferLocked(struct private_module_t* module) { char const * const device_template[] = { "/dev/graphics/fb%u", "/dev/fb%u", 0 }; while ((fd==-1) && device_template[i]) { snprintf(name, 64, device_template[i], 0); fd = open(name, O_RDWR, 0);//真正打开kernel内核的设备 i++; } //fb IO get v screen info,可以猜测这是get,从显示屏驱动上获取屏幕硬件属性 ioctl(fd, FBIOGET_VSCREENINFO, &info); ioctl(fd, FBIOGET_FSCREENINFO, &finfo); //fb IO put v screen info,可以猜测这是put,对底层fb配置某些某些信息 ioctl(fd, FBIOPUT_VSCREENINFO, &info) void* vaddr = mmap(0, fbSize, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);//内存映射 module->framebuffer->base = intptr_t(vaddr);//映射的地址保存在base上,module就是前面hw_get_module得到的hw_module_t memset(vaddr, 0, fbSize); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
三、显示系统的EGL—本地窗口
在谈及OpenGL ES的时候,我们不断重复本地窗口(Native Window)的概念,OpenGL是个跨平台图形库,也就是说window系统能用,iOS系统能用,Linux系统能用,Android系统也能用,就像Java可以跨平台运行,支撑Java跨平台运行的是jvm虚拟机,显然OpenGL也需要一个类似jvm虚拟机一样的东西来与具体的平台对接,将OpenGL中渲染好的适配到具体的Android平台上,Native Window就是干这事的,根据整个的Android系统的GUI来思考,至少需要有两种本地窗口:
- 面向管理者(surfaceFlinger),surfaceFlinger作为系统中所有UI界面的管理者,它需要直接或间接拿到本地窗口就成为理所应当的,这个本地窗口就是FramebufferNativeWindow,而这个本地窗口是直接显示到硬件屏幕的,把它理解成消费者
- 面向应用程序,这类的本地窗口是surface,把它理解成生产者
大家可能会疑惑,一种窗口不就行了,要两种是抽风了吗?这不是更难理解了。。
如果说整个系统只有一个需要显示UI的程序,那一种本地窗口无可厚非,但我们知道Android系统在同一时刻也会有大量程序参与显示UI,这时候如果只有一种本地窗口,显然这个NativeWindow又要让应用程序绘制UI,同时它又要提供给Framebuffer显示,就吵成一锅粥了,屏幕在不停的更新无数个程序的UI需要,既绘制又显示会导致又卡又混乱,因此在架构设计的时候就从生产者和消费者这里将本地窗口区分开(就像线程池中的阻塞队列LinkedBlockQueue,用分离锁控制生产和消费,才是真正的并行运行),所以需要两类本地窗口。
不同应用分别持有surface这类本地窗口,绘制后交给memory Buffer,再交给OpenGL ES去渲染绘制,然后承载到FramebufferNativeWindow这一类本地窗口上,送给Framebuffer显示到硬件屏幕。这是图形渲染都基于OpenGL ES来做的情况下,Android中也有其他的图形渲染库,像Skia,这就更需要两种本地窗口了,
正常我们通过Android Studio 生成的apk,应用层就是用Skia来渲染的,当然我们也可以直接用OpenGL来完成复杂界面的渲染,我看其他博客消息,好像王者荣耀就是在应用层直接用OpenGL 来做的渲染,高效而且图形效果好,但是对开发者要求高3.1面向消费者Framebuffer的本地窗口
我们知道EGL需要通过本地窗口来为OpenGL/OpenGL ES来创造环境,EGL创建本地窗口的函数如下:
EGLSURFACE eglCreateWindowSurface(EGLDISPLAY dpy,EGLConfig config,NativeWindowType window, const EGLint *attrib_list)- 1
- 2
很显然不论是哪一类本地窗口都必须在NativeWindowType这个类型中,不然没法调用函数了,
//NativeWindowType 源码在 frameworks\native\opengl\include\EGL\eglplatform.h中 #elif defined(__ANDROID__) || defined(ANDROID) struct ANativeWindow; struct egl_native_pixmap_t; //能看到在Android系统上,EGLNativeWindowType指的就是ANativeWindow结构体 typedef struct ANativeWindow* EGLNativeWindowType; typedef struct egl_native_pixmap_t* EGLNativePixmapType; typedef void* EGLNativeDisplayType; //ANativeWindow在 frameworks/native/libs/nativewindow/include/system/window.h //或者是在system\core\include\system\window.h 中 struct ANativeWindow { const uint32_t flags;//与surface或updater有关的属性 const int minSwapInterval;//最小交换间隔 const int maxSwapInterval;//最大交换间隔 const float xdpi;//水平方向密度 dpi单位 const float ydpi;//垂直 intptr_t oem[4];//为OEM定制驱动保留的空间 int (*setSwapInterval)(struct ANativeWindow* window,int interval); int (*dequeueBuffer_DEPRECATED)(struct ANativeWindow* window,struct ANativeWindowBuffer** buffer); int (*queueBuffer_DEPRECATED)(struct ANativeWindow* window,struct ANativeWindowBuffer* buffer); int (*cancelBuffer_DEPRECATED)(struct ANativeWindow* window,struct ANativeWindowBuffer* buffer); int (*query)(const struct ANativeWindow* window,int what, int* value); int (*perform)(struct ANativeWindow* window, int operation, ... ); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
总结一下,EGL模块用本地窗口为OpenGL ES做中介嫁接,EGL模块中是EGLNativeWindowType,在Android平台上本地窗口的类型是:ANativeWindow,本地窗口统称FramebufferNativeWindow,也就是说,在Android平台上,这几种实质是一个意思,只是涵盖的范围不同,EGLNativeWindowType -> ANativeWindow -> FramebufferNativeWindow,接下来看看本地窗口是怎么实现ANativeWindow的。
3.1.1 FramebufferNativeWindow构造函数
回顾一下,本地窗口是干什么用 的?对上层,提供给OpenGL ES(EGL模块管理)适配的接口,对下层,它是对接Gralloc模块(hal层架构):
- 加载GRALLOC_HARDWAER_MODULE_ID模块,这模块是hal层的通用接口
- 分别打开fb0和gralloc设备,打开后由全局成员变量fbDev和grDev管理
- 根据设备属性给FramebufferNativeWindow赋值
- 根据FramebufferNativeWindow实现来给ANative赋值填充结构体
下面从源码来看,高版本全部替换了,路径在hardware/interfaces/graphics/composer/2.1/utils/passthrough/include/composer-passthrough/2.1/HwcLoader.h,最近几个版本一直在改动,根目录都不停的变,因此我们用老版本来学习
/**frameworks/native/libs/ui/FramebufferNativeWindow.cpp*/ FramebufferNativeWindow::FramebufferNativeWindow() : BASE(), fbDev(0), grDev(0), mUpdateOnDemand(false) { hw_module_t const* module; if (hw_get_module(GRALLOC_HARDWARE_MODULE_ID, &module) == 0) {//加载hal模块 int stride; int err; int i; err = framebuffer_open(module, &fbDev); //打开framebuffer设备 err = gralloc_open(module, &grDev); //grallo设备 ... if(fbDev->numFramebuffers >= MIN_NUM_FRAME_BUFFERS && fbDev->numFramebuffers <= MAX_NUM_FRAME_BUFFERS){ mNumBuffers = fbDev->numFramebuffers;//从fbDev中获取buffer数量 } else { mNumBuffers = MIN_NUM_FRAME_BUFFERS; } mNumFreeBuffers = mNumBuffers;//初始化时可用buffer数量就是所有的buffer mBufferHead = mNumBuffers-1; for (i = 0; i < mNumBuffers; i++) { //step1、为每个buffer初始化,这里出来个NativeBuffer,是什么? buffers[i] = new NativeBuffer( static_cast<int>(fbDev->width), static_cast<int>(fbDev->height), fbDev->format, GRALLOC_USAGE_HW_FB); } for (i = 0; i < mNumBuffers; i++) { err = grDev->alloc(grDev, static_cast<int>(fbDev->width), static_cast<int>(fbDev->height), fbDev->format, GRALLOC_USAGE_HW_FB, &buffers[i]->handle, &buffers[i]->stride); } //为本地窗口赋值 const_cast<uint32_t&>(ANativeWindow::flags) = fbDev->flags; const_cast<float&>(ANativeWindow::xdpi) = fbDev->xdpi; const_cast<float&>(ANativeWindow::ydpi) = fbDev->ydpi; const_cast<int&>(ANativeWindow::minSwapInterval) = fbDev->minSwapInterval; const_cast<int&>(ANativeWindow::maxSwapInterval) = fbDev->maxSwapInterval; } //为ANativeWindow协议赋值 ANativeWindow::setSwapInterval = setSwapInterval; ANativeWindow::dequeueBuffer = dequeueBuffer; ANativeWindow::queueBuffer = queueBuffer; ANativeWindow::query = query; ANativeWindow::perform = perform; ANativeWindow::dequeueBuffer_DEPRECATED = dequeueBuffer_DEPRECATED; ANativeWindow::lockBuffer_DEPRECATED = lockBuffer_DEPRECATED; ANativeWindow::queueBuffer_DEPRECATED = queueBuffer_DEPRECATED;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
老版本的逻辑其实很通俗易懂,framebuffer_open、gralloc_open打开fb和gralloc设备,接着就是拿到fb设备中的buffer数量,初始化buffer,也就是dequeue出队时的buffer,能看出来是在这里new出来的,mNumBuffers代表FramebufferNativeWindow拥有的buffer数量,先从fb设备中取值,没有的时候就直接赋值MIN_NUM_FRAME_BUFFERS宏,数量是2(MAX_NUM_FRAME_BUFFERS 最大是3),这就是framebuffer的双缓冲技术,为什么需要2或者3个buffer呢?
双缓冲(multi buffering)就是Google在Android 4.0以后大力优化surfaceFlinger的产物,为了解决屏幕绘制卡顿的Jank现象,大概原理就是用两个NativeWindow,一个供给kernel内核fb设备去展示在屏幕上,一个供给surfaceFlinger去合成图层,生产者、消费者分开后,极大的降低了帧卡顿Jank现象。
理解了buffer数量后,继续看这些buffer缓冲区从哪分配的,step1能看到,NativeBuffer属性都是从fb中取出来的,我们知道FramebufferNativeWindow是要通过hal层的Gralloc模块去跟屏幕硬件驱动fb设备中申请属性的,接着调用gralloc设备alloc(分配内存)
grDev->alloc(grDev,
static_cast(fbDev->width),
static_cast(fbDev->height),
fbDev->format, GRALLOC_USAGE_HW_FB,
&buffers[i]->handle, &buffers[i]->stride);我们要注意第五个参数GRALLOC_USAGE_HW_FB,它代表要申请的缓冲区用途,定义在/hardware/libhardware/include/hardware/gralloc.h中的枚举变量,现在已经扩展到三四十种了,详细信息可以针对性去查,这里的含义代表缓冲区用于framebuffer设备,也就是显示在终端屏幕上,对应的函数实现是在gralloc_alloc_framebuffer@Gralloc.cpp。NativeBuffer继承 ANativeWindowBuffer(也在FramebufferNativeWindow .cpp类中),后者定义在 “ system/core/include/system/Window.h ”
另外,当前可用(free)buffer的数量由MNumFreeBuffer管理,总共有2或3个可用缓冲区。在程序运行过程中,始终由mBufferHead 指向下一个将被申请的buffer。
一个本地窗口包含了很多属性值,各种标志flag、横纵坐标的密度值等,这些属性都可以在fb设备中查到,赋值给FramebufferNativeWindow实例的属性。
最后就是履行ANativeWindow协议,将FramebufferNativeWindow的各种接口都赋值到ANativeWindow中,这样ANativeWindow的接口实现全部都由FramebufferNativeWindow来完成。这样OpenGL ES才能通过一个ANativeWindow来与本地窗口建立连接关系。3.1.2 dequeueBuffer
OpenGL ES 通过它分配一个可用于渲染的缓冲区。看源码
/**frameworks/native/libs/ui/FramebufferNativeWindow.cpp*/ int FramebufferNativeWindow::dequeueBuffer(ANativeWindow* window, ANativeWindowBuffer** buffer, int* fenceFd) { //将ANativeWindow类型的window强转为FramebufferNativeWindow FramebufferNativeWindow* self = getSelf(window); Mutex::Autolock _l(self->mutex);//加互斥锁 //当上层用户向FramebufferNativeWindow申请(dequeue)一个buffer,mBufferHead就会增1, //当超过buffer数量时,就置为0 int index = self->mBufferHead++; if (self->mBufferHead >= self->mNumBuffers) self->mBufferHead = 0; // wait for a free non-front buffer,这里wait了肯定有个地方要notify唤醒, //肯定是在queueBuffer()函数中 while (self->mNumFreeBuffers < 2) { self->mCondition.wait(self->mutex); } // 当有人释放缓冲区,重置属性 self->mNumFreeBuffers--; self->mCurrentBufferIndex = index; *buffer = self->buffers[index].get(); *fenceFd = -1; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
代码不多,注释能看清楚
总结1:- 以驱动层为起点,由Hal层的Gralloc模块来打开驱动的fb、gralloc设备节点
- Hal层的Gralloc模块由本地窗口FramebufferNativeWindow来赋值使用
- 而FramebufferNativeWindow是ANativeWindow的子类,并且前者实现或者hook了诸多ANativeWindow的函数实现,也就是说现在由ANativeWindow就能控制硬件驱动了,
- ANativeWindow是Android平台的本地窗口,属于跨平台OpenGL ES图形库,后者可以直接使用ANativeWindow窗口的,因此由EGL模块控制的OpenGL ES现在已经可以显示图形的需求了,基于目前的条件,我们现在推理到了EGL模块操作的OpenGL ES!
3.2 面向应用者的本地窗口 surface
这里的surface指native层的真正surface,不是应用层的surface(类似一个proxy代理壳子)
针对应用端的本地窗口是surface,和FramebufferNativeWindow一样也是继承ANativeWindow,那么Surface也必须实现ANativeWindow所制定的“ 协议 ”,我们重点来关注surface和FramebufferNativeWindow差异在什么地方,来看surface构造函数Surface::Surface(const sp<IGraphicBufferProducer>& bufferProducer, bool controlledByApp) : mGraphicBufferProducer(bufferProducer), mCrop(Rect::EMPTY_RECT), mBufferAge(0), mGenerationNumber(0), mSharedBufferMode(false), mAutoRefresh(false), mSharedBufferSlot(BufferItem::INVALID_BUFFER_SLOT), mSharedBufferHasBeenQueued(false), mQueriedSupportedTimestamps(false), mFrameTimestampsSupportsPresent(false), mEnableFrameTimestamps(false), mFrameEventHistory(std::make_unique<ProducerFrameEventHistory>()) { // Initialize the ANativeWindow function pointers. ANativeWindow::setSwapInterval = hook_setSwapInterval; ANativeWindow::dequeueBuffer = hook_dequeueBuffer; ANativeWindow::cancelBuffer = hook_cancelBuffer; ANativeWindow::queueBuffer = hook_queueBuffer; ANativeWindow::query = hook_query; ANativeWindow::perform = hook_perform; ANativeWindow::dequeueBuffer_DEPRECATED = hook_dequeueBuffer_DEPRECATED; ANativeWindow::cancelBuffer_DEPRECATED = hook_cancelBuffer_DEPRECATED; ANativeWindow::lockBuffer_DEPRECATED = hook_lockBuffer_DEPRECATED; ANativeWindow::queueBuffer_DEPRECATED = hook_queueBuffer_DEPRECATED; const_cast<int&>(ANativeWindow::minSwapInterval) = 0; const_cast<int&>(ANativeWindow::maxSwapInterval) = 1; mReqWidth = 0; mReqHeight = 0; mReqFormat = 0; mReqUsage = 0; ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
功能很简单,为ANativeWindow中的函数指针赋值,初始化一些变量,因为此时用户没有申请,变量都赋值是0,surface是面向Android系统所有UI应用程序的,因此能想象其必要提供的功能有:
- 面向上层应用(主要是Java层的apk)提供绘制图形的画板,就需要思考一下,我们在前面说,对于提供给上层应用使用的本地窗口,这个内存空间是不属于帧缓冲区Framebuffer的,那属于谁,是谁在管理?
- 它和surfaceFlinger如何分工?其实这个大家应该有个模糊印象,surfaceflinger主要是合成系统各应用程序的图层,surface是具体一个应用程序界面的绘图画板,应当说,很多surface汇合到surfaceFlinger,后者来做合成的,Surface的主要作用是什么?
先介绍下Surface类的一些重要成员变量
成员变量 描述 sp mGraphicBufferProducer surface最重要的变量,后续会专门讲解 BufferSlot mSlots[NUM_BUFFER_SLOTS] surface内部存储buffer的地方,NUM_BUFFER_SLOTS最大是32,当用户dequeueBuffer时才会真正分配空间 uint32_t mReqWidth、mReqHeight 下一次dequeue时将申请的尺寸,默认都是1 PixelFormat mReqFormat 下一次dequeue时申请的像素格式,默认是RGBA_8888 uint64_t mReqUsage 下一次dequeue时指定的usage类型 Rect mCrop crop表示修剪,下一次dequeue时用于修剪缓冲区,可以调用setCrop设置具体值 int mScalingMode 下一次dequeue时对缓冲区进行scale,可以调用setScalingMode设置具体值 uint32_t mTransform 用于下次dequeue时的图形翻转等操作 uint32_t mDefaultWidth、mDefaultHeight 默认情况下的缓冲区宽高值 uint32_t mUserWidth、mUserHeight 不为0的时候就指应用层指定的宽高值,会覆盖mDefaultWidth默认宽高值 sp mLockedBuffer 访问此变量需要加锁 sp mPostedBuffer 访问此变量需要加锁 Region mDirtyRegion 访问此变量需要加锁 大致可以猜测,surface是通过mGraphicBufferProducer 来获取buffer(毕竟Producer 生成者嘛),然后通过mSlots来记录获取到的buffer。
Surface类的构造函数能看到,ANativeWindow中的函数指针赋值的是各种以hook开头的函数,这些hook_XXX函数的内部又钩住了Surface中的真正函数实现。例如hook_dequeueBuffer对应的就是Surface中的的queueBuffer,就如同钩子一样延伸,因此叫hook这种思想在组件化架构中大量实现,非常方便的实现了模块化的解耦。下面来看下的queueBuffer函数:int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) { Mutex::Autolock lock(mMutex); //step1、计算宽高 reqWidth = mReqWidth ? mReqWidth : mUserWidth; reqHeight = mReqHeight ? mReqHeight : mUserHeight; //Step2、获取一个buffer缓冲区 int buf = -1; sp<Fence> fence; status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence, reqWidth, reqHeight, reqFormat, reqUsage, &mBufferAge, enableFrameTimestamps ? &frameTimestamps : nullptr); ... //当dequeueBuffer后buf就是mSlots数组中可用的成员序号,用它获取真正的buffer地址 sp<GraphicBuffer>& gbuf(mSlots[buf].buffer); ... if ((result & IGraphicBufferProducer::BUFFER_NEEDS_REALLOCATION) || gbuf == nullptr) { result = mGraphicBufferProducer->requestBuffer(buf, &gbuf);//申请空间 ... } ... *buffer = gbuf.get(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
从源码能看到Surface类中执行dequeueBuffer操作拿buffer缓冲区就是从mGraphicBufferProducer来获取的(IGraphICBufferProductor),surface中这个核心的成员变量来源有两种,一是作为Surface的构造参数传入,或者是Surface的子类调用setIGraphicBufferProductor来生成,在应用进程里,是后者方式来生成。
总结2:
本地窗口surface中的buffer由mGraphicBufferProducer类中的dequeueBuffer来提供(这是生产者)3.2.1 本地窗口surface由谁来使用
消费者显然是上层的Java应用程序,这个逻辑实质是surface的显示过程(其实也就是activity显示过程),无论是新建一个activity或者是隐藏后重新显示某个页面Activity,都会走surface显示的逻辑,简单回顾下Activity、view、window之间的关系:
View代表xml布局文件,由Activity(setContent函数)传递给PhoneWindow(继承Window类),WindowManagerImpl(实现WindowManager接口,PhoneWindow可以获取到父类window的成员变量mWindowManager),,很显然PhoneWindow在setView的时候,就能将View传送给WindowManagelmpl,后者能够获取到WindowManagerGlobal,将此View使用addView传递给WindowManagerGlobal(见名知意),我们从WindowManagerGlobal.addView()开始看起
/*frameworks\base\core\java\android\view*/ //WindowManagerGlobal.java: public void addView(View view, ViewGroup.LayoutParams params, Display display, Window parentWindow) { ... final WindowManager.LayoutParams wparams = (WindowManager.LayoutParams) params; ViewRootImpl root = new ViewRootImpl(view.getContext(), display); view.setLayoutParams(wparams); mViews.add(view); mRoots.add(root); mParams.add(wparams); root.setView(view, wparams, panelParentView);//Step1、 ... } //创建 ViewRootImpl public ViewRootImpl(Context context, Display display) { /* Step2、ViewRootImpl与WindowManagerService跨进程的binder入口*/ this(context, display, WindowManagerGlobal.getWindowSession(), false ); } //WindowManagerGlobal.java 如何获取到WMS服务的逻辑 @UnsupportedAppUsage public static IWindowSession getWindowSession() { synchronized (WindowManagerGlobal.class) { if (sWindowSession == null) { try { //获取 IMS 的代理类 InputMethodManager.ensureDefaultInstanceForDefaultDisplayIfNecessary(); IWindowManager windowManager = getWindowManagerService(); //经过 Binder 调用,最终调用 WMS sWindowSession = windowManager.openSession( new IWindowSessionCallback.Stub() { @Override public void onAnimatorScaleChanged(float scale) { ValueAnimator.setDurationScale(scale); } }); } catch (RemoteException e) { throw e.rethrowFromSystemServer(); } } return sWindowSession; } } //WindowManagerService.openSession @Override public IWindowSession openSession(IWindowSessionCallback callback) { //创建session对象,再次经过 Binder 将数据写回 app 进程, //则获取的便是 Session 的代理对象 IWindowSession。 return new Session(this, callback); } //根据Step1,addView@WindowManagerGlobal.java, //root.setView(view, wparams, panelParentView),会调用到ViewRootImpl的setView函数- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
根据Step1,addView()@WindowManagerGlobal.java–>setView()@ViewRootImpl–>requestLayout()@ViewRootImpl–>scheduleTraversals()@ViewRootImpl–>scheduleTraversals()@ViewRootImpl,看看这个函数
//frameworks\base\core\java\android\view\ViewRootImpl void scheduleTraversals() { mChoreographer.postCallback( Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null); } final TraversalRunnable mTraversalRunnable = new TraversalRunnable(); final class TraversalRunnable implements Runnable { @Override public void run() { doTraversal(); } } void doTraversal() { ... performTraversals(); ... } private void performTraversals() { ... relayoutResult = relayoutWindow(params, viewVisibility, insetsPending); ... } private int relayoutWindow(WindowManager.LayoutParams params, int viewVisibility, boolean insetsPending) throws RemoteException { ... //Step3、到这里就把Surface各项信息都传递给了WMS int relayoutResult = mWindowSession.relayout(mWindow, mSeq, params, (int) (mView.getMeasuredWidth() * appScale + 0.5f), (int) (mView.getMeasuredHeight() * appScale + 0.5f), viewVisibility, insetsPending ? WindowManagerGlobal.RELAYOUT_INSETS_PENDING : 0, frameNumber, mTmpFrame, mPendingOverscanInsets, mPendingContentInsets, mPendingVisibleInsets, mPendingStableInsets, mPendingOutsets, mPendingBackDropFrame, mPendingDisplayCutout, mPendingMergedConfiguration, mSurfaceControl, mTempInsets); if (mSurfaceControl.isValid()) { //Step4、copyFrom后Surface就真正有了底层的Framebuffer能力, //而不是一个空壳Proxy,重点都在这里,mSurfaceControl是从jni拿上来 //它就代表一个surface mSurface.copyFrom(mSurfaceControl); } else { destroySurface(); } ... } //frameworks\base\core\java\android\view\SurfaceControl.java private static native long nativeCopyFromSurfaceControl(long nativeObject); public void copyFrom(SurfaceControl other) { mName = other.mName; mWidth = other.mWidth; mHeight = other.mHeight; assignNativeObject(nativeCopyFromSurfaceControl(other.mNativeObject)); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
从现在开始使用jni调用到了native层,会调用到CreateSurface@SurfaceComposerClient.cpp
/*frameworks\native\libs\gui\SurfaceComposerClient.cpp*/ sp<SurfaceControl> SurfaceComposerClient::createSurface(const String8& name, uint32_t w, uint32_t h, PixelFormat format, uint32_t flags, SurfaceControl* parent, LayerMetadata metadata) { sp<SurfaceControl> sur; if (mStatus == NO_ERROR) { sp<IBinder> handle; sp<IBinder> parentHandle; sp<IGraphicBufferProducer> gbp;//Step1、就是buffer的生产者 if (parent != nullptr) { parentHandle = parent->getHandle(); } err = mClient->createSurface(name, w, h, format, flags, parentHandle, std::move(metadata), &handle, &gbp);//Step2、生成一个surface if (err == NO_ERROR) { *sur= new SurfaceControl(this, handle, gbp, true /* owned */); } } return sur; } void SurfaceComposerClient::onFirstRef() { sp<ISurfaceComposer> sf(ComposerService::getComposerService()); if (sf != nullptr && mStatus == NO_INIT) { sp<ISurfaceComposerClient> conn; conn = sf->createConnection(); if (conn != nullptr) { mClient = conn; mStatus = NO_ERROR; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
由此可见,mClient(ISurfaceComposerClient类型的指针)是由ISurfaceComposer::createConnection()实现的
3.2.2 本地窗口surface由mGraphicBufferProducer提供具体的实现
上述的ISurfaceComposer,是匿名的binder服务,在这个过程中总共涉及到3个匿名Binder Server,看看其提供的接口
匿名Binder 提供的接口 ISurfaceComposer createConnection ISurfaceComposerClient createSurface()/destroySurface() IGraphicBufferProducer requestBuffer()/dequeueBuffer()/queueBuffer()/cancelBuffer()… 这三个匿名Binder是环环相扣的,只能从第一个开始访问ISurfaceComposer -->ISurfaceComposerClient -->IGraphicBufferProducer ,我们知道匿名的Binder一定要有实名的Binder来提供,就是SurfaceFlinger-这个系统服务,在ServiceManager中注册好,获取SurfaceFlinger服务的代码逻辑在SurfaceComposerClient::onFirstRef()中
void SurfaceComposerClient::onFirstRef() { //sf就是SurfaceFlinger sp<ISurfaceComposer> sf(ComposerService::getComposerService()); if (sf != nullptr && mStatus == NO_INIT) { sp<ISurfaceComposerClient> conn; conn = sf->createConnection(); if (conn != nullptr) { mClient = conn; mStatus = NO_ERROR; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
通过向ServiceManager查询名称为"SurfaceFlinger"的Binder Server来获取, 和其他常见的Binder Server不同的是,虽然其在sm中的注册名称是"SurfaceFlinger",但服务器实现的Binder接口却是以ISurfaceComposer命名,所以根据sm获取名称为"SurfaceFlinger"的Binder Server,拿到的就是ISurfaceComposer,Google在这里不知道为什么会起名不统一,很费解逻辑混乱:
/*frameworks\native\services\surfaceflinger\SurfaceFlinger.h*/ class SurfaceFlinger : public BnSurfaceComposer,//实现的本地服务server叫ISurfaceComposer public PriorityDumper, public ClientCache::ErasedRecipient, private IBinder::DeathRecipient, private HWC2::ComposerCallback { //从SurfaceFlinger的继承关系也能看出来,实现的本地服务server叫ISurfaceComposer- 1
- 2
- 3
- 4
- 5
- 6
- 7
总结:
- 面向应用者的本地窗口 surface,这一节阐述的是:本地窗口surface①由谁使用以及从最上层往下的调用逻辑;②由谁创建本地窗口surface(SurfaceFlinger和基于它的三个匿名Binder Server)
- 现在也清楚了Surface::dequeueBuffer是由mGraphicBufferProduct(IGraphicBufferProduct)匿名binder server来dequeueBuffer,IGraphicBufferProduct是Binder体系的接口,实现是谁?SurfaceFlinger中由BufferQueue来实现(也就是说,上层应用的Surface是由BufferQueue来提供实现的)
- 对整体本地窗口总结下:Android系统中的本地窗口分两类,FramebufferNativeWindow由Hal模块的Gralloc提供,SurfaceFlinger是其操作使用者,它的逻辑相对容易理解,比较清晰明了;而Surface是给应用程序使用的,实质由SurfaceFlinger(IGraphicBufferProducer匿名BinderServer)提供管理,但是因为很多跨进程与穿插Java与native框架,显得非常庞大,层出不穷的类名很容易混乱
- 对于本地窗口Surface来说,应用程序是Producer,SurfaceFlinger是Cunsumer,而BufferQueue就是生产者-消费者模式中的容器,dequeueBuffer、queueBuffer都是操作这个容器
3.3 承载本地窗口Surface的容器-BufferQueue
上节我们已经知道,BufferQueue是本地窗口提供Surface中最重要的环节,在SurfaceFlinger进程中,试想下列问题:
- 每个应用程序可以有几个BufferQueue,一对一、一对多、还是多对一?
- 应用程序绘制UI需要的内存是谁来分配的?
- 应用程序与SurfaceFlinger如何互斥共享数据区?
这里显然是经典的生产者-消费者模式,Android显示系统是如何控制协调两者对缓冲区的互斥访问?先看看BufferQueue结构

3.3.1 BufferQueue主体框架介绍
BufferQueue是IGraphicBufferProducer服务端的实现,因此它会实现所有的虚函数接口,有个非常重要的成员数组mSlots[NUM_BUFFER_SLOTS],Surface::dequeueBuffer()中,使用mGraphicBufferProducer调用dequeueBuffer函数后,就是从这个mSlots数组中取buffer的:
//当dequeueBuffer后buf就是mSlots数组中可用的成员序号,用它获取真正的buffer地址 sp<GraphicBuffer>& gbuf(mSlots[buf].buffer);- 1
- 2
mSlots结构体中,sp<GraphicBuffer MGraphicBuffer用来记录缓冲区,BufferState变量用于记录缓冲区的状态,一共四种:
- free:buffer当前可用,可以被dequeued,buffer的owner是BufferQueue
- dequeued:Buffer已经被dequeue,还没有queue或者canceld,buffer的owner是Producer(也就是应用程序)
- queued:Buffer已经被客户端queued,这时不能对它dequeue,但可以acquired,buffer的owner是BufferQueue
- acquired:Buffer的owner是consumer(也就是SurfaceFlinger),可以被released,然后状态又变为free
用生产者-消费者模式可以帮助我们理解这块逻辑:BufferQueue是装产品的容器,上层有UI显示需求的应用程序是Producer,SurfaceFlinger作为Consumer,拿到产品后去合成,Producer从BufferQueue中dequeue,拿到一个buffer(它就是产品,Surface),应用程序绘制后queue,这时候Buffer这个产品又回到BufferQueue的手里(此时这个产品的BufferState是queued,不能再次dequeue,只能被Consumer(SurfaceFlinger) acquired拿到手去合成消费),然后Consumer向BufferQueue申请acquire,完成后release,这个产品Buffer又恢复成原始free状态,再次等待被Producer拿到手。
这里大家应该要有个疑问,这样才说明真正在思考:作为Producer来说,它是主动去BufferQueue拿产品Buffer,自然是应用程序什么时候想起来要用就去拿,没有疑问点,那Producer把一个产品Buffer填充好queue入队后,Consumer怎么知道它该去BufferQueue中取产品呢?
因为BufferQueue类中还包含一个ConsumerListener回调,当一块Buffer产品可以被Consumer消费时,就会通过这个函数通知Consumer(SurfaceFlinger)来acquire取出来去消费
3.3.2 BufferQueue缓冲区分配
根据上一节可以知道,BufferQueue中有mSlots成员数组管理其内部所有的缓冲区,最大容量是32,查看代码可知这个数组是一次性静态分配了32个BufferSlot的长度,缓冲区中的内存肯定不是也一次性全给分配(这样太浪费内存),再来探究下什么时候会真正分配一次缓冲区Buffer?
要动态new Buffer,想来最容易的逻辑就是什么时候需要Buffer,什么时候分配,应用程序作为整个需求的发起者,只要能满足它的dequeued则一切安好,答案都在dequeueBuffer函数中,大概描述下函数逻辑:先查找一个可用的BufferSlot并记录序号(0-31这32个当中去筛选),主要就是操作BufferState的那四种状态流转,但此时只是选定了BufferSlot的序号,它的内存可能还是NULL(可能这个词语是因为这个Buffer之前可能被分配过但是width和height不匹配,要重新分配的,也有可能完全一样,这样就直接拿走去用了),用mGraphicBufferAlloc分配一个BufferSlot空间,如果重新分配了(relayout)空间返回值就会带上BUFFER_NEEDS_REALLOCATION标志,客户端收到这个标志,就得调用requestBuffer()来获取最新的buffer地址这里又会冒出来一个问题,BufferQueue是Binder server,Binder体系的客户端铁定运行在另一个进程中(否则还要binder干嘛),两个不同进程buffer的地址要怎么传递???客户端中的mSlots[buf]和服务端中是指向同一块物理内存吗?
requestBuffer函数可以解决这个问题,我们先来看看BpGraphicBufferProducer是怎么发起Binder请求的
class BpGraphicBufferProducer : public BpInterface<IGraphicBufferProducer> { ... //Step1,发现没有入参是俩个,但是buf指针没有传递给服务端 virtual status_t requestBuffer(int bufferIdx, sp<GraphicBuffer>* buf) { Parcel data, reply; data.writeInterfaceToken(IGraphicBufferProducer::getInterfaceDescriptor()); data.writeInt32(bufferIdx);//只写入bufferIdx,服务端是看不到buf指针的 status_t result =remote()->transact(REQUEST_BUFFER, data, &reply); if (result != NO_ERROR) { return result; } bool nonNull = reply.readInt32();//Step2 if (nonNull) { *buf = new GraphicBuffer();//Step3、是在本地生成Buffer的 result = reply.read(**buf);//Step4 if(result != NO_ERROR) { (*buf).clear(); return result; } } result = reply.readInt32(); return result; } ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
我们继续看Bnxxx服务端,就会有恍然大悟的感觉
status_t BnGraphicBufferProducer::onTransact( uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags) { switch(code) { case REQUEST_BUFFER: { CHECK_INTERFACE(IGraphicBufferProducer, data, reply); int bufferIdx = data.readInt32(); sp<GraphicBuffer> buffer; int result = requestBuffer(bufferIdx, &buffer);//这里是重点 reply->writeInt32(buffer != nullptr);//Step1 if (buffer != nullptr) { reply->write(*buffer);//Step2 } reply->writeInt32(result); return NO_ERROR; } .... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
突然想起来,这里要说明下,Android系统(Framework)的学习,Binder跨进程真的是基础中的基础,如果大家对Binder跨进程(AIDL)不熟悉,必须要先去学习binder,才能开始去看framework的源码,大家可以认为系统中所有的进程都是要跨进程的(也有用LocalSocket去跨进程,但绝大多数都是binder来做的跨进程),这里就不介绍binder了默认大家对binder很熟悉
上述的Bp Step2、Step3 对应Bn的Step1、Step2,Bn先写入一个bool值,为true时,把*buffer写到binder中,这样Bp取的时候也要先取这个bool值,如果为true时(Bp的Step2),就在本地创建出来一个GraphicBuffer对象,Step4,buf是sp指针,**buf就代表这个智能指针所指向的对象,这里就是mSlots[buf].buffer,能看到Bp中requestBuffer函数的入参buf自始至终都是在本地进程来操作完成的,只有Slot序号(bufferIdx)在Bp和Bn中传来传去,这里的Bn指的就是BufferQueue这个IGraphicBufferProducer的Binder Server端实现(Bp自然就是客户端),Bn这里传递的Buffer是个对象,Bp中接收的也是个对象,Binder跨进程时可以传递对象(或者说是完整的复现出来),能这么干的原因是这类binder对象继承Flattenable,这俩接口在新老版本差别很大,就不分析了感兴趣可以看看源码(源码在frameworks\native\libs\ui\GraphicBuffer.cpp),主要原理是利用ashmen(匿名共享内存,Binder跨进程时专门用来传递大数据的,因为普通的binder跨进程限定一次只能传递1M-8k的数据,借用Linux的高速文件系统tmpfs,使用fd来mmap在不同进程中传递)实现共享缓冲区。
总结:
经过上述的流程,Surface::dequeueBuffer()函数在运行过程中,一旦发现mGraphicBufferProducer->requestBuffer结果中带有BUFFER_NEEDS_REALLOCATION标志位,就通过requestBuffer得到的结果来刷新C端mSlots[]数组中的buffer缓冲区信息,这样就能保证Surface和BufferQueue在任何情况下那32个buffer完全一致。接下来我们用一个小例子来巩固目前的知识点-Android系统开机动画(因为系统开机动画是c++程序,正好跳过上层一大堆的封装,与当前学习到的知识点高度契合)
3.4 Android系统开机示例分析
Android系统开机动画是一个c++程序,应用程序和SurfaceFlinger都是使用 OpenGL ES来渲染绘制UI的,不需要Java层的GLSurfaceView支持。
当一个Android设备上电后,默认情况会先后显示最多4个不同的开机动画,分别是:- BootLoader,它是开机引导程序,负责系统后续模块的加载和启动,一般显示一张静态图
- Kernel,内核也会显示画面
- Android,这里是系统启动的最后一个阶段,也是最耗时的,其开机动画静态动态的图片文字都可以。
这个开机动画的程序就是BootAnimation,内部借助SurfaceFlinger来完成,因为是c++程序,可以抛开层出不穷的JNI调用和封装,因此是学习、分析BufferQueue的最佳角色。是一个Linux服务进程,在init.rc脚本启动
service bootanim /system/bin/bootanimation class core user graphics group graphics audio disabled oneshot- 1
- 2
- 3
- 4
- 5
- 6
bootanim服务进程启动后,main函数被调用,逻辑一目了然
/*frameworks\base\cmds\bootanimation\bootanimation_main.cpp*/ int main() { setpriority(PRIO_PROCESS, 0, ANDROID_PRIORITY_DISPLAY); char value[PROPERTY_VALUE_MAX]; property_get("debug.sf.nobootanimation", value, "0"); int noBootAnimation = atoi(value); ALOGI_IF(noBootAnimation, "boot animation disabled"); if (!noBootAnimation) { sp<ProcessState> proc(ProcessState::self()); ProcessState::self()->startThreadPool(); // create the boot animation object sp<BootAnimation> boot = new BootAnimation(); IPCThreadState::self()->joinThreadPool(); } return 0; } BootAnimation::BootAnimation() : Thread(false), mZip(NULL) { mSession = new SurfaceComposerClient(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
SurfaceComposerClient是每一个应用程序和SurfaceFlinger之间的独立纽带桥梁,它是一个封装出来的模块,内部还是ISurfaceComposerClient来实现,还记得实名Binder Server下的三个匿名服务吗,要按序调用
- ISurfaceComposer
- ISurfaceComposerClient,应用程序与SurfaceFlinger,也就是说,应用先访问到SurfaceFlinger,再用ISurfaceComposerProducer访问到BufferQueue
- ISurfaceComposerProducer,应用程序与BufferQueue
BufferQueue拿到各应用程序的UI,再让SurfaceFlinger合成所有显示图层,送到屏幕上显示,因此BootAnimation在构造函数中就建立了与SurfaceFlinger的联系,与BufferQueue的联系是在onFirstRef()中,sp智能指针被首次引用时,会触发此函数
void BootAnimation::onFirstRef() { //监听死亡事情,参数this指定接收回调的对象 status_t err = mSession->linkToComposerDeath(this); if (err == NO_ERROR) { run("BootAnimation", PRIORITY_DISPLAY);//新线程启动开机动画业务 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
能看到BootAnimation继承IBinder::DeathRecipient,并实现了binderDied接口函数,run开启新线程,main函数中开启了线程池,不能让一个线程既监视binder状态,又运行业务,当一个新线程启动的时候会触发readyToRun()
status_t BootAnimation::readyToRun() { //第一部分、向SurfaceFlinger索要Buffer,上面看到session就是SurfaceComposerClient, //也就是ISurfaceComposerClient sp<SurfaceControl> control = session()->createSurface(String8("BootAnimation"), dinfo.w, dinfo.h, PIXEL_FORMAT_RGB_565); SurfaceComposerClient::Transaction t; t.setLayer(control, 0x40000000).apply(); sp<Surface> s = control->getSurface();//这里的Surface就是Buffer产品 //第二部分、配置EGL const EGLint attribs[] = { EGL_RED_SIZE, 8, EGL_GREEN_SIZE, 8, EGL_BLUE_SIZE, 8, EGL_DEPTH_SIZE, 0, EGL_NONE }; EGLint w, h; EGLint numConfigs; EGLConfig config; EGLSurface surface; EGLContext context; //Step1、得到默认物理屏幕 EGLDisplay display = eglGetDisplay(EGL_DEFAULT_DISPLAY); //Step2、初始化 eglInitialize(display, nullptr, nullptr); //Step3、选择最佳config eglChooseConfig(display, attribs, &config, 1, &numConfigs); //Step4、通过本地窗口创建Surface surface = eglCreateWindowSurface(display, config, s.get(), nullptr); context = eglCreateContext(display, config, nullptr, nullptr);//创建context return NO_ERROR; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
这个函数的第一部分是应用程序与SurfaceFlinger中的BufferQueue的通信过程,第二部分更是一个重要的学习点,OpenGL ES和EGL的使用流程。session()->createSurface,可以看到session就是SurfaceComposerClient,最终由SurfaceFlinger相关联的匿名服务来实现,Server端的实现是
/*frameworks\native\services\surfaceflinger\Client.cpp*/ status_t Client::createSurface(...){ sp<MessageBase> msg = new MessageCreateLayer(mFlinger.get(), name, this, w, h, format, flags, handle, gbp); mFlinger->postMessageSync(msg); return static_cast<MessageCreateLayer*>( msg.get() )->getResult(); } //高版本有点差别,直接把参数传递给SurfaceFlinger,其实质逻辑没什么差别 status_t Client::createSurface(...) { return mFlinger->createLayer(name, this, w, h, format, flags, std::move(metadata), handle, gbp,parentHandle); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这个函数只是个跳板,全部传递给SurfaceFlinger,感觉新版函数逻辑更清晰,
/*frameworks\native\services\surfaceflinger\SurfaceFlinger.cpp*/ status_t SurfaceFlinger::createLayer(...LayerMetadata metadata, sp<IBinder>* handle, sp<IGraphicBufferProducer>* gbp, const sp<IBinder>& parentHandle, const sp<Layer>& parentLayer) { status_t result = NO_ERROR; sp<Layer> layer; switch (flags & ISurfaceComposerClient::eFXSurfaceMask) { case ISurfaceComposerClient::eFXSurfaceNormal: result = createNormalLayer(client, uniqueName, w, h, flags, format, handle, gbp, &layer); break; case ISurfaceComposerClient::eFXSurfaceDim: result = createDimLayer(client, uniqueName, w, h, flags, handle, gbp, &layer); break; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
sp<IGraphicBufferProducer * gbp参数,说明SurfaceFlinger生成了IGraphicBufferProducer对象,注意这里出现了新的概念Layer,在SurfaceFlinger中代表图层,最终物理屏幕上显示结果就是通过对系统中同时存在的所有画面进程合成处理形成的。比如某个APP中activity一个跳一个,跳了三个,前俩个activity背景是透明的,那么这三个activity会同时都显示到屏幕上,why?这就是Layer-层级的概念。
再举个例子:你在三块玻璃上画画,然后把三块玻璃叠在一起,我们当然能通过透明的玻璃看到第三块玻璃上画的是什么,图画会叠起来。
也能得出一个结论,UI是有Layer-层级的,越靠近用户的层越能展示完整。
再返回到BootAnimation::readyToRun()的函数中,看到setLayer( 0x40000000),是不是恍然大悟,这个0x40000000就是Layer的层级,数字越大越靠近用户。在BootAnimation显示时还只有这么一个应用程序,所以这个数值足够使用了。设置完层级后,根据sp s = control->getSurface();得到一个Surface本地窗口,
总结:
1、ISurfaceComposerClient:是应用程序和SurfaceFlinger之间的通道,在应用程序进程中被封装在SurfaceComposerClient类中,这是个匿名Binder服务,有应用程序调用SurfaceFlinger这个实名BinderServer的createConnect函数来获取,服务端的实现是SurfaceFlinger::client()
2、IGraphicBufferProducer:由应用程序调用ISurfaceComposerClient::createSurface()获取,此时在SurfaceFlinger中Layer被创建出来,代表一个图画,ISurface就是就是控制这个图画的handle,保存在应用进程端的SurfaceControl中
3、Surface:是ISurface的使用者,是一个本地窗口,内部持有IGraphicBufferProducer,就是BufferQueue的实现接口,当EGL想通过Surface这个本地窗口绘制UI时,Surface内部又使用ISurface和IGraphicBufferProducer来获取远程服务端的功能来完成EGL的请求任务继续回到BootAnimation::readyToRun()函数中,完成一个Surface创建与填充后,就开始EGL的调用,注释中步骤很清晰。EGL准备好环境后,应用程序就可以正常使用OpenGL ES提供的各种API进行绘图。具体逻辑在threadLoop()、android()、movie()中。
到目前为止我们没有看到BufferQueue相关,之前用诸多篇幅来阐述BufferQueue,说它是装Buffer产品的容器,dequeue和queue都是操作它,显然在Surface显示体系中不可能把它漏掉,那么BufferQueue是从哪开始介入的?
3.4.1BufferQueue和应用进程的衔接逻辑
当应用程序通过ISurfaceComposerClient::createSurface来发起创建Surface请求时,SurfaceFlinger服务端这里会创建一个Layer图层,用来承载图形,那么图形的数据,是在哪里存放?接着SurfaceFlinger::createLayer来看,选择createNormalLayer来继续分析
/*frameworks\native\services\surfaceflinger\SurfaceFlinger.cpp*/ status_t SurfaceFlinger::createNormalLayer(const sp<Client>& client, const String8& name, uint32_t w, uint32_t h, uint32_t flags, PixelFormat& format, sp<IBinder>* handle, sp<IGraphicBufferProducer>* gbp, sp<Layer>* outLayer) { *outLayer = new Layer(this, client, name, w, h, flags); status_t err = (*outLayer)->setBuffers(w, h, format, flags); if (err == NO_ERROR) { *handle = (*outLayer)->getHandle(); *gbp = (*outLayer)->getProducer(); } ALOGE_IF(err, "createNormalLayer() failed (%s)", strerror(-err)); return err; } //getProducer()就是Layer里的mProducer /*frameworks/native/services/surfaceflinger/Layer.cpp*/ void Layer::onFirstRef() { sp<IGraphicBufferProducer> producer; sp<IGraphicBufferConsumer> consumer; BufferQueue::createBufferQueue(&producer, &consumer, true); mProducer = new MonitoredProducer(producer, mFlinger, this); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
创建一个图层,然后给它Buffer属性,getHandle没啥用不理它,getProducer很重要,从上下两个变量类型就能看出来是和BufferQueue相关的(从IGraphicBufferConsumer中拿到),也就是说Layer直接或间接的提供了BufferQueue(匿名Binder服务),当应用程序调用Surface::createSurface时,就能通过Layer获取到生产者-消费者模式下的承载产品Buffer的容器BufferQueue。
注意:我们再次强调,IGraphicBufferProducer在Binder Server端的实现是BufferQueue,因为客户端和服务端的名称风马牛不相及,很容易让人怀疑人生
最后用例图总结下整体流程(来自实体书),这张图是应用程序到SurfaceFlinger的纵向流程图

因为涉及到的IPC调用非常多,再用一张图展示横向client到server逻辑对应关系

下图是整体上从Java层应用程序申请Surface到SurfaceFlinger响应合成的示意图:
四、应用程序Surface的合成者-SurfaceFlinger
- SurfaceFlinger启动过程运行逻辑
- Surface与BufferQueue和应用程序的关联
- SurfaceFlinger对Vsync信号的处理过程
4.1 SurfaceFlinger的前世今生
SurfaceFlinger是4.1的版本引入的,为了解决Android系统UI交互卡顿而重新架构了一套用应用程序上层到底层模块(场频刷新的Vsync和multi buffer),我们需要明白本质上的卡顿究竟是什么引起的?这就是SurfaceFlinger框架的作用、目的。
卡顿,就是屏幕显示图形时无法实时显示current画面,画面撕裂、延迟、卡死等等,无论是什么原因,最终的结果一定是这样。UI显示是由屏幕展示,应用程序产生。屏幕硬件是周期刷新的,换言之:展示是以一定的时间间隔周期进行的(60Hz或者一个数值),产生是任意时刻且产生的时间可能短(在展示的周期内完成,过短就会出现丢帧),也可能占用的太长了(跨越了好几个展示周期),出现这种异常时,屏幕智能不停的展示之前那一帧图像,造成卡顿,能看出来展示的间隔与产生的时间段就是影响显示流畅度的维度。
用一个例子来说明:
假设屏幕显示器刷新频率是90Hz,CPU/GPU绘图能力是200Hz,俩者处理一帧图像数据分别需要:0.01s和0.005s,这样当应用软件准备好几帧图形,但屏幕还在显示第一帧,就会出现丢帧。反之,屏幕就会被迫等待,一直显示同一帧数据。
解决这种问题的办法就是Multi Buffer,在第三节时讲过,但光是MultiBuffer还是无法避免Jank(卡顿,几个周期内都显示同一个图像帧),因此同时需要Vsync场频刷新机制(同时作用于屏幕硬件和软件绘制渲染体系)。大家还记得我们老是说一个Activity(或者自定义绘制)的布局,不能太复杂,要在16.6ms内完成吗?真实原因就在于大部分Android设备屏幕刷新频率是60Hz,因此每一帧最多留给系统1/60 = 16.6ms的时间。
4.2 SurfaceFlinger启动
SurfaceFlinger属于系统核心服务,老版是System_server进程启动的,高版本是在init脚本启动,当然你在init.rc里找不到,SF服务属于core服务,init.rc中会启动后者,core启动后就会拉起surfaceflinger.rc(frameworks/native/services/surfaceflinger/surfaceflinger.rc),然后启动Main_surfaceflinger.cpp的main函数
/*frameworks\native\services\surfaceflinger\Main_surfaceflinger.cpp*/ int main(int, char**) { signal(SIGPIPE, SIG_IGN);//设置让系统忽略SIGPIPE信号,这个信号作用是终止程序 //sf service启动时要设置binder的线程池,设置当前进程和 hwbinder 通信的最大线程数 hardware::configureRpcThreadpool(1 /* maxThreads */,false /* callerWillJoin */); startGraphicsAllocatorService();//启动图形分配器服务 //sf服务进程启动后,限制进程中binder线程数量为4 ProcessState::self()->setThreadPoolMaxThreadCount(4); sp<ProcessState> ps(ProcessState::self()); ps->startThreadPool();//开启线程池 //instantiate surfaceflinger sp<SurfaceFlinger> flinger = surfaceFlinger::createSurfaceFligner(); if(cpusets_enable()) set_cpuset_policy(0,SP_SYSTEM);//cpu 策略,sf被限制在了小核 // publish surface flinger sp<IServiceManager> sm(defaultServiceManager()); sm->addService(String16(SurfaceFlinger::getServiceName()), flinger, false, IServiceManager::DUMP_FLAG_PRIORITY_CRITICAL | IServiceManager::DUMP_FLAG_PROTO); startDisplayService(); // 依赖于SF在上面注册,启动DisplayService // run surface flinger in this thread flinger->run(); return 0; } /*frameworks\native\services\surfaceflinger\SurfaceFlingerFactory.cpp*/ sp<SurfaceFlinger> createSurfaceFlinger(){ ... static DefaultFactory factory; return new SurfaceFlinger(factory); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
4.3 SurfaceFlinger服务的提供
SurfaceFlinger(后续简称SF服务)运行后,需要显示UI界面的应用程序通过Binder服务与之进程跨进程通信,每个应用程序在SF进程中都有对应的client实例(通过ISurfaceComposerClient接口),Binder接口在服务端的实现就是Client,继承自BnSurfaceComposerClient(继承ISurfaceComposerClient接口和一些Binder、智能指针的基类),因此ISurfaceComposerClient提供两个最重要的接口就是
- createSurface
- destroySurface
早期createSurface是返回ISurface的Binder接口,现在已经改了,可以理解成Surface在服务端对应的是Layer,某个应用进程在同一时刻所需要的Surface可能不止是一个,例如有相机预览的情况下,SurfaceView这个UI控件也要独占一个Surface(为了更好的预览视频流刷新流畅度)
4.3.1 获取SurfaceFlinger服务
通过SurfaceFlinger::createConnection获取,前边已经知道是三个匿名服务,因此需要通过实名BinderServer来获取
/*frameworks\native\services\surfaceflinger\SurfaceFlinger.cpp*/ sp<ISurfaceComposerClient> SurfaceFlinger::createConnection() { return initClient(new Client(this));//initClient是检查权限,无关逻辑 }- 1
- 2
- 3
- 4
这样就返回了ISurfaceComposerClient,开始调用Client::createSurface(这里开始在3.4 Android系统开机示例分析中详细分析过就不在重复,大家可以回过头去看),返回IGraphicBufferProducer,服务端的实现是BufferQueue,至此获取到SurfaceFlinger服务
4.4 VSync信号
Vsync信号是Android4.1加入进来的同步机制,我们用最直白的话来描述作用:确立一个绝对准确的定时器,到点后通知其他程序做任务。因此所提供的功能就能猜出来:
- VSync信号的产生和分发,由谁产生,分发过程
- VSync信号处理,应用(SurfaceFlinger)收到信号,怎么处理
4.4.1 VSync信号产生和分发
回忆一下,第一章节我们说过hal层另一个重要部分就是厂商自定义合成模块Composer,由SurfaceFlinger的HWComposer模块,后者除了管理hal层的Composer,还负责VSync信号的产生,我们也说过VSync信号可以由软件模拟产生,也可以由硬件来真实产生(当然硬件的成本要高,但肯定是靠谱,任何软件不可能完全不出现bug),下面来看HWComposer,Android源码的surfaceflinger目录下有displayhardware文件夹,HWComposer在这里,关于版本差异需要说明下:
在Android6.0时,HWComposer模块既有硬件源产生也有软件(VSyncThread线程)产生,到7.0以后就强制使用硬件源产生信号了,因此现在的版本中已经找不到软件源的线程
为了展示VSyncThread线程,这里选用低版本。
/*frameworks/native/services/surfaceflinger/DisplayHardware/HWComposer.cpp*/ HWComposer::HWComposer( const sp<SurfaceFlinger>& flinger, EventHandler& handler) : mFlinger(flinger), mFbDev(0), mHwc(0), mNumDisplays(1), mCBContext(new cb_context), mEventHandler(handler), mDebugForceFakeVSync(false) { ... //是否需要软件模拟产生VSync信号,默认true bool needVSyncThread = true; ... loadHwcModule();//加载hal模块(HWComposer) if (mHwc) {//注册硬件回调 if (mHwc->registerProcs) { mCBContext->hwc = this; mCBContext->procs.invalidate = &hook_invalidate; mCBContext->procs.vsync = &hook_vsync; if (hwcHasApiVersion(mHwc, HWC_DEVICE_API_VERSION_1_1)) mCBContext->procs.hotplug = &hook_hotplug; else mCBContext->procs.hotplug = NULL; memset(mCBContext->procs.zero, 0, sizeof(mCBContext->procs.zero)); mHwc->registerProcs(mHwc, &mCBContext->procs); } needVSyncThread = false;//不需要软件模拟了 } ... if (needVSyncThread) { mVSyncThread = new VSyncThread(*this); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
1、硬件源
mHwc->registerProcs不等于空时,此时注册的硬件回调是mCBContext->procs,当硬件源产生Vsync和invalidate时,分别通过procs.vsync和procs.invalidate来通知HWComposer,void HWComposer::vsync(int disp, int64_t timestamp) { mEventHandler.onVSyncReceived(disp, timestamp); }- 1
- 2
- 3
HWComposer将VSync信号传递给了mEventHandler,后者是HWComposer构造函数传进来的,因此需要追踪是谁创建了HWComposer?
/*frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp*/ void SurfaceFlinger::init() { ... mHwc = new HWComposer(this,*static_cast<HWComposer::EventHandler *>(this)); }- 1
- 2
- 3
- 4
- 5
因此mEventHandler就是SurfaceFlinger自己,显然SurfaceFlinger会继承HWComposer::EventHandler,才能回调onVSyncReceived来处理VSync信号。
2、软件源
软件源是启用VSyncThread线程来生成:/*frameworks/native/services/surfaceflinger/DisplayHardware/HWComposer.cpp*/ bool HWComposer::VSyncThread::threadLoop() { { //Step1、自动锁控制,因此要加{}来限制范围 Mutex::Autolock _l(mLock); while (!mEnabled) { mCondition.wait(mLock); } } /*Step2、计算需要产生VSync信号的时间点*/ const nsecs_t period = mRefreshPeriod;//信号的产生间隔 const nsecs_t now = systemTime(CLOCK_MONOTONIC); nsecs_t next_vsync = mNextFakeVSync;//产生信号的时间 nsecs_t sleep = next_vsync - now;//需要休眠的时间段 if (sleep < 0) {//如果这个时间已经过去了,计算出下一个产生信号的时间 // we missed, find where the next vsync should be sleep = (period - ((now - next_vsync) % period)); next_vsync = now + sleep; } mNextFakeVSync = next_vsync + period;//下次的VSync时刻 struct timespec spec; spec.tv_sec = next_vsync / 1000000000; spec.tv_nsec = next_vsync % 1000000000; int err; do { //进入休眠 err = clock_nanosleep(CLOCK_MONOTONIC, TIMER_ABSTIME, &spec, NULL); } while (err<0 && errno == EINTR); if (err == 0) { mHwc.mEventHandler.onVSyncReceived(0, next_vsync);//和硬件源一样的回调 } return true; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
这里的逻辑很好懂,用低版本来展示软件源产生VSync信号方式,主要是我们可以学学这种周期执行任务的算法,因为对时间精度要求很高,这里时间单位采用nanosecond–纳秒级。CLOCK_MONOTONIC这种时钟更加稳定,不受系统的影响。这里我们看到整体上函数没有用循环,难道只需要一次调用吗?是因为threadLoop()函数返回true时,系统会再次调用它,这个逻辑实现是在Thread类中。
上面我们得出结论:不论是HWComposer还是VsyncThread,当产生VSync信号后最后都是回调到SurfaceFlinger::onVSyncReceived,在高版本中函数源码是这样的:
/*frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp*/ void SurfaceFlinger::onVsyncReceived(int32_t sequenceId, hwc2_display_t hwcDisplayId, int64_t timestamp) { ATRACE_NAME("SF onVsync"); Mutex::Autolock lock(mStateLock); ... if (!getHwComposer().onVsync(hwcDisplayId, timestamp)) { return; } bool periodFlushed = false; mScheduler->addResyncSample(timestamp, &periodFlushed); if (periodFlushed) { mVsyncModulator.onRefreshRateChangeCompleted(); } } void SurfaceFlinger::init() { // start the EventThread mScheduler = getFactory().createScheduler([this](bool enabled) { setVsyncEnabled(enabled); }, mRefreshRateConfigs); auto resyncCallback = mScheduler->makeResyncCallback(std::bind(&SurfaceFlinger::getVsyncPeriod, this)); mAppConnectionHandle = mScheduler->createConnection("app"/*Step1*/, mVsyncModulator.getOffsets().app, mPhaseOffsets->getOffsetThresholdForNextVsync(), resyncCallback, impl::EventThread::InterceptVSyncsCallback()); mSfConnectionHandle = mScheduler->createConnection("sf"/*Step2*/, mVsyncModulator.getOffsets().sf, mPhaseOffsets->getOffsetThresholdForNextVsync(), resyncCallback, [this](nsecs_t timestamp) { mInterceptor->saveVSyncEvent(timestamp); }); mEventQueue->setEventConnection(mScheduler->getEventConnection(mSfConnectionHandle)); mVsyncModulator.setSchedulerAndHandles(mScheduler.get(), mAppConnectionHandle.get(), mSfConnectionHandle.get()); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
这里出现了一堆Scheduler调度器类的变量,总归它们是给EventThread和EventQueue使用的,见名知意,将信号事件投递到EventQueue队列中来管理,
注意:Step1、Step2,app和sf代表VSync两种信号,app是给应用程序使用的,sf是SurfaceFlinger自己使用的信号这里就引出另外一个概念,谁在使用VSync信号?
- 需要刷新UI的各个应用程序,应用程序是UI数据的真正生产者,它需要监听VSync信号,从这里我们能看出来,上层应用的VSync信号也是SurfaceFlinger给送上去的,后者提供了SurfaceFlinger::createDisplayEventConnection接口函数供应用程序使用,函数内部将其传送给EventThread管理队列
- SurfaceFlinger,它需要在规定的周期内合成Buffer,必须收集VSync信号,也是由核心的EventQueue队列来完成,也会使用EventThread::createDisplayEventConnection创建connection并添加到EventThread管理队列,而对于SurfaceFlinger来说,注册了VSync信号的其实就是MessageQueue
最后当产生VSync的信号流转到SurfaceFlinger::onVSyncReceived,最终EventThread会将VSync信号分发给使用createDisplayEventConnection函数注册过的进程
4.4.2 VSync处理
上节我们知道了系统如何通过软硬件源产生VSync信号并分发给注册者,而SurfaceFlinger的VSync信号注册者就是MessageQueue,后者通过与EventThread建立一个Connection来监听VSync信号,
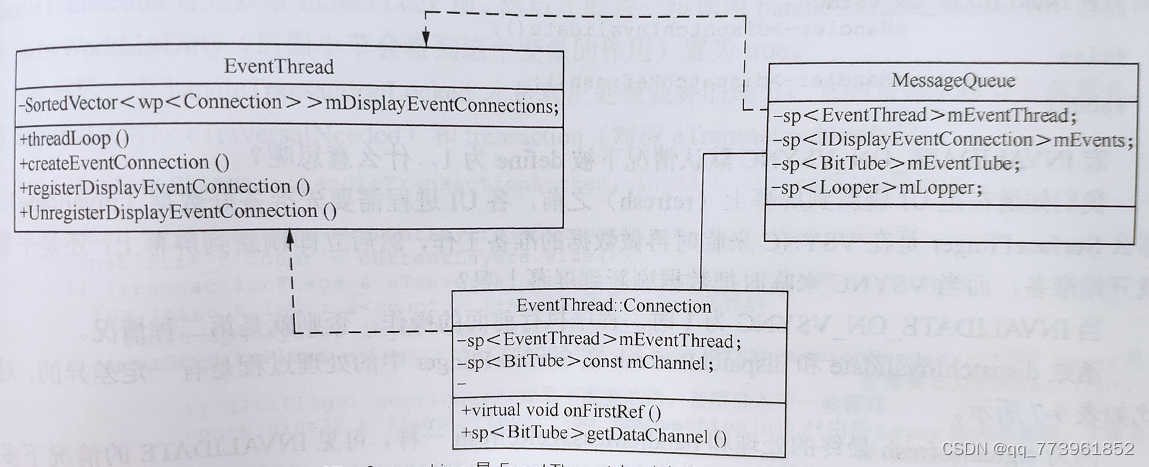
任意需要VSync信号的对象(例如MessageQueue),首先要通过调接口EventThread::createEventConnection建立一个连接(上层的应用进程是借用SurfaceFlinger来做),此时生成EventThread::Connection对象,此时当Connection::onFirstRef,也就是这个连接首次被引用时,会主动调用EventThread::registerDisplayEventConnection将自己(connection)添加到EventThread的mDisplayEventConnection中,这样VSync信号发生时才能知道应该要回调通知谁去;当MessageQueue拿到这个Connection,会调用getDataChannel获得一个BitTube。Connection是两端的连接,getDataChannel是数据传输的通道,Event的各种信息就是通过它来传递。以MessageQueue举例分析各进程是怎么与EventThread通信交互的:
void MessageQueue::setEventThread(android::EventThread* eventThread) { .... mEventThread = eventThread; mEvents = eventThread->createEventConnection();//建立连接 mEvents->stealReceiveChannel(&mEventTube);//获取通道 mLooper->addFd(mEventTube.getFd(), 0, Looper::EVENT_INPUT, MessageQueue::cb_eventReceiver,this); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
EventThread可以当做是生产者,不停的往Tube里写数据,MessageQueue是消费者,不停的读取数据,MessageQueue如何知道有消息来了??它就正好去取了呢?因为这个channel通道是socket读写模式(AF_UNIX域),因此可以随时知道,这里我们能学习到一个点,如果有这种类似的需求,两端就像是生产者-消费者,不用定时器去不停的读,也不用非得写个异常复杂回调逻辑,可以学习源码的这种思想,用socket来解决问题(AF_UNIX域的socket,本地环境的不会额外耗资源)。mLooper->addFd,这个fd就是socketPair中的一端,它将fd和MessageQueue::cb_eventReceiver一起放到全局的mRequests进行管理,后者会存储所有需要监测的fd,这样当EventQueue体系中因为VSync信号发生Looper的pollinner时,只要有事件需要处理,就可以通过callback通知到应用进程。
当Event事件发生时,MessageQueue::cb_eventReceiver就会被回调,进一步调用MessageQueue::eventReceiver,如果此时事件标志是DisplayEventReceiver::DISPLAY_EVENT_VSYNC,代表监听的事件正是VSync信号,进一步调用MessageQueue::Handler::dispatchInvalidate(),此时会给Handler发Msg,最终MessageQueue调用SurfaceFlinger::onMessageReceived,而 后者又有两个case分支
void SurfaceFlinger::onMessageReceived(int32_t what) NO_THREAD_SAFETY_ANALYSIS { switch (what) { case MessageQueue::INVALIDATE: { handleMessageTransaction(); handleMessageInvalidate(); signalRefresh(); } break; case MessageQueue::REFRESH: { handleMessageRefresh(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这俩case的差别:
1、INVALIDATE:当VSync信号来临时,SurfaceFlinger才开始准备合成各UI进程的图形数据,合成后立即刷新到屏幕上
2、REFRESH:SurfaceFlinger在平时就开始合成各UI进程的图形数据,当VSync信号来临时直接把数据刷新到屏幕上好像一般情况会走MessageQueue::INVALIDATE这个分支。源码中能看到两分支的处理逻辑不一样,handleMessageTransaction()主要作用于客户端发起的对Layer属性的变更业务,handleMessageInvalidate()主要是invalidate数据。
先看handleMessageRefresh()函数
void SurfaceFlinger::handleMessageRefresh() { ATRACE_CALL(); preComposition();//合成前的准备 rebuildLayerStacks();//重新申请Layer堆栈 setUpHWComposer(); doDebugFlashRegions(display, repaintEverything); doComposition(display, repaintEverything);//正式合成 postComposition(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
上述这些函数基本上涵盖了SurfaceFlinger的所有功能,下来详细分析
4.4.2.1 handleMessageTransaction-客户端发起的对Layer属性的变更业务
函数handleMessageTransaction在做了一些判断后,进入到handleTransaction,进一步调用到handleTransactionLocked
void SurfaceFlinger::handleTransactionLocked(uint32_t transactionFlags) { if ((transactionFlags & eTraversalNeeded/*Step1、是否需要Traversal*/) || mTraversalNeededMainThread) { //根据traverseInZOrder也能猜出来这是遍历找Layer mCurrentState.traverseInZOrder([&](Layer* layer) { //Step2、这个layer是否需要Transaction uint32_t trFlags = layer->getTransactionFlags(eTransactionNeeded); if (!trFlags) return; const uint32_t flags = layer->doTransaction(0);//layer内部执行 if (flags & Layer::eVisibleRegion)//layer计算可见区域是否发生变化 mVisibleRegionsDirty = true; if (flags & Layer::eInputInfoChanged) { mInputInfoChanged = true; } }); mTraversalNeededMainThread = false; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
enum{
eTransactionNeeded = 0x01,
eTraversalNeeded = 0x02,
eDisplayTransactionNeeded = 0x04,
eTransactionMask = 0x07
}
上述几种Flag就是从中取值,SurfaceFlinger记录当前系统中的Layer状态有两个全局变量{mDrawingState,mCurrentState},前者是上次drawing时的状态,后者是当前状态,两者对比就能知道Layer发生了什么变化进而执行对应操作。下面来看看Layer内部是怎么执行事务的:layer->getTransactionFlags/*frameworks\native\services\surfaceflinger\Layer.cpp*/ uint32_t Layer::doTransaction(uint32_t flags) { if (mChildrenChanged) { flags |= eVisibleRegion; mChildrenChanged = false; } State c = getCurrentState();//mCurrentState flags = doTransactionResize(flags, &c); const State& s(getDrawingState());//mDrawingState if (getActiveGeometry(c) != getActiveGeometry(s)) { // invalidate and recompute the visible regions if needed flags |= Layer::eVisibleRegion; } if (c.sequence != s.sequence) {//Part1 // invalidate and recompute the visible regions if needed flags |= eVisibleRegion; this->contentDirty = true;//重绘 // we may use linear filtering, if the matrix scales us const uint8_t type = getActiveTransform(c).getType(); mNeedsFiltering = (!getActiveTransform(c).preserveRects() || type >= ui::Transform::SCALE); } commitTransaction(c); mCurrentState.callbackHandles = {}; return flags; } uint32_t Layer::doTransactionResize(uint32_t flags, State* stateToCommit) { const State& s(getDrawingState()); const bool sizeChanged = (stateToCommit->requested_legacy.w != s.requested_legacy.w) || (stateToCommit->requested_legacy.h != s.requested_legacy.h); if (sizeChanged) { // the size changed, we need to ask our client to request a new buffer //设置到BufferQueue中,当我们调用requestBuffer时,如果没有指定w、h,就会使用 //这里设置的默认值 setDefaultBufferSize(c.requested.w, c.requested.h); } } void Layer::commitTransaction(const State& stateToCommit) { //提交事务时将当下状态赋值给mDrawingState,完成一轮逻辑业务的循环,下次继续 mDrawingState = stateToCommit; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
Layer::doTransaction内部,主要是判断mCurrentState与mDrawingState的宽高有没有差异,Part1需要着重说明下,sequence 是一个int值,当Layer的position、z-order、alpha、matrix、transparent region、flags、crop等一系列的属性发生变化时,mCurrentState就会自增,因此当doTransaction时,它与mDrawingState::sequence 值就会产生差异。能看到Layer::doTransaction主要作用就是根据当前和上一次两种状态来判断是否需要重新计算可见区域、重绘等下一步的操作。
当完成Layer遍历后,SurfaceFlinger就要开始干自己的工作了:
- 新增Layer,和上次处理时相比,系统可能新增了Layer,此时需要对比两个state中的Layer队列数量,如果Layer数量增加、可见区域就需要重新计算,就把mVisibleRegionsDirty赋值为true
- 移除Layer,其实逻辑一样,增和删是一个判断逻辑,当有Layer数量减少后,也需要重新计算可见区域,因为这个Layer之前遮盖的区域可能会重新露出来。移除计算后需要通知被移除的Layer,回调函数是onRemoved(),这样Layer就能知道这个Layer被SurfaceFlinger剔除了
最后唤醒所有正在等待Transaction结束的线程,mTransactionCV.broadcast();
4.4.2.2 handleMessageInvalidate-界面无效需重新绘制
自定义view中会使用很多invalidate,动画基本也是由它来驱动的,字面意思是"使无效",需重新绘制。在SurfaceFlinger中,invalidate实际上就是操作Buffer数据,handleMessageInvalidate()接着就调用了handlePageFlip(),PageFlip可理解成"翻页",翻的是什么页呢?multi-buffer,因为hal层的Gralloc模块打开的fb0设备提供了多缓冲机制,某个时刻确实是需要切换Buffer的。源码如下:
bool SurfaceFlinger::handlePageFlip() { ATRACE_CALL(); ... for (auto& layer : mLayersWithQueuedFrames) { const Region dirty(layer->latchBuffer(visibleRegions, latchTime)); layer->useSurfaceDamage(); invalidateLayerStack(layer, dirty); if (layer->isBufferLatched()) { newDataLatched = true; } } ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
使用latchBuffer分别锁住各Layer当前要处理的缓冲区。缓冲区当然就是Buffer,Layer继承了FrameAvailableListener,专门用于监听onFrameAvailable。所以当BufferQueue中的某个BufferSlot被queued后,Layer就会接收到(onFrameAvailable函数中mQueuedFrames计数就开始增加)。这个函数非常复杂
//BufferLayer继承Layer Region BufferLayer::latchBuffer(bool& recomputeVisibleRegions, nsecs_t latchTime) { ATRACE_CALL(); ... // This boolean is used to make sure that SurfaceFlinger's shadow copy // of the buffer queue isn't modified when the buffer queue is returning // BufferItem's that weren't actually queued. This can happen in shared // buffer mode. bool queuedBuffer = false; LayerRejecter r(mDrawingState, getCurrentState(), recomputeVisibleRegions, getProducerStickyTransform() != 0, mName.string(), mOverrideScalingMode, mFreezeGeometryUpdates); status_t updateResult = mConsumer->updateTexImage(&r, mFlinger->mPrimaryDispSync, &mAutoRefresh, &queuedBuffer, mLastFrameNumberReceived); if ((queuedBuffer && android_atomic_dec(&mQueuedFrames) > 1) || mAutoRefresh) { mFlinger->signalLayerUpdate(); } // update the active buffer getBE().compositionInfo.mBuffer = mConsumer->getCurrentBuffer(&getBE().compositionInfo.mBufferSlot); // replicated in LayerBE until FE/BE is ready to be synchronized mActiveBuffer = getBE().compositionInfo.mBuffer; if (getBE().compositionInfo.mBuffer == nullptr) { // this can only happen if the very first buffer was rejected. return outDirtyRegion; } ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
还记得吗,如果SurfaceFlinger想对BufferQueue中的某个Buffer进行操作,需要acquire它-这个操作在mConsumer->updateTexImage中,latchBuffer内部定义了个Reject结构体,并作为函数参数传递给updateTexImage
/*frameworks/native/services/surfaceflinger/BufferLayerConsumer.cpp*/ status_t BufferLayerConsumer::updateTexImage(BufferRejecter* rejecter, const DispSync& dispSync, bool* autoRefresh, bool* queuedBuffer, uint64_t maxFrameNumber) { Mutex::Autolock lock(mMutex); status_t err = acquireBufferLocked(&item, computeExpectedPresent(dispSync), maxFrameNumber);//acquire一个buffer if (rejecter && rejecter->reject(mSlots[slot].mGraphicBuffer, item)) { releaseBufferLocked(slot, mSlots[slot].mGraphicBuffer); return BUFFER_REJECTED; } err = updateAndReleaseLocked(item, &mPendingRelease);//生成texture ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
1、acquire一个buffer,首先向BufferQueue申请,后者怎么分辨应该操作哪一个buffer呢,是因为BufferQueue内部维护一个FIFO的队列,一旦Buffer被enqueued后,就会被压入队尾,每次acquire从队头拿,完成后会从队列中移除
2、acquire到的Buffer放到BufferItem中item.mBuf代表其序号,SurfaceFlinger会判断这个Buffer是否合法(例如size是否正确等等),这里是通过rejecter内部操作的
3、生成Texture,内部是去调用OpenGL ES的接口
4、处理完Buffer就可以release了,然后这个Buffer又恢复到Free状态,以供生产者再次dequeue。4.4.2.3 preComposition–合成前的准备
在分析preComposition前,要插入VSync Rate。IDisplayEventConnection提供了与VSync Rate有关的两个接口:
- setVsyncRate,设置为1后,表示每个VSync信号都要报告,2代表隔一个VSync信号报告一次,0是不上报任何VSync信号,除非有人主动调用requestNextVsync
- requestNextVsync,除非setVsyncRate设置为0,否则直接调用requestNextVsync是无效的
void SurfaceFlinger::preComposition() { ATRACE_CALL(); mRefreshStartTime = systemTime(SYSTEM_TIME_MONOTONIC); bool needExtraInvalidate = false; mDrawingState.traverseInZOrder([&](Layer* layer) { if (layer->onPreComposition(mRefreshStartTime)) {//调用layer的预合成接口 needExtraInvalidate = true; } }); if (needExtraInvalidate) { signalLayerUpdate();//Step2、 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
逻辑很简单,layer->onPreComposition循环调用每个Layer让图形自行先准备,Layer里的onPreComposition会返回bool值,就是看mQueueFrames(就是在BufferQueue队列里,存在不存在已经queued状态的buffer)是否大于0(true/false),有queued状态Buffer后,就开始"使无效",走进Step2,SurfaceFlinger::signalLayerUpdate()->MessageQueue::invalidate()->IDisplayEventConnection::requestNextVsync()->EventThread::requestNextVsync:
void EventThread::requestNextVsync(const sp<EventThread::Connection>& connection) { std::lock_guard<std::mutex> lock(mMutex); if (mResyncWithRateLimitCallback) { mResyncWithRateLimitCallback(); } if (connection->count < 0) {//<0 说明disabled connection->count = 0;//=0说明还有可以接收一次event mCondition.notify_all();//通知EventThread,有人对VSync感兴趣 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 大于等于1:可以连续接收事件。
- = 0:一次性事件,还未接收
- = -1:这个事件接收被取消了
mCondition.notify_all,这里唤醒的还是EventThread,EventThread::threadLoop会不断调用waitForEvent来等待Event。这个函数内部还会去判断当前是否有用户对VSync信号感兴趣(就是用connection->count来判断),有的话就正常返回,否则调用mCondition.wait开始等待,直到有人唤醒。
4.4.2.4 可见区域–rebuildLayerStacks
经过preComposition后,SurfaceFlinger::handleMessageRefresh()会接着调用rebuildLayerStacks,它的作用就是重新计算所以可见的Layer以及它的可见区域,来看源码:
void SurfaceFlinger::rebuildLayerStacks() { if (CC_UNLIKELY(mVisibleRegionsDirty)) { ATRACE_NAME("rebuildLayerStacks VR Dirty"); mVisibleRegionsDirty = false; invalidateHwcGeometry(); for (const auto& pair : mDisplays) { const auto& displayDevice = pair.second; auto display = displayDevice->getCompositionDisplay(); const auto& displayState = display->getState(); Region opaqueRegion;//不透明区域 Region dirtyRegion;//脏区域 compositionengine::Output::OutputLayers layersSortedByZ; Vector<sp<Layer>> deprecated_layersSortedByZ;//最终排序后可见的Layer Vector<sp<Layer>> layersNeedingFences; const ui::Transform& tr = displayState.transform; const Rect bounds = displayState.bounds;//display区域 if (displayState.isEnabled) { //计算可见区域 computeVisibleRegions(displayDevice, dirtyRegion, opaqueRegion); mDrawingState.traverseInZOrder([&](Layer* layer) { auto compositionLayer = layer->getCompositionLayer(); if (compositionLayer == nullptr) { return; } ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
dirtyRegion-脏区域是要被重新绘制的区域,opaqueRegion不透明区域会对Z-Ordered的Layer图形产生影响,因为排在前边的Layer不透明区域会遮挡后边的Layer。这部分函数异常复杂,我现在看不懂。。。等我研究明白再来解释,重要的就是系统上的Layer图层,首先是用Z-Ordered排序,然后最大的Layer它就越靠近用户,因此它的透明度、大小都会影响到Layer最终合成,用这个逻辑我们也能确认一个事情,这种循环计算所有Layer,肯定是用递减的方式,这样的算法最省事,离用户最近的Layer,如果它大小和屏幕w、h一样,然后完全不透明,后续完全不需要计算了,因为全被遮盖了。总之SurfaceFlinger::rebuildLayerStacks,就是计算所有Layer的可见区域。
4.4.2.5 setUpHWComposer
要合成的UI数据经过上一步已经做好了,这一步就是为合成搭建好环境。有关HWComposer之前说过,有俩个:
\frameworks\native\services\surfaceflinger\DisplayHardware\HWComposer.h hardware\libhardware\include\hardware\hwComposer.h- 1
- 2
第一个是为SurfaceFlinger管理HWComposer设计的,第二个是HAL模块定义。也就是说SurfaceFlinger里的HWComposer是一层封装、一直manager管理者的角色,目的是调用HAL层的hwcomposer模块。
Hal层的hwcomposer可以提供如下接口:接口 说明 prepare 在每帧图像合成前都会被调用,用于判断HWC模块在合成操作中应该完成哪些功能,prepare函数的第三个参数:hwc_display_contents_1_t** displays中有个hwc_layer_1_t hwLayers[0]的成员变量,hwc_layer_1_t结构体中有个compositionType,是HWC对prepare的回复 set 是为了替代eglSwapBuffers接口,通过prepare,SurfaceFlinger和HWC模块相互确认哪些Layer由HWC来处理,set函数就是将这些Layer具体数据传输给HWC eventControl 用于控制display相关的event开/关,例如HWC_EVENT_VSYNC blank 用于控制屏幕的开启和关闭 query 用于查询HWC各种状态 registerProcs 用于向HWC注册callback函数, compositionType这个type很重要,看看这个点:
compositionType type HWC_BACKGROUD 在prepare前被调用者设置的值,表明这是一个特别的background图层,此时只有backgroundColor是有效的 HWC_FRAMEBUFFER_TARGET 也是在prepare前被调用者设置的值,表明此图层是用OpenGL ES合成,而且需要HWC 1.1以后的版本才行 HWC_FRAMEBUFFER 在prepare前被调用者设置的值,同时要求HWC_GROMETRY_CHANGED也要置位,表示Layer图层通过OpenGL ES来绘制到FrameBuffer中 HWC_OVERLAY 在prepare的执行过程中由HWC模块来设置的值,表示Layer由HWC处理 也就是说合成过程既可以由HWC完成,也能由OpenGL ES来处理。具体采用哪种方式是由prepare的结果,也就是CompositionType来决定,HWC模块有几个重要接口:
- *invalidate----触发屏幕绘制
- *vsync----当HWC模块产生vsync信号就会回调此函数
- *hotplug----当一个display被connect绘制disconnected时回调
来看SetUpHWComposer函数
/**这里我们要注意高版本变成了calculateWorkingSet函数,其实本质作用是一样的 frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp*/ void SurfaceFlinger::calculateWorkingSet() { // build the h/w work list if (CC_UNLIKELY(mGeometryInvalid)) { mGeometryInvalid = false; for (const auto& [token, displayDevice] : mDisplays) { auto display = displayDevice->getCompositionDisplay(); setDisplayAnimating(displayDevice); uint32_t zOrder = 0; for (auto& layer : display->getOutputLayersOrderedByZ()) { auto& compositionState = layer->editState(); compositionState.forceClientComposition = false; if (!compositionState.hwc || mDebugDisableHWC || mDebugRegion) { compositionState.forceClientComposition = true; } // The output Z order is set here based on a simple counter. compositionState.z = zOrder++; // Update the display independent composition state. This goes // to the general composition layer state structure. // TODO: Do this once per compositionengine::CompositionLayer. layer->getLayerFE().latchCompositionState(layer->getLayer().editState().frontEnd, true); // Recalculate the geometry state of the output layer. layer->updateCompositionState(true); // Write the updated geometry state to the HWC layer->writeStateToHWC(true); } } } // Set the per-frame data for (const auto& [token, displayDevice] : mDisplays) { auto display = displayDevice->getCompositionDisplay(); const auto displayId = display->getId(); if (!displayId) { continue; } auto* profile = display->getDisplayColorProfile(); if (mDrawingState.colorMatrixChanged) { display->setColorTransform(mDrawingState.colorMatrix); } Dataspace targetDataspace = Dataspace::UNKNOWN; if (useColorManagement) { ColorMode colorMode; RenderIntent renderIntent; pickColorMode(displayDevice, &colorMode, &targetDataspace, &renderIntent); display->setColorMode(colorMode, targetDataspace, renderIntent); if (isHdrColorMode(colorMode)) { targetDataspace = Dataspace::UNKNOWN; } else if (mColorSpaceAgnosticDataspace != Dataspace::UNKNOWN) { targetDataspace = mColorSpaceAgnosticDataspace; } } for (auto& layer : displayDevice->getVisibleLayersSortedByZ()) { if (layer->isHdrY410()) { layer->forceClientComposition(displayDevice); } else if ((layer->getDataSpace() == Dataspace::BT2020_PQ || layer->getDataSpace() == Dataspace::BT2020_ITU_PQ) && !profile->hasHDR10Support()) { layer->forceClientComposition(displayDevice); } else if ((layer->getDataSpace() == Dataspace::BT2020_HLG || layer->getDataSpace() == Dataspace::BT2020_ITU_HLG) && !profile->hasHLGSupport()) { layer->forceClientComposition(displayDevice); } if (layer->getRoundedCornerState().radius > 0.0f) { layer->forceClientComposition(displayDevice); } if (layer->getForceClientComposition(displayDevice)) { ALOGV("[%s] Requesting Client composition", layer->getName().string()); layer->setCompositionType(displayDevice, Hwc2::IComposerClient::Composition::CLIENT); continue; } const auto& displayState = display->getState(); layer->setPerFrameData(displayDevice, displayState.transform, displayState.viewport, displayDevice->getSupportedPerFrameMetadata(), targetDataspace); } } mDrawingState.colorMatrixChanged = false; for (const auto& [token, displayDevice] : mDisplays) { auto display = displayDevice->getCompositionDisplay(); for (auto& layer : displayDevice->getVisibleLayersSortedByZ()) { auto& layerState = layer->getCompositionLayer()->editState().frontEnd; layerState.compositionType = static_cast<Hwc2::IComposerClient::Composition>( layer->getCompositionType(displayDevice)); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
这个函数很难看懂特别是高版本又加了很多的封装,导致我们根本看不到HWC模块的接口,逻辑隐藏的就更深了,首先需要明白,SetUpHWComposer这个函数的作用就是把需要显示的Layer这类数据准备好,传递给HWC模块,由后者决定是由HWC自己处理还是交给OpenGL ES来合成,然后我们一定要记得HWC模块是有俩,一个是真正操作驱动节点的,surfaceflinger目录下的displayHardware这个HWC是封装,它又去操作hal的HWC模块。
4.4.2.6 doComposition
calculateWorkingSet只是把Layer数据送给了HWC,但还没有开始合成的工作,doComposition就是做这个的,主要关注的就是:
- 如何合成
- 怎么显示到屏幕上
首先由OpenGL ES还是HWC来合成在上个小节已经明确,由compositionType来决定,将UI数据显示到屏幕的关键则是eglSwapBuffers,还记得它是什么吗?字面来理解–交换,就是屏幕数据FrameBuffer的交换,还记得开头说的双缓冲、三缓冲buffer吗、交换的就是它,完成交换,显然就刷新了屏幕!来看doComposition源码
void SurfaceFlinger::doComposition(const sp<DisplayDevice>& displayDevice, bool repaintEverything) { auto display = displayDevice->getCompositionDisplay(); const auto& displayState = display->getState(); if (displayState.isEnabled) { // transform the dirty region into this screen's coordinate space //我们来翻译下,getDirtyRegion作用就是将脏区域转换为屏幕真实坐标点 const Region dirtyRegion = display->getDirtyRegion(repaintEverything); // repaint the framebuffer (if needed) doDisplayComposition(displayDevice, dirtyRegion);//可能会调用eglSwapBUffers display->editState().dirtyRegion.clear(); display->getRenderSurface()->flip(); } postFramebuffer(displayDevice); } void SurfaceFlinger::doDisplayComposition(const sp<DisplayDevice>& displayDevice, const Region& inDirtyRegion) { auto display = displayDevice->getCompositionDisplay(); // We only need to actually compose the display if: // 1) It is being handled by hardware composer, which may need this to // keep its virtual display state machine in sync, or // 2) There is work to be done (the dirty region isn't empty) if (!displayDevice->getId() && inDirtyRegion.isEmpty()) { ALOGV("Skipping display composition"); return; } base::unique_fd readyFence; //Step1、这里是在合成数据 if (!doComposeSurfaces(displayDevice, Region::INVALID_REGION, &readyFence)) return; // swap buffers (presentation) display->getRenderSurface()->queueBuffer(std::move(readyFence)); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
Step1、compose的是什么surface?
bool SurfaceFlinger::doComposeSurfaces(const sp<DisplayDevice>& displayDevice, const Region& debugRegion, base::unique_fd* readyFence) { auto display = displayDevice->getCompositionDisplay(); const auto& displayState = display->getState(); const auto displayId = display->getId(); auto& renderEngine = getRenderEngine(); const Region bounds(displayState.bounds); const DisplayRenderArea renderArea(displayDevice); const bool hasClientComposition = getHwComposer().hasClientComposition(displayId); ATRACE_INT("hasClientComposition", hasClientComposition); bool applyColorMatrix = false; renderengine::DisplaySettings clientCompositionDisplay; std::vector<renderengine::LayerSettings> clientCompositionLayers; sp<GraphicBuffer> buf; base::unique_fd fd; if (hasClientComposition) { ALOGV("hasClientComposition"); bool needsProtectedContext = requiresProtecedContext(displayDevice); if (needsProtectedContext != renderEngine.isProtected()) { renderEngine.useProtectedContext(needsProtectedContext); } if (needsProtectedContext != display->getRenderSurface()->isProtected() && needsProtectedContext == renderEngine.isProtected()) { display->getRenderSurface()->setProtected(needsProtectedContext); } buf = display->getRenderSurface()->dequeueBuffer(&fd); if (buf == nullptr) { ALOGW("Dequeuing buffer for display [%s] failed, bailing out of " "client composition for this frame", displayDevice->getDisplayName().c_str()); return false; } clientCompositionDisplay.physicalDisplay = displayState.scissor; clientCompositionDisplay.clip = displayState.scissor; const ui::Transform& displayTransform = displayState.transform; clientCompositionDisplay.globalTransform = displayTransform.asMatrix4(); clientCompositionDisplay.orientation = displayState.orientation; const auto* profile = display->getDisplayColorProfile(); Dataspace outputDataspace = Dataspace::UNKNOWN; if (profile->hasWideColorGamut()) { outputDataspace = displayState.dataspace; } clientCompositionDisplay.outputDataspace = outputDataspace; clientCompositionDisplay.maxLuminance = profile->getHdrCapabilities().getDesiredMaxLuminance(); const bool hasDeviceComposition = getHwComposer().hasDeviceComposition(displayId); const bool skipClientColorTransform = getHwComposer() .hasDisplayCapability(displayId, HWC2::DisplayCapability::SkipClientColorTransform); // Compute the global color transform matrix. applyColorMatrix = !hasDeviceComposition && !skipClientColorTransform && (displayDevice->isPrimary() || displayDevice->getIsDisplayBuiltInType()); if (applyColorMatrix) { clientCompositionDisplay.colorTransform = displayState.colorTransformMat; } } /* * and then, render the layers targeted at the framebuffer */ ALOGV("Rendering client layers"); bool firstLayer = true; Region clearRegion = Region::INVALID_REGION; std::vector<std::string> layers; for (auto& layer : displayDevice->getVisibleLayersSortedByZ()) { const Region viewportRegion(displayState.viewport); const Region clip(viewportRegion.intersect(layer->visibleRegion)); ALOGV("Layer: %s", layer->getName().string()); ALOGV(" Composition type: %s", toString(layer->getCompositionType(displayDevice)).c_str()); layers.push_back(layer->getName().string()); if (!clip.isEmpty()) { switch (layer->getCompositionType(displayDevice)) { case Hwc2::IComposerClient::Composition::CURSOR: case Hwc2::IComposerClient::Composition::DEVICE: case Hwc2::IComposerClient::Composition::SIDEBAND: case Hwc2::IComposerClient::Composition::SOLID_COLOR: { LOG_ALWAYS_FATAL_IF(!displayId); const Layer::State& state(layer->getDrawingState()); if (layer->getClearClientTarget(displayDevice) && !firstLayer && layer->isOpaque(state) && (layer->getAlpha() == 1.0f) && layer->getRoundedCornerState().radius == 0.0f && hasClientComposition) { // never clear the very first layer since we're // guaranteed the FB is already cleared renderengine::LayerSettings layerSettings; Region dummyRegion; bool prepared = layer->prepareClientLayer(renderArea, clip, dummyRegion, renderEngine.isProtected(), layerSettings); if (prepared) { layerSettings.source.buffer.buffer = nullptr; layerSettings.source.solidColor = half3(0.0, 0.0, 0.0); layerSettings.alpha = half(0.0); layerSettings.disableBlending = true; clientCompositionLayers.push_back(layerSettings); } } break; } case Hwc2::IComposerClient::Composition::CLIENT: { renderengine::LayerSettings layerSettings; if (displayDevice->isVirtual() && skipColorLayer(layer->getTypeId())) { // We are not using h/w composer. // Skip color (dim) layer for WFD direct streaming. continue; } bool prepared = layer->prepareClientLayer(renderArea, clip, clearRegion, renderEngine.isProtected(), layerSettings); if (prepared) { clientCompositionLayers.push_back(layerSettings); } break; } default: break; } } else { ALOGV(" Skipping for empty clip"); } firstLayer = false; } if (mSplitLayerExt && mLayerExt) { mLayerExt->updateLayerState(layers, mNumLayers); } // Perform some cleanup steps if we used client composition. if (hasClientComposition) { clientCompositionDisplay.clearRegion = clearRegion; // We boost GPU frequency here because there will be color spaces conversion // and it's expensive. We boost the GPU frequency so that GPU composition can // finish in time. We must reset GPU frequency afterwards, because high frequency // consumes extra battery. const bool expensiveRenderingExpected = clientCompositionDisplay.outputDataspace == Dataspace::DISPLAY_P3; if (expensiveRenderingExpected && displayId) { mPowerAdvisor.setExpensiveRenderingExpected(*displayId, true); } if (!debugRegion.isEmpty()) { Region::const_iterator it = debugRegion.begin(); Region::const_iterator end = debugRegion.end(); while (it != end) { const Rect& rect = *it++; renderengine::LayerSettings layerSettings; layerSettings.source.buffer.buffer = nullptr; layerSettings.source.solidColor = half3(1.0, 0.0, 1.0); layerSettings.geometry.boundaries = rect.toFloatRect(); layerSettings.alpha = half(1.0); clientCompositionLayers.push_back(layerSettings); } } renderEngine.drawLayers(clientCompositionDisplay, clientCompositionLayers, buf->getNativeBuffer(), /*useFramebufferCache=*/true, std::move(fd), readyFence); } else if (displayId) { mPowerAdvisor.setExpensiveRenderingExpected(*displayId, false); } return true; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
当doComposeSurfaces走完,回到display->getRenderSurface()->queueBuffer的时候,composed工作就完成了,但是现在还没有显示到屏幕,还需要Swap这一步。此时上层应用创建的UI数据Surface,就会显示到屏幕上,整个显示流程就完成,流程实在太长,有些点无法细化,需要各位在追踪源码时真正的思考,尽力理逻辑,显示系统毕竟太繁琐了,能弄懂它,80%的Android framework就学完了。。
-
相关阅读:
[人工智能-综述-15]:第九届全球软件大会(南京)有感 -4-大语言模型全流程、全方面提升软件生产效能
LLM大模型工程师面试经验宝典--基础版(2024.7月最新)
十三、MySql的视图
Redis从入门到放弃(9):集群模式
phalcon 访问IndexController 中只能访问indexAction方法,访问不了testAction等其它问题的解决办法
超市微信小程序是怎么做的
JDBC最详讲解(快速入门)
TensorFlow2:概述
代码学习记录48---单调栈
odoo前端js对象的扩展方法
- 原文地址:https://blog.csdn.net/dream_caoyun/article/details/124998385