-
欠拟合、过拟合现象,及解决办法
@创建于:2022.05.27
@修改于:2022.05.271、过拟合与欠拟合
机器学习中模型的泛化能力强的模型才是好模型。对于训练好的模型:
- 若在训练集表现差,不必说在测试集表现同样会很差,这可能是欠拟合导致;
- 若模型在训练集表现非常好,却在测试集上差强人意,则这便是过拟合导致的。
过拟合与欠拟合也可以用 Bias 与 Variance 的角度来解释:
- 欠拟合会导致高 Bias
- 过拟合会导致高 Variance
所以模型需要在 Bias 与 Variance 之间做出一个权衡。
现象 训练集表现 验证集表现 导致后果 欠拟合 不好 不好 高 Bias 过拟合 好 不好 高 Variance 适度拟合 好 好 Bias 和 Variance 的折中 
2、欠拟合
2.1 出现的原因
使用的模型复杂度过低
使用的特征量过少
【其他的,如果您知道,请告诉我!感谢】2.2 解决的办法
1、对于机器学习
- 增加新特征,可以考虑加入进特征组合、高次特征,来增大假设空间
- 添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强
- 减少正则化参数,正则化的目的是用来防止过拟合的,但是模型出现了欠拟合,则需要减少正则化参数
- 使用非线性模型,比如核SVM 、决策树、深度学习等模型
- 调整模型的容量(capacity),通俗地,模型的容量是指其拟合各种函数的能力。对于神经网络,这在很大程度上取决于它有多少神经元以及它们如何连接在一起。
- 容量低的模型可能很难拟合训练集;使用集成学习方法,如Bagging ,将多个弱学习器Bagging
2、对于深度学习
欠拟合的原因以及解决办法(深度学习)- 对原始数据做归一化处理,这个会加速模型的收敛
- 减少使用正则化,减少的dropout
- 增加单层的神经元个数,加深网络层次
- 正确使用激活函数
3、过拟合
3.1 出现的原因
1、对于机器学习
-
建模样本选取有误,如样本数量太少,选样方法错误,样本标签错误等,导致选取的样本数据不足以代表预定的分类规则
-
样本噪音干扰过大,使得机器将部分噪音认为是特征从而扰乱了预设的分类规则
-
假设的模型无法合理存在,或者说是假设成立的条件实际并不成立
参数太多,模型复杂度过高 -
对于决策树模型,如果我们对于其生长没有合理的限制,其自由生长有可能使节点只包含单纯的事件数据(event)或非事件数据(no event),使其虽然可以完美匹配(拟合)训练数据,但是无法适应其他数据集
2、对于神经网络模型
- a)对样本数据可能存在分类决策面不唯一,随着学习的进行,BP算法使权值可能收敛过于复杂的决策面;
- b)权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征
3.2 解决的办法
- 正则化(Regularization)(L1和L2)
- 数据扩增,即增加训练数据样本(Data augmentation)
- Dropout
- Early stopping
- 降低模型复杂度
- 使用交叉验证
4. Early stopping
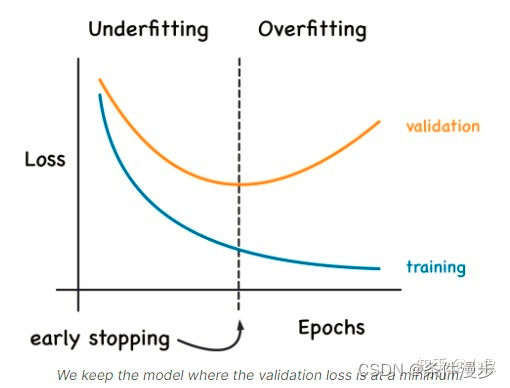
在训练期间验证损失(validation loss)可能会开始增加,为了防止这种情况,在验证损失(validation loss)不再减少时停止训练。以这种方式中断训练称为early stopping。一旦检测到验证损失开始再次上升,可以将权重重置为最小值出现的位置。这可确保模型不会继续学习噪声和过度拟合数据。
提前停止训练也意味着不太可能在网络完成学习信号之前过早停止训练。所以除了防止过拟合训练时间过长之外,提前停止还可以防止欠拟合训练时间不够长。只需将您的训练时期设置为一个较大的数字(比您需要的多),早期停止将处理其余部分。
5、Dropout
深度学习入门五----Dropout and Batch Normalization
过拟合的原因以及解决办法(深度学习)
在训练的每一步随机丢弃层输入单元的一部分,使网络更难学习训练数据中的那些虚假模式。相反,它必须搜索广泛的、通用的模式,其权重模式往往更加稳健。
6、L1 和 L2 正则化
L1正则化就是在loss function后边所加正则项为L1范数,加上L1范数容易得到稀疏解(0比较多)。L2正则化就是loss function后边所加正则项为L2范数的平方,加上L2正则相比于L1正则来说,得到的解比较平滑(不是稀疏),但是同样能够保证解中接近于0(但不是等于0,所以相对平滑)的维度比较多,降低模型的复杂度。

7、参考资料
机器学习防止欠拟合、过拟合方法
欠拟合和过拟合出现原因及解决方案深度学习入门四----过拟合与欠拟合
深度学习入门五----Dropout and Batch Normalization -
相关阅读:
Vue学习:计算属性
我的sql没问题为什么还是这么慢|MySQL加锁规则
MySQL数据库教程
SpringBoot_05_自动配置管理
Nodejs -- Express的安装和定义get、post方法
【AI视野·今日Robot 机器人论文速览 第五十四期】Fri, 13 Oct 2023
微信小程序——生命周期
HTML(15)——盒子模型
你 offo 来了!阿里限产教科书级 Elasticsearch 核心手册
统计遗传学:第一章,基因组基础概念
- 原文地址:https://blog.csdn.net/chenhepg/article/details/125008004