论文信息
论文标题:Local Augmentation for Graph Neural Networks
论文作者:Songtao Liu, Hanze Dong, Lanqing Li, Tingyang Xu, Yu Rong, Peilin Zhao, Junzhou Huang, Dinghao Wu
论文来源:2021, arXiv
论文地址:download
论文代码:download
1 Introduction
现有的方法侧重于从全局的角度来增强图形数据,主要分为两种类型:
-
- structural manipulation
- adversarial training with feature noise injection
最近工作忽略了局部信息对GNN 消息传递机制的重要性。在本文种,引入局部数据增强,通过子图结构增强节点表示的局部性。具体来说,将数据增强建模为一个特征生成过程。给定一个节点的特征,本文的局部增强方法学习其邻居特征的条件分布,并生成更多的邻居特征,以提高下游任务的性能。
基于局部增强,进一步设计了一个新的框架:LA-GNN,它可以以即插即用的方式应用于任何GNN模型。
2 Local Augmentation
框架如下:
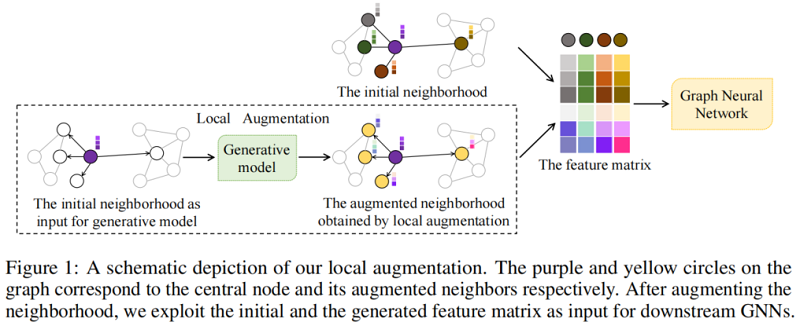
Local augmentation framework 包括三个模块:
-
- learning the conditional distribution via a generative model;
- the active learning trick;
- the downstream GNN models;
需要注意的是,该算法生成的是 1-hop 邻居来增强节点的局部性。
2.1 Learning The Conditional Distribution
利用 GNN 来建模标签的条件概率分布 Pθ(Y∣A,X)
max∏k∈KPθ(Yk∣A,X)(2)
为提升 GNN 性能,引入由特征级数据增强生成的特征 ¯X
基于贝叶斯公式,将 Eq.3 分解成由GNN近似的概率分布 Pθ(Yk∣A,X,¯X) 和特征增强生成器 Qϕ(¯X∣A,X) 共同控制的两个部分:
Pθ,ϕ(Yk,¯X∣A,X):=Pθ(Yk∣A,X,¯X)Qϕ(¯X∣A,X)(4)
上述分解的两个好处:
-
- 首先,允许解耦下游预测器 Pθ 和生成器 Qϕ 的训练,使生成器能够很容易地推广到其他下游任务。
- 此外,Eq.4 的表示能力优于没有数据增强的 Pθ(Yk∣A,X)。
因此,当生成器 Qϕ 被训练得很好,便可从固定的条件分布 Qϕ 中提取样本 ¯X 来优化 Pθ(Yk∣A,X,¯X)。
接下来,将展示如何训练生成器。
Generator
为学习特征增强生成器,本文使用 MLE 方法学习所有邻居的一个单一分布,即:
maxψ∑j∈Nilogpψ(Xj∣Xi)=maxψlog∏j∈Nipψ(Xj∣Xi)(5)
其中 {Xj∣j∈Ni,Xi}。
显然,pψ 可用于增强所有邻居的特征,但是这种方法忽略了邻居之间的差异,会引起严重的噪声。
为克服这一限制,假设每个邻居都满足不同的条件分布。具体地说,存在一个具有潜在随机变量 zj 的条件分布 p(⋅∣Xi,zj),这样可得对于 Xj∣j∈Ni 的 Xj∼p(X∣Xi,zj)。当获得 p(⋅∣Xi,zj),便可以生成增强特征 ¯X,然后便可训练 Pθ(Yk∣A,X,¯X),来提高 Pθ 的最终性能。
下面,将介绍如何找到 p(⋅∣Xi,zj),从而产生生成器 Qϕ。
一个合适的方法是条件变分自编码器(CVAE)[20,45],它可以帮助学习潜在变量 zj 的分布,和条件分布 p(⋅∣Xi,zj)。因此,本文采用 CVAE 模型 Qϕ(¯X∣A,X) 作为本文的生成器,其中 ϕ={φ,ψ},φ 表示其中的变分参数, ψ 表示生成器参数。[32,45] 为推导出 CVAE 的优化问题,用潜变量 z 写出 logpψ(Xj∣Xi):
logpψ(Xj∣Xi)=∫qφ(z∣Xj,Xi)logpψ(Xj,z∣Xi)qφ(z∣Xj,Xi)dz+KL(qφ(z∣Xj,Xi)‖pψ(z∣Xj,Xi))≥∫qφ(z∣Xj,Xi)logpψ(Xj,z∣Xi)qφ(z∣Xj,Xi)dz
Evidence lower bound (ELBO) 可以写成:
L(Xj,Xi;ψ,φ)=−KL(qφ(z∣Xj,Xi)‖pψ(z∣Xi))+∫qφ(z∣Xj,Xi)logpψ(Xj∣Xi,z)dz(6)
其中:
编码器 qφ(z∣Xj,Xi)=N(f(Xj,Xi),g(Xj,Xi))
解码器 pψ(Xj∣Xi,z)=N(h(Xi,z),cI)。
编码器是一个两层的MLP,f 和 g 共享第一层,第二层采用不同的参数。解码器 h 是两层的MLP。为了易于处理,生成器 Q(¯X∣A,X) 在所有节点上 vi∈V 使用同样的参数。
Optimization of the MLE
首先,参数 ϕ={ψ,φ} 可以通过最大化生成器的 ELBO (Eq.6) 来进行优化,即对生成器进行训练。
其次,通过最大化 Eq.4,在固定 ϕ 的条件下对参数 θ 进行优化,即给定 Yk 关于 A、X、¯X 的条件分布,训练下游的GNN模型:
Pθ(Yk∣A,X,¯X)∝−¯L(θ∣A,X,¯X,ϕ)(7)
其中:
¯L(θ∣A,X,¯X,ϕ)=−∑k∈T∑Cf=1Ykfln(softmax(GNN(A,X,¯X))kf)
2.2 The Architecture of LA-GNN
本节使用 GCN、GAT、GCNII 和 GRAND 作为骨干,并在半监督节点分类任务上进行测试。将修改后的 GNN 架构命名为 LA-GNN,其中 LA 的意思是局部增强。
LA-GCNA
2 层 LA-GCN 的定义如下:
H(2)=σ(ˆA(σ(ˆAXW(1)1)‖σ(ˆA¯X1W(1)2)‖⋯‖σ(ˆA¯XnW(1)n+1))W(2))(8)
GCNII[6] 在 X 上应用全连接神经网络,在前向传播前获得低维初始表示 H(0),因此本文在 X 和 ¯X 上应用全连接神经网络,获得 H(0),如下:
H(0)=σ(XW(0)1)‖σ(¯X1W(0)2)‖⋯‖σ(¯XnW(0)n+1)(9)
H(0) 被送入下一个正向传播层。
此外,我们不需要修改GAT和GRAND 的体系结构,只需要将生成的特征矩阵添加到输入中。
2.3 Active Learning
在本节中,我们将介绍整个训练框架的一个技巧。在生成器的训练完成后,它包含了一个使用 Qϕ(¯X∣A,X) (Eq.4) 用于推断的问题,因为 Q 可能从分布的侧面生成一些样本。这个关键的问题使推论效率低下。受[30]的启发,我们引入了主动学习来捕获合适的生成的特征矩阵和相应的生成器,这提高了推理效率,并有助于MLE的优化。在主动学习过程中,每个特征的概率与获取函数评估的不确定性成正比。我们采用 Bayesian Active Learning by Disagreement (BALD) acquisition function[17],对 Monte Carlo (MC) dropout samples 中最重要的推断进行采样:
U(¯X)≈H[1N∑Nn=1P(Yk∣¯X,ωn)]−1N∑Nn=1H[P(Yk∣¯X,ωn)](10)
其中,N 为MC样本数,ωn 为第 N 个 MC dropout sample 的网络采样参数。较高的BLAD得分表示网络对所生成的特征矩阵具有较高的不确定性。因此,人们倾向于选择它来改进 GNN 模型。最后,在 Algorithm 1 中总结了整个算法框架,显示了 Eq.4 的优化.

3 Discussion
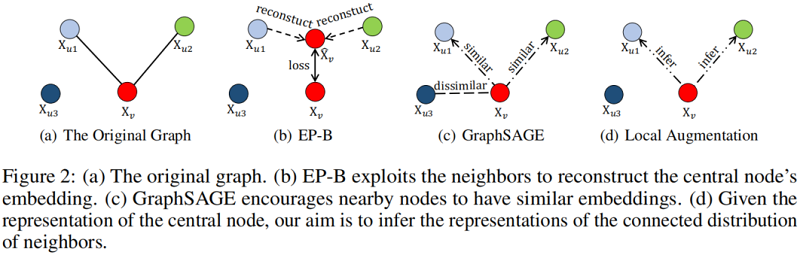
Connection to EP-B and GraphSAGE
讨论本文提出的模型如何区别于经典的图上的表示学习模型。以往的方法如 EP-B[13] 和 GraphSAGE[16] 依赖于中心节点与其邻居嵌入之间的重构损失函数。
EP-B 的目的是通过优化目标来最小化重建误差:
min∑u∈V∖{v}[γ+d(Xv,Xv)−d(˜Xv,Xu)]
其中,Xv 表示目标节点,Xu 表示邻居节点;˜Xv=AGG(Xl∣l∈N(v)) 表示来自邻居的重建;γ 指的是偏置。
GraphSAGE利用负采样来区分远程节点对的表示,强制附近的节点具有相似的表示形式,并通过最小化以下目标函数,强制不同的节点变得不同。
−Eu∼N(v)log((σ(XTuXv)))−λEvn∼Pn(v)log((σ(−XTvnXv)))
其中,Xv 表示目标节点,Xu 表示的是远离的节点,Pn(v) 是负采样。
这些方法建立在相邻节点共享相似属性的假设之上。相比之下,本文的模型并不依赖于这种假设,而是从中心节点表示的条件分布中生成相邻节点的特征。给定目标节点 Xv,本文的目标是学习邻居节点 Xu 的条件分布。Figure 2 说明了基于重建的图表示学习与我们提出的框架之间的比较。而我们的局部增强方法是以生成的方式利用邻居的第三种范式。
4 Experiments
在本节中,我们将评估我们所提出的模型在各种公共图数据集上的半监督节点分类任务上的性能,并将我们的模型与最先进的图神经网络进行比较。我们还进行了额外的实验,以展示我们的设计的必要性和它对缺失信息的鲁棒性。
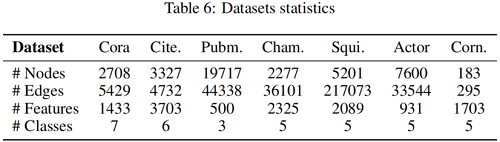
数据集
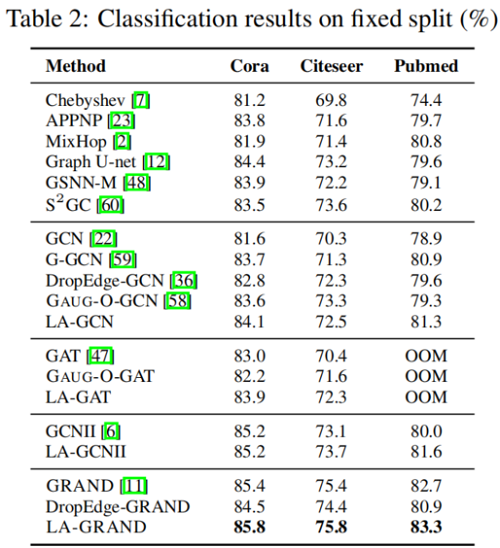
半监督节点分类
我们在三个数据集Cora、Citeseer和Pubmed上应用标准的固定分割[55],每个类有20个节点用于训练,500个节点用于验证,1000个节点用于测试。
对于 Squirrel, Actor, Chameleon 和 Cornell 数据集,我们取10个随机分割[41],其中 10%、30% 和 60% 进行训练、验证、测试;测量GCN、GAT、GCNII和相应的修改模型的性能。

属性分布
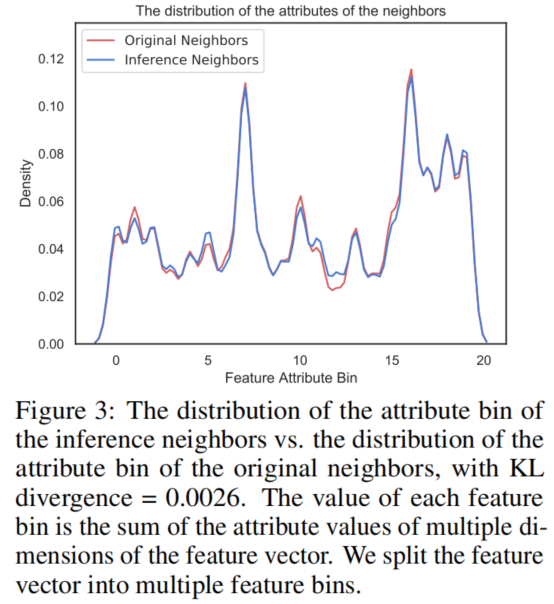
我们还提供了我们生成的特征矩阵分布的分析。Figure 3 显示了原始邻居和推理邻居的属性分布,这可以证明我们的推理特征矩阵遵循初始特征矩阵的分布。
消融研究
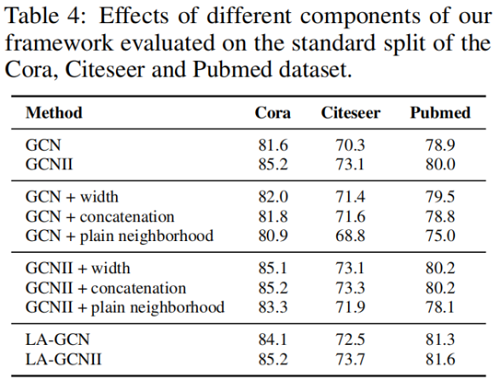
在本节中,为了证明我们提出的生成框架的有效性,我们进行了实验,将LA-GNN与其几个没有生成建模的消融变体进行了比较。结果如表4所示。“GCN+width”只增加了GCN和GCNII的第一个网络层宽度来匹配LAGNN,而不提供生成的样本作为输入。“+连接“只将生成的LA-GNN的特征矩阵替换为中心节点的原始特征矩阵”。““+平原邻域”将生成的特征矩阵替换为邻域特征矩阵,其中每一行对应于随机采样邻域的特征向量。结果表明,前两个变体对主干模型没有明显的改进,第三种变体甚至导致退化。通过消除这些与我们的核心方法无关的混杂因素可能有助于最终性能的可能性,很明显,表2和表3中的性能增益是由于我们提出的生成式局部增强框架。
5 Conclusion
References
__EOF__
