-
基于Pytorch的图卷积网络GCN实例应用及详解3.0
基于Pytorch的图卷积网络GCN实例应用及详解3.0
基于Pytorch的图卷积网络GCN实例应用及详解3.0的实例应用依旧是图的二分类任务,数据训练预测模型框架没有变化,主要是数据集本身及其处理和重新构造及损失函数选择发生变化,其余部分发生细微变化。
一、前期基础(建议先阅读下面链接1.0版本的前期基础文章,也许有童鞋会问1.0直接到3.0,那2.0哪去了呢?博主曰:3.0-1.0=2.0,哈哈哈,皮一下!)
前期基础文章:点击打开《基于Pytorch的图卷积网络GCN实例应用及详解》文章
二、图卷积网络GCN实现前期准备(基于1.0新增部分)
- 个人数据集构造:点击打开《基于Pytorch的PyTorch Geometric(PYG)库构造个人数据集》文章
- Jupyter Notebook安装:点击打开《Jupyter Notebook安装及使用指南》文章
- Jupyter Notebook自动补全代码配置:点击打开《Jupyter Notebook自动补全代码配置》文章
- 关于图和实例的学习之相关概念:点击打开《关于图和实例的学习之相关概念个人理解》文章
- 基于Python之邻接矩阵沿对角线拼接:点击打开《基于Python之邻接矩阵沿对角线拼接操作简单方法》文章
- 基于Pytorch之深度学习模型数据类型和维度转换:点击打开《基于Pytorch之深度学习模型数据类型和维度转换个人总结》文章
三、图卷积网络GCN实现案例分析(重要)
- 案例目的:构造图卷积网络模型训练后进行图包(超图)二分类(0和1)预测。注意:此篇文章图包是只包含图不包含实例内容。
- 数据集及格式说明(重要):mat文件数据集(MATLAB的专属文件)的导入和构造,博主已有的数据集存放在J盘以 aidbBag.mat 文件形式保存下来。

- aidbBag.mat文件数据结构(见下图):aidbBag.mat文件内只包含一个名称为 ”bags“ 的文件,bags文件存储了2行和1600列的图数据,其中第一行表示超图(图包),每一个数据用数据结构体(struct)存储表示,第二行表示对应超图(图包)的标签,1表示正标签,-1表示负标签(注意:在后续实际代码设计中因计算原因将负标签的值 -1 改成 0 进行操作,结果不受影响),总而言之,数据集包含1600个超图(图包)及其对应的超图(图包)标签。注意:每张超图(图包)内构成的子图数量一般是不一样的,有的超图可能包含8张子图,有的可能包含2张子图。

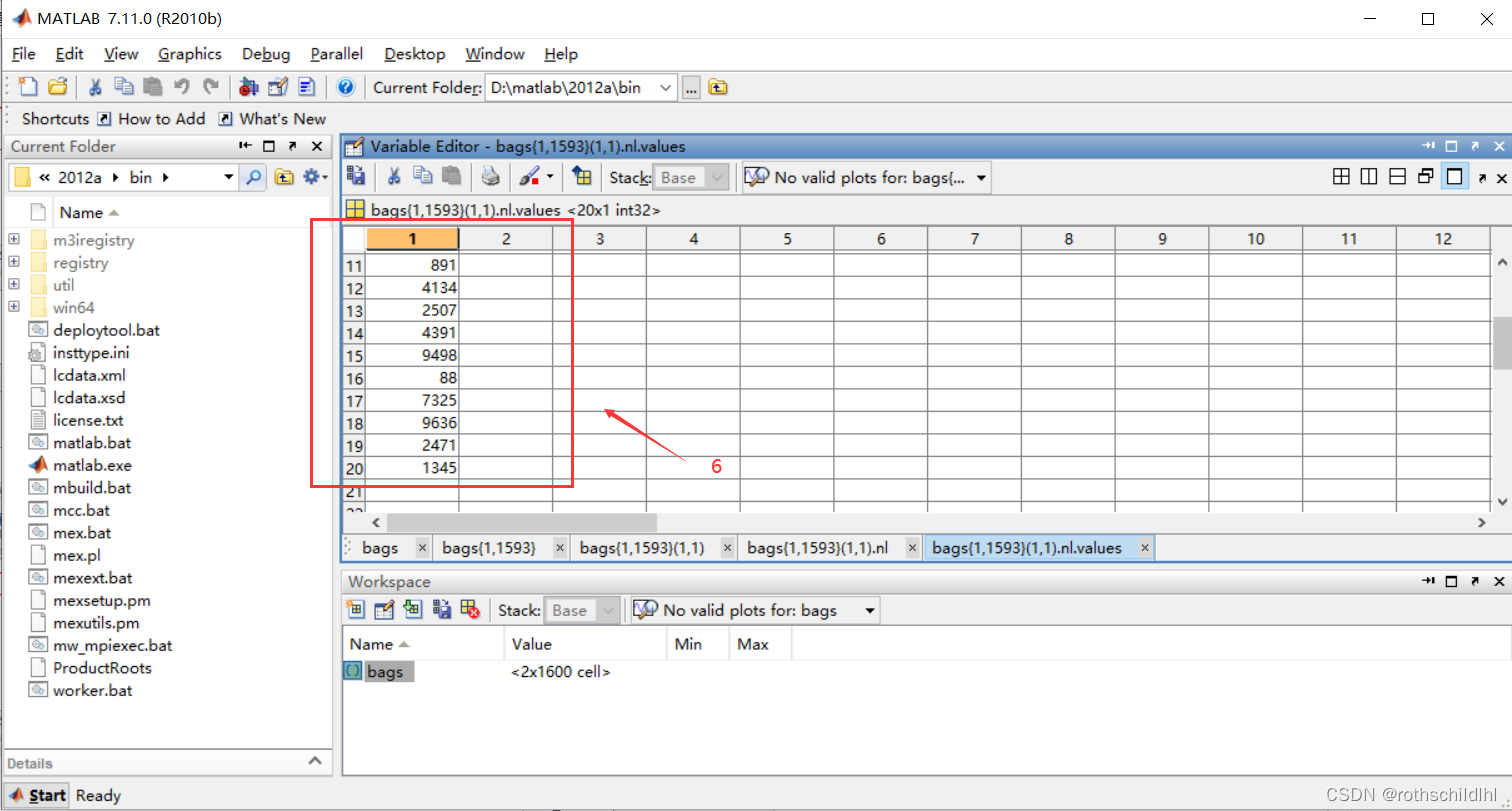
- 超图(图包)结构:选择点击进去上图第一行及第一列的数据,也就是第一个超图(图包),发现里面只有1行和9列的图数据,每一个数据用数据结构体存储表示,每个数据表示构成第一个超图(图包)的子图。

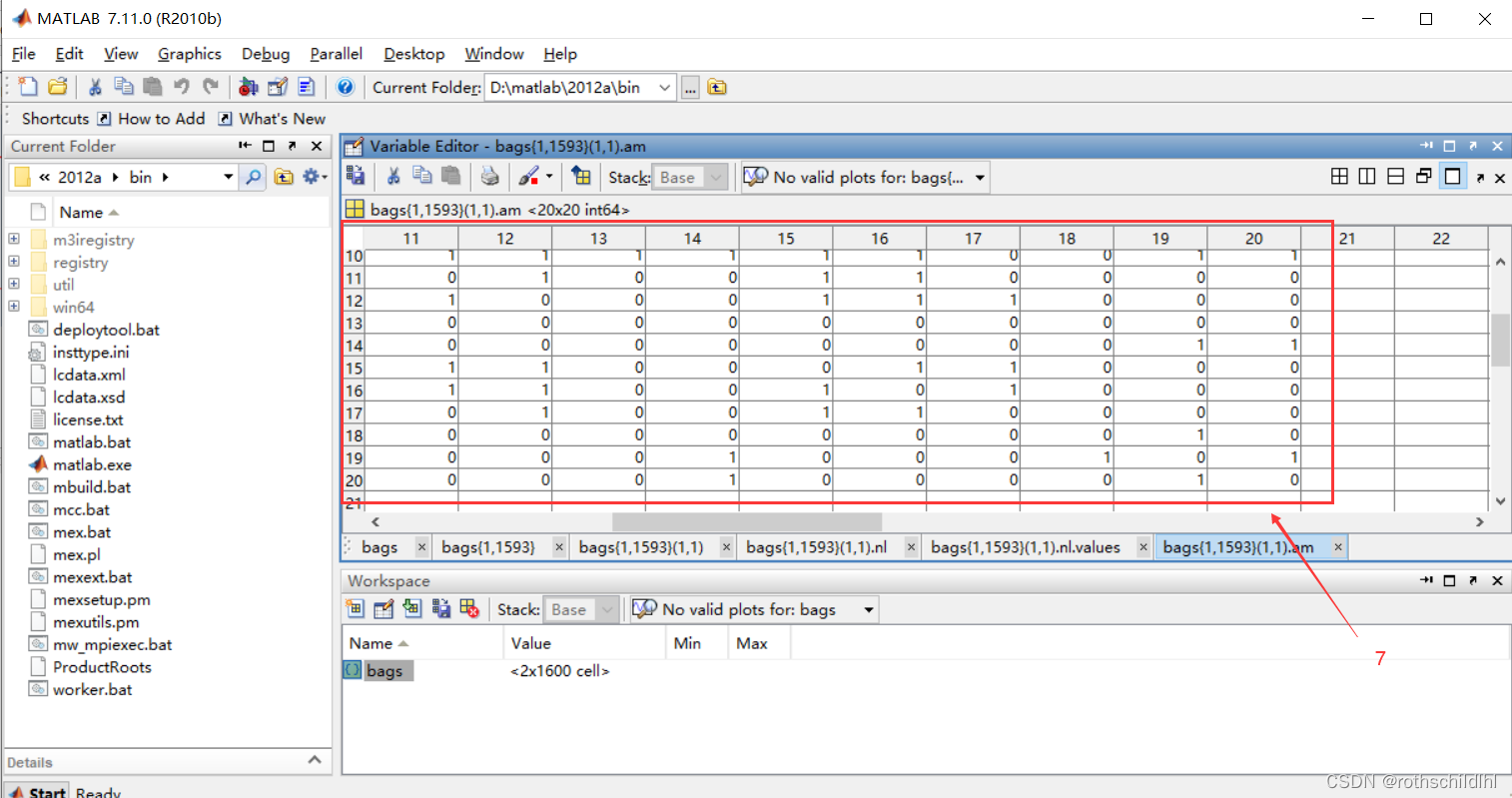
- 子图结构:选择点击进去上图第一行及第一列的数据,也就是第一个超图(图包)的第一个子图,发现包含nl、am 和 no;nl 点进去之后是values表格,再点进去就是子图节点及特征,维度是[20,1];am 表示子图节点之间的邻接矩阵,维度是[20,20];no 表示子图的序号,维度是[1] 。



三、图卷积网络GCN实现分步及完整代码
- dataset.py(数据集处理及保存):结构设计是按照 《基于Pytorch的PyTorch Geometric(PYG)库构造个人数据集》文章 设计的,主要是 processed() 函数处理原始 aidbBag.mat 数据集,重构成 torch_geometric.data 数据类型Data,思路是循环读取每一个超图(图包),然后再循环将每张超图(图包)的所有节点及其属性 nl 直接按顺序依次用 torch.cat 连接成 x ,再将其所有包含的子图的邻接矩阵 am 依次取出进行沿对角线拼接,然后形成一张超图邻接矩阵再转换成稀疏矩阵 edge_index ,然后循环将每个超图(图包)处理后的 x、edge_index 及 超图(图包)的标签 y 重构成 torch_geometric.data 数据类型 Data ,然后将Data依次汇集到一个列表 dataset ,再使用 random 函数随机打乱顺序,最后生成一个 datas.pt 文件保存 dataset 并返回 MyOwnDataset 对象,便于后面 DataLoader 分批处理。注意:在下面程序读取 bags 文件后,得到的数据内容分布是
[ [第1个图包,第1个图包标签,第2个图包,第2个图包标签...,第800个图包,第800个图包标签],[第801个图包,第801个图包标签,第802个图包,第802个图包标签...,第1600个图包,第1600个图包标签] ],数据维度是 [2,1600] 大小。
import torch from torch_geometric.data import InMemoryDataset from torch_geometric.data import Data import mat4py import scipy.sparse as sp import numpy as np import warnings import random from torch_geometric.data import DataLoader warnings.filterwarnings("ignore", category=Warning) # 这里给出大家注释方便理解 # 程序只要第一次运行后,processed文件生成后就不会执行process函数,而且只要不重写download()和process()方法,也会直接跳过下载和处理。 class MyOwnDataset(InMemoryDataset): def __init__(self, root, transform=None, pre_transform=None): super().__init__(root, transform, pre_transform) self.data, self.slices = torch.load(self.processed_paths[0]) # 根据保存路径加载处理好processed中的文件 # print(self.data) # 输出torch.load加载的数据集data # print(root) # MYdata # print(self.data) # Data(x=[3, 1], edge_index=[2, 4], y=[3]) # print(self.slices) # defaultdict(<class 'dict'>, {'x': tensor([0, 3, 6]), 'edge_index': tensor([ 0, 4, 10]), 'y': tensor([0, 3, 6])}) # print(self.processed_paths[0]) # MYdata\processed\datas.pt # 返回数据集源文件名,告诉原始的数据集存放在哪个文件夹下面,如果数据集已经存放进去了,那么就会直接从raw文件夹中读取。 @property def raw_file_names(self): # pass # 不能使用pass,join() argument must be str or bytes, not 'NoneType' return [] # 返回process方法保存的文件名processed_paths[0]路径下的文件名 @property def processed_file_names(self): return ['datas.pt'] # 用于从网上下载数据集,下载原始数据到指定的文件夹下,自己的数据集可以跳过 def download(self): pass # 生成数据集所用的方法,程序第一次运行才执行并生成processed文件夹的处理过后数据的文件,否则必须删除已经生成的processed文件夹中的所有文件才会重新执行此函数 def process(self): # 测试构建Data # edge_index1 = torch.tensor([[0, 1, 1, 2], # [1, 0, 2, 1]], dtype=torch.long) # # edge_index2 = torch.tensor([[0, 1, 1, 2 ,0 ,1], # [1, 0, 2, 1 ,0 ,1]], dtype=torch.long) # # # 节点及每个节点的特征:从0号节点开始 # X = torch.tensor([[-1], [0], [1]], dtype=torch.float) # # 每个节点的标签:从0号节点开始-两类0,1 # Y = torch.tensor([0, 1, 0], dtype=torch.float) # # # 创建data数据 # data1 = Data(x=X, edge_index=edge_index1, y=Y) # data2 = Data(x=X, edge_index=edge_index2, y=Y) # # # 将data放入datalist # data_list = [data1,data2] # data_list = data_list.append(data) # 数据集读取 datas = mat4py.loadmat('J:/aidbBag.mat') # 1600个图包(各图包含若干张图,每张图有20个节点及其属性,邻接矩阵和图编号)及其包标签 datas = datas['bags'] # 获取bags文件的内容,输出为list数据类型,行数为2,列数为1600,图包和包标签并行相邻 # 将a,b两个矩阵沿对角线方向斜着合并,空余处补0 def adjConcat(a, b): lena = len(a) lenb = len(b) left = np.row_stack((a, np.zeros((lenb, lena)))) # 先将a和一个len(b)*len(a)的零矩阵垂直拼接,得到左半边 right = np.row_stack((np.zeros((lena, lenb)), b)) # 再将一个len(a)*len(b)的零矩阵和b垂直拼接,得到右半边 result = np.hstack((left, right)) # 将左右矩阵水平拼接 return result # 对每个图包的数据进行预处理 dataset = [] for i in range(2): # 行数 for j in range(0, len(datas[i]), 2): # 列数 # 邻接矩阵数据预处理 am = datas[i][j]['am'] # 图包中所有图的邻接矩阵 # 将图包中所有图沿边角线连接拼接成一张超图matrix matrix = am[0] for w in range(len(am) - 1): matrix = adjConcat(matrix, am[w + 1]) w += 1 # 将邻接矩阵的超图转换为稀疏矩阵 edge_index_temp = sp.coo_matrix(matrix) indices = np.vstack((edge_index_temp.row, edge_index_temp.col)) edge_index = torch.LongTensor(indices) # 节点数据预处理 nl = datas[i][j]['nl'] # 图包中所有图的各图的节点及其属性值,维度是[20,1] # 将图包中所有图的节点进行拼接 for k in range(len(nl)): x = np.array(list(nl[k].values())) x = x.squeeze(0) node = torch.FloatTensor(x) if k > 0: nodes = torch.cat([nodes, node]) else: nodes = node # 拼接成维度为[每张图片节点数20*图包中图片的数目,1] x = nodes # 图包标签预处理 # 注意:图包标签和图包数据并行(hang)相邻 j += 1 if datas[i][j] == -1: data = Data(x=x, edge_index=edge_index, y=0) # 构建新型data数据对象 else: data = Data(x=x, edge_index=edge_index, y=1) # 构建新型data数据对象 # 图包标签整型数据转张量tensor,方便后面正确率结果对比 data.y = np.array(data.y, dtype=np.float32) data.y = torch.LongTensor(data.y) # 构建数据集:为一张超图(图包中的图拼接成),图包中所有图片数目*20个节点,每个节点一个特征,Coo稀疏矩阵的边,一张超图一个超图(图包)标签 dataset.append(data) # 将每个data数据对象加入列表 # 打乱数据集的数据 random.shuffle(dataset) if self.pre_filter is not None: # pre_filter函数可以在保存之前手动过滤掉数据对象。用例可能涉及数据对象属于特定类的限制。默认None data_list = [data for data in dataset if self.pre_filter(data)] if self.pre_transform is not None: # pre_transform函数在将数据对象保存到磁盘之前应用转换(因此它最好用于只需执行一次的大量预计算),默认None data_list = [self.pre_transform(data) for data in dataset] data, slices = self.collate(dataset) # 直接保存list可能很慢,所以使用collate函数转换成大的torch_geometric.data.Data对象 # print(data) torch.save((data, slices), self.processed_paths[0]) # 保存处理后的数据,self.processed_paths[0]来源于MyOwnDataset("E:\GCNmodel\MYdata")的路径参数E:\GCNmodel\MYdata # # 数据集对象操作 # data = MyOwnDataset("E:\GCNmodel\MYdata") # 创建数据集对象 # print(data) # MyOwnDataset(1600) # data_loader = DataLoader(data, batch_size=1, shuffle=False) # 加载数据进行处理,每批次数据的数量为1 # for data in data_loader: # print(data) # 按批次输出数据- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- model.py(GCN模型构建和训练及保存):首先构建MyOwnDataset对象实例读取处理好的数据集(若未处理则会先执行dataset.py然后返回处理好的数据),然后将数据集分成训练和测试两部分,将训练数据集输入到构建好的模型,然后使用反向传播实现模型参数训练。其中使用的损失函数选择CrossEntropyLoss函数(公式二分类见下图),此函数就是把log_sofrmax和NLLLoss合并成一步。使用log_sofrmax函数,得到每张图片每个类别的概率分布,根据每张图片的label将对应图片的索引的值拿出来,所有图片累加值再对结果取负值,比如:有一张图片是二分类,log_softmax函数使用后得到的概率是[0.4,0.6],该图片的label的值是0,那么根据label对应图片的索引的值下标为0的概率是0.4,则取出的结果是0.4,再取负数就是-0.4。最优化损失函数值,那么应该取最小值,概率越大取负值越小。然后使用torch.save保存模型,模型的保存和加载详见 《基于Pytorch的深度学习模型保存和加载方式》文章。

import random import torch import torch.nn.functional as F from torch_geometric.nn import GCNConv from torch_geometric.data import DataLoader import torch_geometric.nn as pyg_nn import numpy as np import warnings from sklearn.metrics import accuracy_score warnings.filterwarnings("ignore", category=Warning) from dataset import MyOwnDataset # 导入数据集 dataset = MyOwnDataset("E:\GCNmodel\MYdata") # 切分数据集,分成训练和测试两部分 train_dataset = dataset[:1200] test_dataset = dataset[1200:1600] # 构造模型类 class Net(torch.nn.Module): """构造GCN模型网络""" def __init__(self): super(Net, self).__init__() self.conv1 = GCNConv(1, 16) # 构造第一层,输入和输出通道,输入通道的大小和节点的特征维度一致 self.conv2 = GCNConv(16, 2) # 构造第二层,输入和输出通道,输出通道的大小和图或者节点的分类数量一致,比如此程序中图标记就是二分类0和1,所以等于2 def forward(self, data): # 前向传播 x, edge_index, batch = data.x, data.edge_index, data.batch # 赋值 # print(batch) # print(x) x = self.conv1(x, edge_index) # 第一层启动运算,输入为节点及特征和边的稀疏矩阵,输出结果是二维度[20张超图的所有节点数,16] # print(x.shape) x = F.relu(x) # 激活函数 x = F.dropout(x, training=self.training) x = self.conv2(x, edge_index) # 第二层启动运算,输入为节点及特征和边的稀疏矩阵,输出结果是二维度[20张超图的所有节点数,2] x = pyg_nn.global_max_pool(x, batch) # 池化降维,根据batch的值知道有多少张超图(每个超图的节点的分类值不同0-19),再将每张超图的节点取一个全局最大的节点作为该张超图的一个输出值 # print(x.shape) # 输出维度变成[20,2] x = torch.FloatTensor(x) return x # 使用GPU # device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 构建模型实例 model = Net() # 构建模型实例 optimizer = torch.optim.Adam(model.parameters(), lr=0.005) # 优化器,模型参数优化计算 train_loader = DataLoader(train_dataset, batch_size=20, shuffle=False) # 加载训练数据集,训练数据中分成每批次20个超图data数据 loss_model = torch.nn.CrossEntropyLoss() # print(len(train_dataset)) # 训练模型 model.train() # 表示模型开始训练,在使用pytorch构建神经网络的时候,训练过程中会在程序上方添加一句model.train(),作用是启用batch normalization和drop out。 for epoch in range(100): # 训练所有训练数据集100次 loss_all = 0 # 一轮epoch优化的内容 for data in train_loader: # 每次提取训练数据集一批20张超图数据赋值给data # print(data) # data是batch_size图片的大小 # print(data.edge_index) # print(data.batch.shape) # print(data.x.shape) optimizer.zero_grad() # 梯度清零 output = model(data) # 前向传播,把一批训练数据集导入模型并返回输出结果 label = data.y # 20张超图数据的标签集合 # print(data.y) loss = loss_model(output,label) # 损失函数计算 loss.backward() #反向传播 loss_all += loss.item() # 将最后的损失值汇总 optimizer.step() # 更新模型参数 tmp = (loss_all / len(train_dataset)) # 算出损失值或者错误率 if epoch % 20 == 0: print(tmp) # 每二十次训练完整个训练数据集,输出其错误率 # 保存整个model的状态,也就是model的预训练模型 torch.save(model, "E:\GCNmodel\model\MyGCNmodel.pt") # 没有定义绝对路径情况下和此文件同文件夹- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- test.py(GCN模型加载及测试):测试数据集导入模型,进行超图(图包)二分类(0,1)结果预测。
import torch from torch_geometric.data import DataLoader import numpy as np import warnings from sklearn.metrics import accuracy_score warnings.filterwarnings("ignore", category=Warning) from model import test_dataset # 导入已训练好的GCNmodel预训练模型 model=torch.load("E:\GCNmodel\model\MyGCNmodel.pt") # 测试 preds = [] # 预测标签列表 label = [] # 真实标签列表 loaders = DataLoader(test_dataset, batch_size=20, shuffle=False) # 读取测试数据集数据 with torch.no_grad(): for predata in loaders: pred = model(predata).numpy() label.append(predata.y.tolist()) for i in range(pred.shape[0]): tmp = pred[i].tolist() # tensor转成列表,pred[i]表示第i张超图 # print(tmp.index(max(tmp))) preds.append(tmp.index(max(tmp))) # 从列表的两个元素选出最大的tmp.index(x)返回寻找元素x的下标,此时只有两个元素那么下标就是0和1 preds = np.squeeze(np.array(preds)).tolist() # 真实超图(图包)的标签数据集 label = [i for item in label for i in item] # 输出结果和统计模型预测正确率 print(preds) # 输出预测的超图(图包)标签 print(label) # 输出真实的超图(图包)标签 print(accuracy_score(label, preds)) # 求出分类准确率分数是指所有分类正确的百分比率,完全正确为1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
四、图卷积网络GCN代码运行过程和结果
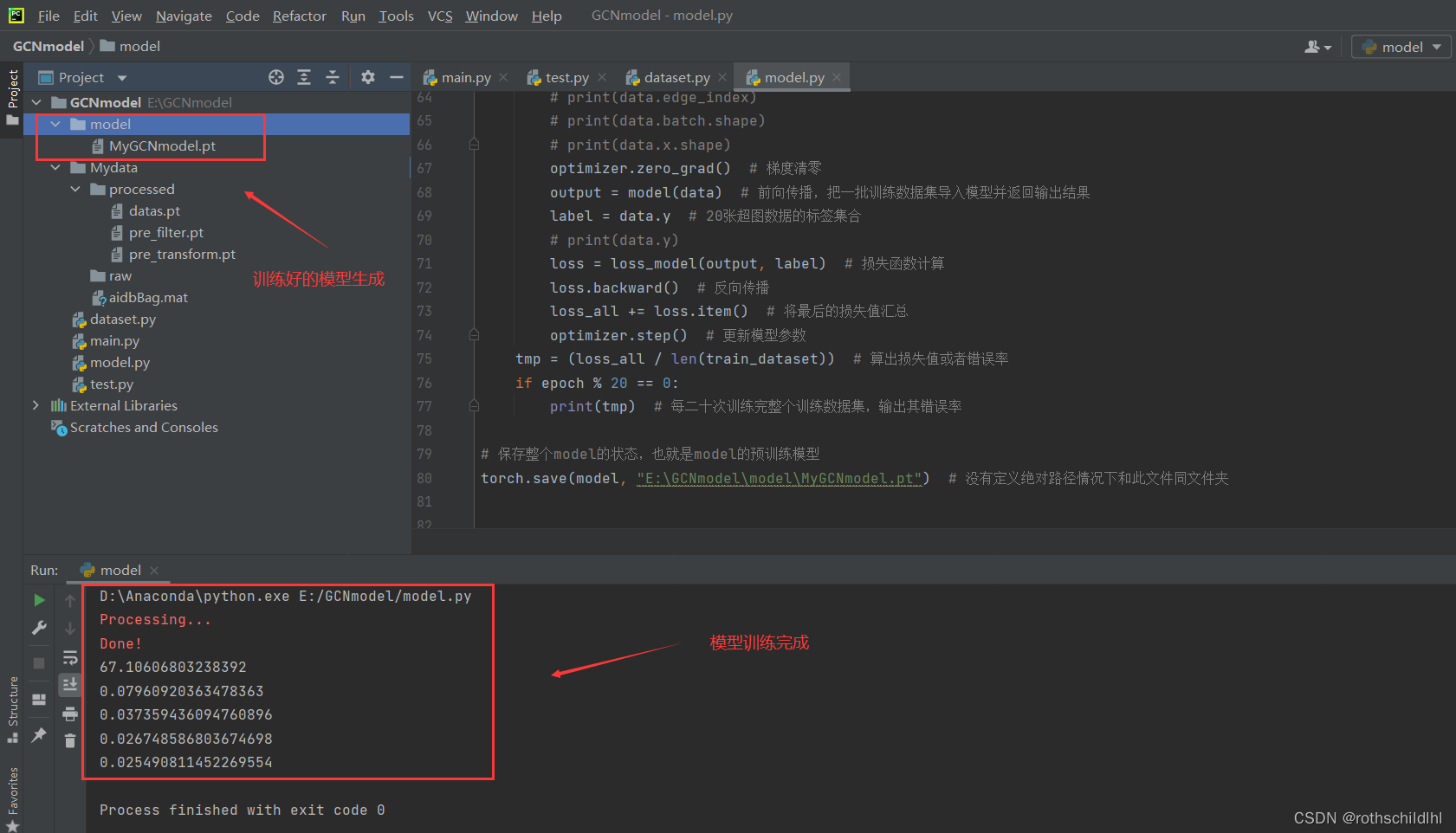
- 首先运行model.py文件,得到处理后的数据集(训练集和测试集)和训练好的模型
- 运行test.py文件,加载训练好的模型和处理好的测试数据集,最后得出预测正确率
- 运行结果展示(model.py和test.py):


-
相关阅读:
springboot配置打野sql语句,而不打印结果
整数的运算
编程未来规划笔记
Android/Linux系统学习---目录
c++学习 之 强制类型转换
【RabbitMQ】初识 RabbitMQ
蒂姆·库克喜提《时代》杂志2022百大影响力人物封面,谷爱凌、杨紫琼也入选
【深入浅出Spring6】第九期——Spring对事务的支持
ceph 删除 osd 重新添加 osd down 重建
python facebook business SDK campaign 广告复制方法
- 原文地址:https://blog.csdn.net/rothschild666/article/details/124899545