-
MySQL高级_索引的数据结构
索引的引入

索引及其优缺点
MySQL官方定义:帮助MySQL高效获取数据的数据结构
优点:
- 提高数据检索效率,降低数据库的IO成本,创建索引主要原因
- 创建唯一索引,保证数据库表中每一行数据的唯一性
- 在实现数据的参考晚完整性方面,加速表和表之间的连接
- 显著减少查询中分组和排序的时间,降低CPU消耗
缺点:
- 创建索引和维护索引要耗费时间
- 索引需要占磁盘空间。除了数据表占数据空间之外,每一个索引还有占一定的物理空间,存储在磁盘上
- 降低更新表的速度,当对表中的数据进行增加、删除、修改时,索引也要动态维护
InnoDB中索引推演
设计索引
新建一个表:
mysql> CREATE TABLE index_demo( -> c1 INT, -> c2 INT, -> c3 CHAR(1), -> PRIMARY KEY(c1) -> ) ROW_FORMAT = Compact;- 1
- 2
- 3
- 4
- 5
- 6

- record_type:记录类型,0普通记录、1目录页、2最小记录、3最大记录
- next_record:下一条地址相对于本条记录的地址偏移量
- 各个列的值:只记录在index_demo表中的列
- 其他信息:除了上述三种信息以外的所有信息,包括其他隐藏列的值以及记录的额外信息
简单的索引设计方案
建立目录:快速定位记录所在的页
-
下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值
-
给所有的页建立一个目录项

将几个目录项在物理存储器上连续存储(比如:数组),就可以实现根据主键值快速查找某条记录的功能了
比如查找主键值为20的记录,查找过程分两步:
- 1、先从目录项中根据二分法快速确定主键值为20的记录在目录项3中(因为12<20<209),对应页9
- 2、再从页9中去定位具体的记录
至此,针对数据页的简易目录就搞定了,这个目录的别名就称为索引
InnoDB中的索引方案
迭代一次;目录项记录的页

专门新分配了页10来存储目录项记录。目录项记录和普通的用户记录不同点如下:
- 目录项记录的record_type为1;普通用户记录 的 record_type为0
- 目录项记录只有 主键值和页的编号 两个列;普通用户记录的列是用户自己定义的,可能包含很多列,另外还有InnoDB自己添加的隐藏列
- 了解:记录头信息里还有一个叫 min_rec_mark 的属性,只存储在 目录项记录 的页中的主键值最小的 目录项记录 的 min_rec_mask 值为 1 ,其他别的记录的 min_rec_mask 值都是 0
相同点:两者使用一样的数据页,都会主键值生成Page Directory(页目录),从而在按照主键值进行查找时可以使用二分法来加快查询速度
迭代两次:多个目录项记录的页

当我们插入一条主键值为320的用户记录之后需要两个新的数据页
- 为存储该用户记录新生成页31
- 原先存储目录项记录的页30的容量已满(前边假设只能存储4条目录项记录),故需要新的页32来存放页31对应的目录项
迭代三次:目录项记录页的目录页

生成一个存储更高级目录项的 页33,如果用户记录的主键值在[1,320)之间,则到页30中查找更详细的目录项记录,如果主键值不小于320的话,就到页32中查找更详细的目录项记录
B+树
上述结构可以用B+树这个数据结构描述

一个B+树节点其实可以分为好多层,规定最底层存储用户记录,其余都是目录项记录页
常见索引概念
索引按照物理实现方式可分为2种:聚簇(聚集)、非聚簇(非聚集)索引。有时也把非聚簇索引称为二级索引或者辅助索引
聚簇索引
特点: 1、使用记录主键值的大小进行记录和页的排序,这包括三方面含义 -页内的记录按照主键的大小顺序排成一个单项链表 -各个存放用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表 -存放目录项记录的页分为不同层次,在同一层次中的页根据目录项几轮的主键大小顺序排成一个双向链表 2、B+树的叶子节点存储完整的用户记录(完整的用户记录指存储了所有列的指,包括隐藏列) 优点: -数据访问更快,聚簇索引将索引将数据保存在同一个B+树中,因此从聚簇索引中获取的数据比非聚簇索引更快 -聚簇索引对于主键的排序查找、范围查找速度非常快 -按照聚簇排列顺序,查询显示一定范围数据时,由于数据紧密相连,数据库不用从多个数据块中提取数据,节省大量IO操作 缺点: -插入速度严重依赖于插入顺序,按照逐渐的顺序插入式最快的方式,否则将会出现页分类,严重影响性能。对于InnoDB表,一般会定义一个自增的ID列为主键 -更新主键的代价很高,因为将会导致被更新的行移动。对于InnoDB表,一般定义主键为不可更新 -二级索引访问需要二次索引查找,第一次找到主键值,第二次根据主键值找到行数据- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
二级索引(辅助索引、非聚簇索引)

回表:如果某个查询语句使用了二级索引,但是查询的数据不是主键值,这时在二级索引找到主键值后,需要去聚簇索引中获得数据行,这个过程就叫作「回表」,也就是说要查两个 B+ 树才能查到数据。不过,当查询的数据是主键值时,因为只在二级索引就能查询到,不用再去聚簇索引查,这个过程就叫作「索引覆盖」,也就是只需要查一个 B+ 树就能找到数据
联合索引
同时为多个列建立索引,以多个列的大小作为排序规则,比方说想让B+树按照c2列和c3列的大小进行排序
- 先把各个记录和页按照c2列进行排序
- 在记录c2列相同的情况下,采用c3列进行排序
以c2、c3列的大小为排序规则建立的B+数称为联合索引,其本质上也是一个二级索引,但与分别为c2、c3列建立索引不同
- 联合索引只有一颗B+树
- 为c2、c3分别建立索引,会分别为c2、c3列的大小为排序规则建立两棵B+树
InnoDB的B+树索引注意事项
- 根页面位置万年不动
- 内节点中目录项记录的唯一性
- 一个页面最少存储2条记录
MyISAM中的索引方案
B树索引适用存储引擎如表所示
索引/存储引擎 MyISAM InnoDB Memory B-Tree索引 支持 支持 支持 即使多个存储引擎支持同一种类型的索引,但是他们的实现原理不同
InnoDB、MyISAM默认的索引是Btree索引;Memory默认索引为Hash索引
MyISAM引擎使用B+Tree作为索引结构,叶子节点的data域存放 数据记录的地址
MyISAM索引原理
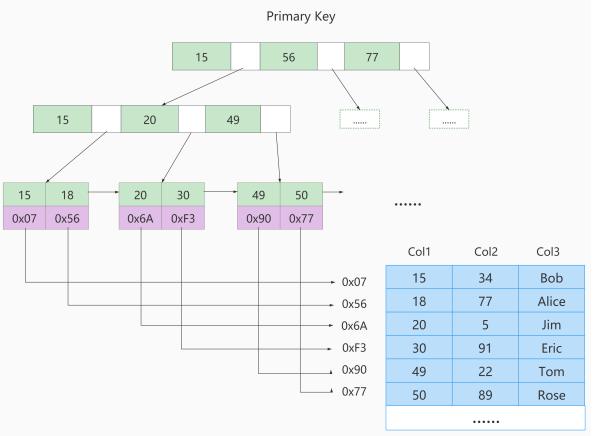
如果我们在Col2上建立一个二级索引,则此索引的结构如下图所示

MyISAM与InnoDB对比
MyISAM的索引方式都是“非聚簇的”,InnoDB中包含1个聚餐索引。
- 在InnoDB存储引擎中,我们只需要根据主键值对聚簇索引进行一次查找就能找到对应记录,而在MyISAM中却需要进行一次回表操作,MyISAM中建立的索引相当于全部是二级索引
- InnoDB的数据文件本身就是索引文件,而MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址
- InnoDB的非聚簇索引data域存储相应记录主键的值,而MyISAM索引记录的是地址
- MyISAM的回表操作十分快速,因为是拿着地址偏移量直接到文件中取数据,反观InnoDB是通过获取主键之后再去聚簇索引里找记录
- InnoDB要求表必须有主键(MyISAM可以没有)。若没有显示指定,MySQL系统会自动选择一个非空且唯一表示数据记录的列作为主键。如果不存这种列,MySQL将自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整型

索引的代价
- 空间上的代价:每建立一个索引都要为其建立一颗B+树,每一棵B+树的每一个节点都是一个数据页(默认16KB)
- 时间上的代价:每次对表中的数据进行增、删、改操作时,都需要去修改各个B+树索引。存储引擎需要额外的时间进行一些记录移位、页面分裂、页面回收等操作来维护好节点和记录的排序。
-
相关阅读:
研发项目管理系统对比:找到最适合的高效工具
deque容器 常用 API操作
Flutter 自定义 TextInputFormatter 文本输入过滤器 Flutter 实现输入4位自动添加空格
【深度学习笔记】6_2 循环神经网络RNN(recurrent neural network)
京东商品如何同步主图到长主图
java计算机毕业设计菲特尼斯健身管理系统设计与实现MyBatis+系统+LW文档+源码+调试部署
Jetson Orin 平台R35.3.1版本 vi-output线程CPU占用高导致不能出图问题排查
【数据结构与算法】初识时间空间复杂度
第46节——redux中使用不可变数据+封装immer中间件——了解
【LeetCode每日一题:809.情感丰富的文字~~~双指针+计数器】
- 原文地址:https://blog.csdn.net/mynameisgt/article/details/124912663