-
优化sql语句——mysq亿级数据量查询优化(一)
目录
前言:
在我们进行项目的开发的时候,我们经常会遇到数据量很大的数据,当我们进行数据查询的时候,查询的速度就非常之慢。今天就来分享一下该去怎么去优化查询
一、 常规优化
一、建立场景:
现在有一张表,physical 是体检表,包含用户信息等,可以理解为用户信息和体检信息,physical_detail 可以理解为 体检的项目,而 physical_detail_item 则是 体检的具体结果,你可以假设一个用户 有 10 -20 个体检项,有 1000 - 1500条 体检结果,即 physical 里 一条记录 对应 physical_detail 里的 10 -20 条记录,对应 physical_detail_item 里的 1000 - 1500 条记录。
- SELECT *
- FROM (
- SELECT a.*, ROW_NUMBER() OVER (ORDER BY physicalDetailItemId DESC) AS rownum
- FROM (
- SELECT p.xxx,xxxx
- FROM physical_detail_item pdi
- LEFT JOIN physical_detail pd ON pd.id = pdi.detail_id
- LEFT JOIN physical p ON p.id = pd.physical_id
- WHERE p.hospital_Id = 'AHSLTJZX'
- ) a
- ) b
- WHERE rownum > (1000 - 1) * 20
- AND rownum <= 1000 * 20;
以上这段sql语句耗时37s
说明:
这里,省略了 select 部分的字段,性能与其无关。之所以省略,毕竟是公司项目哈。这里的 row_number over 其实 是 sql server 里的,类似 mysql 的 limit,但是 mysql 兼容 row_number over 而 sql server 却不支持 limit。
二、进行优化
在优化前,我先关闭了 mysql 缓存,即:
set global query_cache_size=0; set global query_cache_type=0;
1、普通优化:
- SELECT p.xxx,xxx
- FROM physical_detail_item pdi
- LEFT JOIN physical_detail pd ON pd.id = pdi.detail_id
- LEFT JOIN physical p ON p.id = pd.physical_id
- WHERE p.hospital_Id = 'AHSLTJZX'
- ORDER BY physicalDetailItemId DESC
- LIMIT 0, 20;
此时,耗时 13- 18 秒,分页越大越慢,但整体而言,优化了将近一半吧,算是巨大的提升了。
2、分页优化:
- SELECT p.xxx,xxx
- FROM physical_detail_item pdi
- LEFT JOIN physical_detail pd ON pd.id = pdi.detail_id
- LEFT JOIN physical p ON p.id = pd.physical_id
- WHERE p.hospital_Id = 'AHSLTJZX' and pdi.id > (select id from physical_detail_item order by id desc limit 1499979, 1)
- ORDER BY physicalDetailItemId DESC
- LIMIT 20;
此时,保持在 13 - 14 秒之间,这性能依旧不怎么样,毕竟没有查询,或者说就是个联合查询,除了联合查询的条件外,没有任何额外的条件。
3、最终优化:
- SELECT p.xxx,xxx
- FROM physical_detail_item pdi
- LEFT JOIN physical_detail pd ON pd.id = pdi.detail_id
- LEFT JOIN physical p ON p.id = pd.physical_id
- WHERE pdi.id IN (
- SELECT t.id
- FROM (
- SELECT id
- FROM physical_detail_item
- ORDER BY id DESC
- LIMIT 1499980, 20
- ) t
- )
- ORDER BY physicalDetailItemId DESC;
此时,查询只需要 2.14 秒,优化了 7倍 !
三、归纳和总结
1、归纳
现在,我们回过头来研究下,为啥这几条 sql 为啥会有这么大的性能差距,第一二条,很明显是 row_number over 和 limit 的性能问题了,不在本文的讨论之内,而之后是对分页做的优化,按理说,第三条性能最佳,但是第三条没有限定 id 上限,这是败笔,如果第三条同时限制了最大和最小的id,那么性能不应该输给第四条!遗憾的是,这个已经无法再证实了,但是如果同时限定了 pdi.id 的最小和最大值,性能当最佳。
2、总结
对于多表关联的查询,最好限定最大的那张表的查找范围,否则性能极差。这里,pdi 这张表最大,如果不限定它的查找范围,就意味着所有的数据都符合该语句的查找,然后返回的就是数百万数据,最后再来个 limit,其性能最差。而如果限定了最大的这张表的查找范围,那么查找的数据可能只有区区几十条而已,这个性能提升显而易见。
二、建立索引
1、建立场景
模拟“用户信息表”来进行测试,建立以下数据表:
- CREATE TABLE `user_info` (
- `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '用户ID',
- `name` varchar(32) NULL COMMENT '姓名',
- `phone_number` varchar(32) NULL COMMENT '电话号码',
- `email` varchar(32) NULL COMMENT '电子邮箱',
- `birthday` varchar(32) NULL COMMENT '生日',
- `constellation` varchar(32) NULL COMMENT '星座',
- `edu_back` varchar(32) NULL COMMENT '学历',
- PRIMARY KEY (`id`)
- ) ENGINE=InnoDB
- DEFAULT CHARACTER SET=utf8 COLLATE=utf8_general_ci;
进行测试的两个方向:测试行数的增加对检索性能的影响,测试维度有2个,一是带索引字段,二是不带索引字段,由于主键的id字段默认带唯一索引,因此不再额外增加索引。表中其他字段均不带索引。使用时分别使用 id 和 email 字段进行测试。
2、测试数据
首先我们自动生成1000行测试数据,使用:
SELECT * FROM user_info where id=345;进行检索,测试结果为:

下面使用同一行的email值进行检索:
SELECT * FROM user_info where email='h3l_q_iozoi@dmstest.com.cn';测试结果也是耗时 4 毫秒,两者没有差距,接下来增加数量值
10000行:
我们增加9000行数据,使数据量达到10000行,同时为避免数据库缓存数据影响测试结果,后续均使用不同的id行来进行测试。(email也是随机找到一个)
我们继续测试:
(1)使用 id 进行检索,耗时 2 毫秒(居然比1000行时还要少,有点不科学)
(2)使用 email 进行检索,耗时 6 毫秒。
10万行
我们再增加90000行数据,使数据量达到100000行。

测试结果为:
(1)使用 id 进行检索,耗时 8 毫秒
(2)使用 email 进行检索,耗时 78 毫秒。
100万行
我们再增加900000行数据,是数据量达到1000000行。
测试结果为:
(1)使用 id 进行检索,耗时 3 毫秒
(2)使用 email 进行检索,耗时 387 毫秒
200万行
由于阿里云DMS自带的工具一次最多只能生成100万行记录,遇到了瓶颈,后面为了能够一次性插入更多的数据,这里用了一个技巧,我们使用相同的表结构新增一个中转表(命名:temp_copy,以下简称“副表”),先将主表数据拷贝一份过去,再把数据拷贝回来,这相当于一来一回操作能够将主表数据翻倍,后面我们就使用这个方法来增加数据。
先将数据从主表拷贝到副表(耗时 13338 毫秒):
INSERT INTO temp_copy (name,phone_number,email,birthday,constellation,edu_back) (SELECT name,phone_number,email,birthday,constellation,edu_back FROM user_info) ;然后再将数据从副表拷贝一份至主表(耗时 11041 毫秒):
INSERT INTO user_info (name,phone_number,email,birthday,constellation,edu_back) (SELECT name,phone_number,email,birthday,constellation,edu_back FROM temp_copy) ;继续进行之前的测试,测试结果为:
(1)使用 id 进行检索,耗时 5 毫秒
(2)使用 email 进行检索,耗时 6739 毫秒。
第2项数据突变有点明显,我再使用其他数据测试了几遍,依然在这个范围徘徊,因此这个数据还是可靠的。
500万行
我们将数据继续在主表和副表之间倒腾了一遍,数据量达到了5000000行,我们继续测试:
(1)使用 id 进行检索,耗时 5 毫秒
(2)使用 email 进行检索,耗时 20289 毫秒。
1300万行
后面继续增加数据,可以很明显的感觉到插入数据的时间越来越多,这一次从主表拷贝至副表,500万行,耗时 61624 毫秒。我们继续从副表拷贝至主表,800万行,耗时 100028 毫秒。
继续测试,测试结果为:
(1)使用 id 进行检索,耗时 7 毫秒
(2)使用 email 进行检索,耗时 57498 毫秒。
3400万行
我们继续,再“左右到右手”进行一次拷贝:
(1)主表拷贝至副表,插入1300万行,耗时 169816 毫秒。
(2)副表拷贝至主表,插入2100万行,耗时 263856 毫秒。
数据量达到3400万行时,储存容易已经达到了3G,非常恐怖。
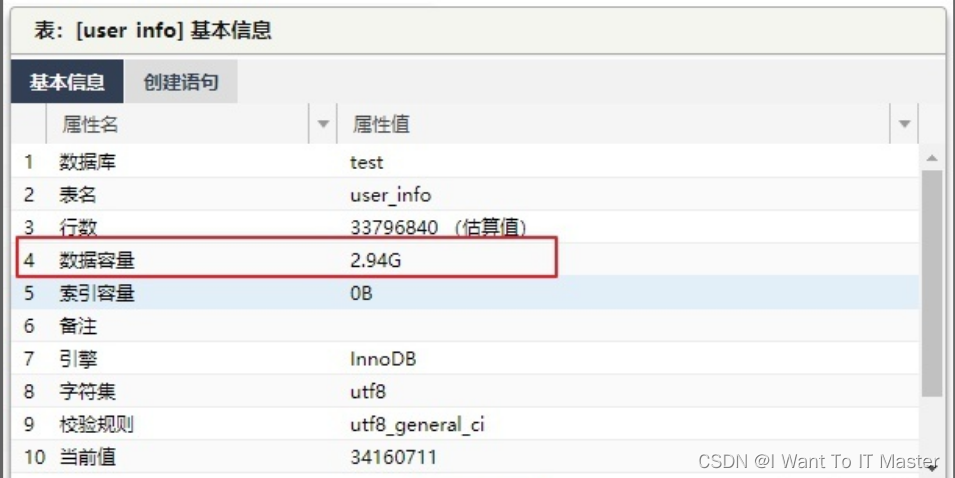
继续测试,测试结果为:
(1)使用 id 进行检索,耗时 6 毫秒
(2)使用 email 进行检索,耗时 153407 毫秒
3、总结
从100万行开始,email检索项的时间开始激增,事实上,这个检索时间已经大大超出能够接受的范围了。从以上的结果也可以看出建立索引的重要性。
-
相关阅读:
java计算机毕业设计springboot+vue小微企业人才推荐系统
Python - 深度学习系列36 重塑实体识别3
你的第一款开源视频分析框架
GDPU 数据结构 天码行空6
Python作图三维等高面
(附源码)springboot通用数据展示系统 毕业设计 200934
现货白银MACD实战分析例子
java计算机毕业设计框架的企业机械设备智能管理系统的设计与实现源码+数据库+系统+lw文档+mybatis+运行部署
AT2401C 功率放大器(PA)射频前端集成芯片
Could not autowire field: protected tk.mybatis.mapper.common.Mapper
- 原文地址:https://blog.csdn.net/m0_53151031/article/details/124902495