-
Kafka3.2教程(一)消息队列与Kafka原理
在ActiverMQ、RabbitMQ、RocketMQ等等诸多的消息队列技术中,Kafka是适合于大数据领域使用的消息队列。
Kafka是一个采用发布-订阅模式的消息队列,具有以下特点:易用性好,提供了较少的核心功能,但是提供超高的吞吐量,毫秒级的延迟,对数据可以持久化,并且根据需要可以任意搭建集群扩展。消息队列是什么:
消息(Message)是指在应用之间传送的数据,消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。
消息队列(Message Queue)是一种应用间的通信方式,消息发送后可以立即返回,有消息系统来确保信息的可靠专递,消息发布者只管把消息发布到MQ中而不管谁来取,消息使用者只管从MQ中取消息而不管谁发布的,这样发布者和使用者都不用知道对方的存在。
一个简单的消息队列设计图如下所示:
在实际应用中,消息队列有点对点与发布者和订阅者两种模式:
点对点消息传递模式

1.消息生产者Producer1生产消息到Queue,然后Consumer1从Queue中取出并且消费消息。
2.消息被消费后,Queue将不再存储消息,其它所有Consumer不可能消费到已经被其它Consumer消费过的消息。
3.Queue支持存在多个Producer,但是对一条消息而言,只会有一个Consumer可以消费,其它Consumer则不能再次消费。
4.但Consumer不存在时,消息则由Queue一直保存,直到有Consumer把它消费。应用场景:
高访问量的电商系统,当用户进行下单,则将支付信息提交到队列中,支付系统从队列中
获得该支付信息,从队列中删除,进行处理。不会造成重复支付。发布-订阅消息传递模式

1.消息发布者Publisher将消息发布到主题Topic中,同时有多个消息消费者 Subscriber消费该消息。
2.和PTP方式不同,发布到Topic的消息会被所有订阅者消费。
3.当发布者发布消息,不管是否有订阅者,都不会报错信息。
4.一定要先有消息发布者,后有消息订阅者。应用场景:
某明星微博有10万粉丝,她今天发布了一条微博,这10万粉丝都可以接收到她的更新。
以上两种模式的主要区别是否能重复消费,以往的消息队列往往只能实现其中的一种。Kafka是一个采用发布-订阅模式的消息队列,但借助kafka的消费者组机制,可以同时实现这两种模型。。
Kafka原理:
核心组件图:

- Producer API:生产者API允许应用程序将一组记录发布到一个或多个Kafka Topic中。
- Consumer AIP:消费者API允许应用程序订阅一个或多个Topic,并处理向他们传输的记录流。
- Streams API:流API允许应用程序充当流处理器,从一个或者多个Topic中消费输入流,并将输出流生成为一个或多个输出主题,从而将输入流有效地转换为输出流。
- Connector API:连接器API允许构建和运行可重用的生产者或消费者,这些生产者或消费者将Kafka Topic连接到现有的应用程序或数据系统。例如:连接到关系数据库的连接器可能会捕获对表的每次更改。
架构图:
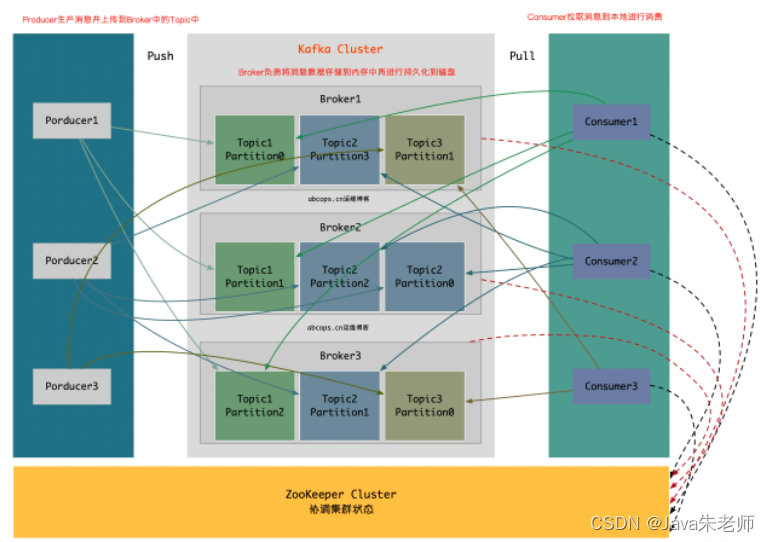
Producer:消息和数据的生产者,主要负责生产Push消息到指定Broker的Topic中。
Broker:Kafka节点就是被称为Broker,Broker主要负责创建Topic,存储Producer所发布的消息,记录消息处理的过程,现是将消息保存到内存中,然后持久化到磁盘。
Topic:同一个Topic的消息可以分布在一个或多个Broker上,一个Topic包含一个或者多个Partition分区,数据被存储在多个Partition中。
replication-factor:复制因子;这个名词在上图中从未出现,在我们下一章节创建Topic时会指定该选项,意思为创建当前的Topic是否需要副本,如果在创建Topic时将此值设置为1的话,代表整个Topic在Kafka中只有一份,该复制因子数量建议与Broker节点数量一致。
Partition:分区;在这里被称为Topic物理上的分组,一个Topic在Broker中被分为1个或者多个Partition,也可以说为每个Topic包含一个或多个Partition,(一般为kafka节.
点数CPU的总核心数量)分区在创建Topic的时候可以指定。分区才是真正存储数据的单元。
Consumer:消息和数据的消费者,主要负责主动到已订阅的Topic中拉取消息并消费,为什么Consumer不能像Producer一样的由Broker去push数据呢?因为Broker不知道Consumer能够消费多少,如果push消息数据量过多,会造成消息阻塞,而由Consumer去主动pull数据的话,Consumer可以根据自己的处理情况去pull消息数据,消费完多少消息再次去取。这样就不会造成Consumer本身已经拿到的数据成为阻塞状态。
ZooKeeper:ZooKeeper负责维护整个Kafka集群的状态,存储Kafka各个节点的信息及状态,实现Kafka集群的高可用,协调Kafka的工作内容。 -
相关阅读:
C#(Csharp)我的基础教程(二)(我的菜鸟教程笔记)-属性和字段的探究与学习
安装ora2pg遇到如下问题
latex:使用中文字体
FusionCharts Suite XT v3.19 Crack
CSS 伪类选择器 last-child 和 last-of-type 的区别
vue——组件传值(高级)、属性传值、反向传值、跨级传值
java项目之小说阅读网站(ssm源码+文档)
【网络教程】GitHub搜索技巧大揭秘
3分钟实现EG网关串口连接麦格米特PLC
列表的基础应用
- 原文地址:https://blog.csdn.net/GodBlessYouAndMe/article/details/124898906