-
手把手教你解决循环依赖,一步一步地来窥探出三级缓存的奥秘
先不去管Spring中的循环依赖,我们先实现一个自定义注解,来模拟@Autowired的功能。
一、自定义注解模拟@Autowired
自定义Load注解,被该注解标识的字段,将会进行自动注入
- /**
- * @author qcy
- * @create 2021/10/02 13:31:20
- */
- //只用在字段上
- @Target(ElementType.FIELD)
- //运行时有效,这样可以通过反射解析注解
- @Retention(RetentionPolicy.RUNTIME)
- public @interface Load {
- }
新建A类与B类,其中A类中需要注入B
- public class A {
- @Load
- private B b;
- public B getB() {
- return b;
- }
- }
- public class B {
- }
测试类
- public class Main {
- private static <T> T getBean(Class<T> clazz) throws IllegalAccessException, InstantiationException {
- //实例化对象
- T instance = clazz.newInstance();
- //获取当前类中的所有字段
- Field[] fields = clazz.getDeclaredFields();
- for (Field field : fields) {
- //允许访问私有变量
- field.setAccessible(true);
- //判断字段是否被@Load注解修饰
- boolean isUseLoad = field.isAnnotationPresent(Load.class);
- if (!isUseLoad) {
- continue;
- }
- //获取需要被注入的字段的class
- Class<?> fieldType = field.getType();
- //递归获取字段的实例对象
- Object fieldBean = getBean(fieldType);
- //将实例对象注入到该字段中
- field.set(instance, fieldBean);
- }
- return instance;
- }
- public static void main(String[] args) throws InstantiationException, IllegalAccessException {
- A a = getBean(A.class);
- System.out.println(a.getB().getClass());
- }
最终能够打印出a对象中依赖的b的class类型

二、多例模式下的循环依赖
现在思考一个问题,如果b对象同时依赖a呢?也就是B类中需要注入A
现在直接把B类的代码改成以下的样子
- public class B {
- @Load
- private A a;
- public A getA() {
- return a;
- }
- }
直接运行测试类,会发生什么呢?
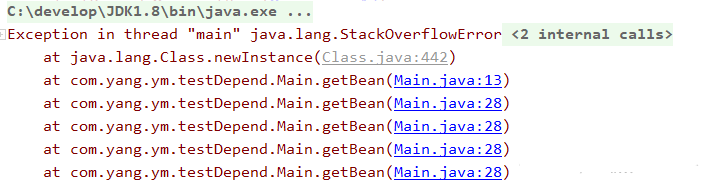
出现了栈溢出!到底是哪里出问题了呢?

原来是,在实例化A后,属性注入阶段发现需要注入B的实例,于是去实例化B,B又需要依赖A,因此去实例化A,一直依赖下去...

不难观察出,getBean每调用一次,都会返回一个新的对象,也就是对应于多例模式。
多例模式中出现循环依赖,直接报出了StackOverflowError,看来解决不了循环依赖,这也并不难理解
三、单例模式下使用缓存来解决循环依赖
如果这个时候,对于传入的同一个class,能够返回同一个实例,即单例模式,能否解决循环依赖呢?
大致的思路是,使用一个缓存map,将实例化好且属性注入完毕的对象缓存到该map中,下次直接使用即可。
可现在又遇到难题了,压根就创建不出来一个完整的A的实例对象啊,无法进行缓存。
既然无法直接将完成品放入到缓存中,那是否可以将实例对象分为两个阶段
半成品阶段
仅完成实例化,并没有完成属性注入
成品阶段
半成品完成属性注入
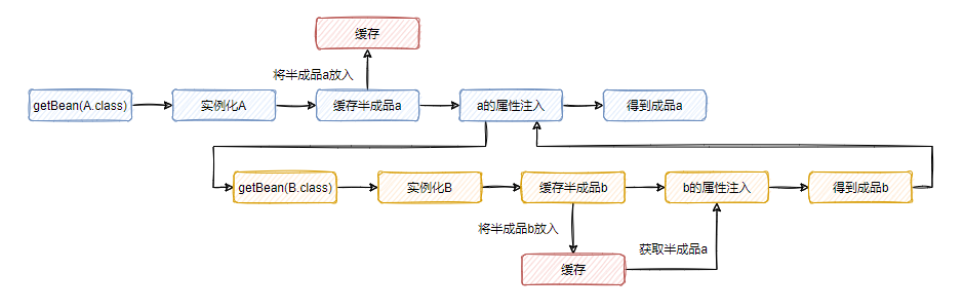
首先实例化A得到半成品a,接着将这个a放入到缓存中。然后实例化b时,注入缓存中半成品的a,得到成品b。最终再将成品b注入到半成品a中,此时a变为成品。
这个时候,a完成了实例化与属性注入,b也完成了实例化与属性注入,循环依赖好像就能解决了。

改下代码,直接上线!
- public class Main {
- //由类名可以获取到对应的实例对象
- private static Map<String, Object> singletonObjects= new HashMap<>();
- private static <T> T getBean(Class<T> clazz) throws IllegalAccessException, InstantiationException {
- //先从缓存中获取
- String className = clazz.getSimpleName();
- if (singletonObjects.containsKey(className)) {
- return (T) singletonObjects.get(className);
- }
- //实例化对象
- T instance = clazz.newInstance();
- //实例化完成后,就将这个半成品放入到缓存中
- singletonObjects.put(className, instance);
- //获取当前类中的所有字段
- Field[] fields = clazz.getDeclaredFields();
- for (Field field : fields) {
- //允许访问私有变量
- field.setAccessible(true);
- //判断字段是否被@Load注解修饰
- boolean isUseLoad = field.isAnnotationPresent(Load.class);
- if (!isUseLoad) {
- continue;
- }
- //获取需要被注入的字段的class
- Class<?> fieldType = field.getType();
- //递归获取字段的实例对象
- Object fieldBean = getBean(fieldType);
- //将实例对象注入到该字段中
- field.set(instance, fieldBean);
- }
- return instance;
- }
- public static void main(String[] args) throws InstantiationException, IllegalAccessException {
- A a1 = getBean(A.class);
- A a2 = getBean(A.class);
- System.out.println(a1 == a2);
- System.out.println(a1.getB() == a1.getB());
- B b = getBean(B.class);
- System.out.println(a1.getB() == b);
- }
- }
运行后,将返回三个true,说明单例模式下的循环依赖是可以解决的。
大致的图是这样的
事情似乎到这里应该结束了,好的观众朋友们,咱们下期见。

四、多线程下隐藏的问题
以上的代码,在单线程的环境下,是没有问题的。可是放到多线程的环境中,可能就会出现空指针问题。
线程1刚把半成品a放入到缓存中,还未来得及将b注入进去。此时线程2直接在缓存中获取到了a,在尝试调用其所依赖的b的任何方法时,就会出现空指针异常。
因此上述代码,存在线程不安全的问题,怎么去解决呢?
很简单,我直接对getBean方法加锁不就可以了吗?

对整个方法加锁确实可以解决问题,但运行性能会大打折扣。
第一次的创建与读缓存互斥,创建完成后的读与读不需要加锁。
其实问题的本质在于,singletonObjects缓存既存放半成品类型,又存放成品类型,导致线程根本不清楚拿到的实例的类型。
那能不能再创建一个缓存earlySingletonObjects,即早期单例对象,就存放半成品类型,先前的singletonObjects存放成品类型。
直接上代码
- //成品缓存
- private static final Map<String, Object> singletonObjects = new ConcurrentHashMap<>();
- //半成品缓存
- private static final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>();
- //从缓存中获取
- private static Object getSingleton(String className) {
- //先从成品缓存中查找
- Object singletonObject = singletonObjects.get(className);
- if (singletonObject == null) {
- //再从半成品缓存中查找
- singletonObject = earlySingletonObjects.get(className);
- }
- return singletonObject;
- }
- @SuppressWarnings("unchecked")
- private static <T> T getBean(Class<T> clazz) throws IllegalAccessException, InstantiationException {
- //先从缓存中获取
- String className = clazz.getSimpleName();
- Object singleton = getSingleton(className);
- if (singleton != null) {
- return (T) singleton;
- }
- synchronized (singletonObjects) {
- singleton = singletonObjects.get(className);
- //这里需要再进行一次检查
- if (singleton != null) {
- return (T) singleton;
- }
- //实例化对象
- T instance = clazz.newInstance();
- //实例化完成后,就将这个半成品放入到缓存中
- earlySingletonObjects.put(className, instance);
- //获取当前类中的所有字段
- Field[] fields = clazz.getDeclaredFields();
- for (Field field : fields) {
- //允许访问私有变量
- field.setAccessible(true);
- //判断字段是否被@Load注解修饰
- boolean isUseLoad = field.isAnnotationPresent(Load.class);
- if (!isUseLoad) {
- continue;
- }
- //获取需要被注入的字段的class
- Class<?> fieldType = field.getType();
- //递归获取字段的实例对象
- Object fieldBean = getBean(fieldType);
- //将实例对象注入到该字段中
- field.set(instance, fieldBean);
- }
- //完成属性注入后,从半成品缓存中移除,加入到成品缓存中
- earlySingletonObjects.remove(className);
- singletonObjects.put(className, instance);
- return instance;
- }
- }
- public static void main(String[] args) {
- new Thread(() -> {
- try {
- A a1 = getBean(A.class);
- System.out.println("t1.a:" + a1.hashCode());
- System.out.println("t1.b:" + a1.getB().hashCode());
- } catch (IllegalAccessException | InstantiationException e) {
- e.printStackTrace();
- }
- }).start();
- new Thread(() -> {
- try {
- A a1 = getBean(A.class);
- System.out.println("t2.a:" + a1.hashCode());
- System.out.println("t2.b:" + a1.getB().hashCode());
- } catch (IllegalAccessException | InstantiationException e) {
- e.printStackTrace();
- }
- }).start();
- new Thread(() -> {
- try {
- B b = getBean(B.class);
- System.out.println("t3.b:" + b.hashCode());
- System.out.println("t3.a:" + b.getA().hashCode());
- } catch (IllegalAccessException | InstantiationException e) {
- e.printStackTrace();
- }
- }).start();
- }
输出结果:

多次实验,从输出结果说明:在多线程的场景下,使用两级缓存能够有效避免出现空指针的问题,在一定程度上也能比整个方法加锁的效率更高。
五、什么样的循环依赖都能解决吗?
从第二节可以看出,多例模式下就不可以解决循环依赖。
我们在以上小节中写的代码,是默认全部使用反射set注入的。
而对于单例模式,在经过对依赖项自然排序后,构造器注入是不可以优先于任何一个set注入的。

第一种场景:b依赖a,需要使用构造器注入a;a依赖b,需要使用set注入b
经过Spring对Bean的自然排序后,会先去创建a,再去创建b。

这种场景,是可以解决循环依赖的。在实例化B时,已经存在半成品a。
结论:最后再使用构造器注入时,可以解决循环依赖。
第二种场景:a依赖b,需要使用构造器注入b;b依赖a,需要使用set注入a

这种场景,在实例化a时,就需要调用构造方法,因此去实例b,而b在缓存中找不到a,造成注入失败。
结论:一开始就使用构造器注入,则不能解决循环依赖。
那么都使用构造器注入时,那肯定也不能解决循环依赖的。
因此,Spring解决循环依赖有两个小前提:
- 循环依赖中的Bean都是单例
- 在经过自然排序后,构造器注入不能优先于循环依赖中的任何一个set注入
六、Spring中解决循环依赖的原理
在Spring中,我们使用getBean方法从容器获取一个Bean,那么就从getBean方法入手
AbstractApplicationContext类中的getBean- public Object getBean(String name) throws BeansException {
- assertBeanFactoryActive();
- return getBeanFactory().getBean(name);
- }
接着进入AbstractBeanFactory类中的getBean
- public Object getBean(String name) throws BeansException {
- return doGetBean(name, null, null, false);
- }
再进入到doGetBean方法中,该方法比较长,截取其中比较核心的点来说
先说getSingleton方法
- //从缓存中获取指定的bean
- Object sharedInstance = getSingleton(beanName);
进入到
DefaultSingletonBeanRegistry的getSingleton方法中- public Object getSingleton(String beanName) {
- return getSingleton(beanName, true);
- }
- protected Object getSingleton(String beanName, boolean allowEarlyReference) {
- //先从一级缓存中查找
- Object singletonObject = this.singletonObjects.get(beanName);
- //如果一级缓存中没有,且当前bean正处于创建的过程中
- if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
- synchronized (this.singletonObjects) {
- //从二级缓存中查找
- singletonObject = this.earlySingletonObjects.get(beanName);
- //如果二级缓存中也没有,且允许暴露早期引用时
- if (singletonObject == null && allowEarlyReference) {
- //从三级缓存中查找到bean的工厂
- ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
- if (singletonFactory != null) {
- //调用getObject方法生成bean
- singletonObject = singletonFactory.getObject();
- //放入到二级缓存中
- this.earlySingletonObjects.put(beanName, singletonObject);
- //从三级缓存中移除
- this.singletonFactories.remove(beanName);
- }
- }
- }
- }
- return singletonObject;
- }
看到这里,似乎和之前我们写的代码很像啊。
Spring在解决循环依赖时,其实也用到了缓存,缓存声明及定义如下:
- private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
- private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
- private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
singletonObjects,一级缓存,存放的是最终的成品,即完成实例化(仅调用构造方法)、属性注入、初始化后的bean
earlySingletonObjects,二级缓存,存放的是半成品,或叫早期曝光对象,即只完成实例化,未完成属性注入及初始化的bean
singletonFactories,三级缓存,存放的是能获取到半成品的工厂
前几节我们自己解决了循环依赖,一级缓存的存在是为了在单线程的情况下解决循环依赖,而二级缓存的存在是为了兼容多线程,提升获取bean的效率。那三级缓存存在的意义又是什么呢?

解决循环依赖,其中的一个核心前提是bean必须是单例的,因此我们接着看doGetBean方法中第二处核心的代码,即处理单例bean的代码
- /处理单例bean
- if (mbd.isSingleton()) {
- //sharedInstance就是从缓存中获取的bean,一般来说,这里是null的
- sharedInstance = getSingleton(beanName, () -> {
- try {
- return createBean(beanName, mbd, args);
- } catch (BeansException ex) {
- destroySingleton(beanName);
- throw ex;
- }
- });
- bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
- }
其中getSingleton方法中的第二个参数是一个函数式接口类型的ObjectFactory,因此这里可以直接使用lambda表达式来传入一个默认的实现,即createBean方法。
进入到getSingleton(beanName,objectFactory)方法中,精简后的代码如下:
- public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
- //如果不在缓存中,就会利用getObject方法去创建
- synchronized (this.singletonObjects) {
- Object singletonObject = this.singletonObjects.get(beanName);
- if (singletonObject == null) {
- //标志当前bean正在创建中,如果被多次创建,这里也会抛出异常
- beforeSingletonCreation(beanName);
- boolean newSingleton = false;
- //执行getObject,即执行外部传入的createBean方法
- singletonObject = singletonFactory.getObject();
- newSingleton = true;
- //省略异常处理,出现异常时,newSingleton=false
- //取消bean正在创建的标志
- afterSingletonCreation(beanName);
- if (newSingleton) {
- //管理缓存,移除三级缓存与二级缓存,加入到一级缓存中
- addSingleton(beanName, singletonObject);
- }
- }
- return singletonObject;
- }
- }
当走到getObject方法时,就会进入到
AbstractAutowireCapableBeanFactorycreateBean方法中核心的方法是这一句话Object beanInstance = doCreateBean(beanName, mbdToUse, args);接着进入到同类中的doCreateBean方法中,精简之后的代码:
- protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
- throws BeanCreationException {
- // 实例化bean
- BeanWrapper instanceWrapper = createBeanInstance(beanName, mbd, args);
- boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
- isSingletonCurrentlyInCreation(beanName));
- if (earlySingletonExposure) {
- //加入到三级缓存中,getEarlyBeanReference会返回单例工厂
- addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
- }
- Object exposedObject = bean;
- //属性注入
- populateBean(beanName, mbd, instanceWrapper);
- //初始化
- exposedObject = initializeBean(beanName, exposedObject, mbd);
- if (earlySingletonExposure) {
- //从二级缓存中查找
- Object earlySingletonReference = getSingleton(beanName, false);
- if (earlySingletonReference != null) {
- //返回二级缓存中的bean,这里就有可能是代理后的对象
- exposedObject = earlySingletonReference;
- }
- }
- return exposedObject;
- }
看看getEarlyBeanReference到底返回了什么样的一个单例工厂(但其实说是工厂,不如说是获取早期曝光对象的一个逻辑)
- protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
- Object exposedObject = bean;
- //从容器中寻找实现InstantiationAwareBeanPostProcessor接口的后置处理器
- if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
- //遍历找到的所有符合要求的后置处理器
- for (BeanPostProcessor bp : getBeanPostProcessors()) {
- //如果后置处理器实现了SmartInstantiationAwareBeanPostProcessor接口
- if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
- SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
- //调用SmartInstantiationAwareBeanPostProcessor的getEarlyBeanReference方法
- exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
- }
- }
- }
- return exposedObject;
- }
在getEarlyBeanReference方法中,最终会返回一个经过AOP拦截后生成的代理对象。
如果当前没有任何实现
InstantiationAwareBeanPostProcessor接口的后置处理器,即当前bean没有被任何AOP拦截后,那直接返回传进来的bean。到这里,源码已经分析得差不多了。以A与B的循环依赖,画一下整个过程
以A没被代理为例:

A被代理为例:

从上面的分析可以看出,解决循环依赖的本质是借助于缓存。
多例下的循环依赖,每次注入的都是一个新的对象,完全用不到缓存,所以无法解决多例下的循环依赖。
在经过自然排序后,如果一开始就是构造器注入,也无法利用到缓存。set注入之所以能利用到缓存,是因为能够将实例化与属性赋值分离,给缓存利用留下余地。
对三级缓存的理解
在单线程的情况,也就是getBean仅支持串行操作的话,那么一级缓存其实已经够用了。
二级缓存将半成品与成品对象分离,使得多线程的情况下,不会拿到不完整的对象实例。而且支持多线程同时查询缓存,在一定程度上提升了性能。
三级缓存存放的是单例对象工厂,准确的说,是函数式接口实现,是生成对象的一段逻辑。如果该对象被代理,则工厂的getObject返回代理之后的对象,否则返回原对象。
这里可能有人有疑问,为什么需要三级缓存呢?在实例化阶段之后,直接将原对象或代理对象放入二级缓存不也行吗?
理论是可以的。
一般来说,在Bean的生命周期中,创建代理是在初始化完成后再做的。
而如果代理出现在循环依赖中,不能等到初始化完成后再做,否则B中注入的A就是原对象,不是代理对象。因此,需要在B的属性注入的前一刻完成对A的代理,而这个阶段,也必然是发生在A的初始化之前。
这个时候,大可以在A实例化之后,如果存在特定的后置处理器,也就是说存在代理,那么直接将A的代理对象放入二级缓存中,不管以后会不会出现循环依赖。事实上,在这个时期,也无法去检测到底之后会不会产生循环依赖,总不能去预知未来吧。如果出现循环依赖,则从二级缓存中获取A的代理对象,注入到B中,这个时候是可以的。如果不发生循环依赖,这个A的代理对象就是无用的,做的是无用功。
这个时候,再加上一层缓存呢?在A实例化之后,只往三级缓存中存放一个生成对象的逻辑。到底是生成代理对象还是原对象,由发生循环依赖时再做决定。当发生循环依赖时,例如当B中需要注入A时,会调用三级缓存中的工厂逻辑,生成A的代理对象,注入进B中。当没发生循环依赖时,A的代理对象还是在初始化完成之后再做,和Bean的生命周期中的处理一致。
所以,三级缓存的存在,是由于对代理的考虑。一方面能避免直接在二级缓存中存放代理对象而之后没发生循环依赖所做的无用功,另一方面也能够最大化的统一Bean的生命周期,可谓两全其美,一箭双雕。
-
相关阅读:
JAVAEE之多线程进阶(2)_ CAS概念、实现原理、ABA问题及解决方案
年底了,接个大活儿,做一个回顾公司五年发展的总结ppt,要求做成H5网页
算法---滑动窗口练习-5(将x减到0的最小操作数)
解决Win10电脑无线网卡的移动热点无法开启问题
Hbase集群搭建
python连接MySQL数据库服务器、使用SQL查询数据表中的所有数据
C和指针 第15章 输入/输出函数 15.7 关闭流
百度百科小程序源码 基于uniapp开发的zblog多端小程序开源源码
庆国庆,拟物地图
Python 基于 OpenCV 视觉图像处理实战 之 OpenCV 简单人脸检测/识别实战案例 之六 简单进行人脸训练与识别
- 原文地址:https://blog.csdn.net/JavaMonsterr/article/details/124986521