©作者 | Doreen
01 介绍
深度学习之所以能在图像分类、自然语言处理等方面取得巨大成功的原因在于大量的训练数据得到了高质量的标注。
然而在一些极其复杂的场景(例如:无人驾驶)中会产生海量的数据,对这些数据进行标注将会产生大量的时间成本和人工成本。
近些年,研究人员提出了active learning, crowd labeling, distant supervision,
semi/weak/self-supervision等方法试图缓解人工标记的工作量。其中,半监督学习 (SSL)是运用最为广泛的一种。
SSL主要运用了两种策略即伪标签(利用模型的预测作为标签来训练模型)和一致性正则化(令模型在经过不同变换后仍能得到相同的预测结果)。
该方法虽然在一定程度上解决了手工标注数据的麻烦,但在标记数据的数量极其有限的情况下,SSL在准确性和鲁棒性上都表现不佳。
为了解决这个问题,研究人员提出了一种基于多选择性(MCL, multiple choice learning)的半监督学习方法DP-SSL(Data Programming Semi-supervised Learning) 对未标记的数据自动生成概率标签,大大提升了图像分类的准确率和鲁棒性。
02 相关工作
多选择性学习(MCL)主要用来提升模型的多样性,但在实际训练过程中,MCL容易让模型处于over-confident状态,导致最终的预测结果不优。
为了解决这个问题,部分研究人员强迫非特定模型的预测结果满足均匀分布,然后对多样化的输出求和得到最终的预测。
半监督学习(SSL)已经被广泛应用于图像分类,目标检测和语义分割中。在图像分类领域,SSL主要通过伪标签或一致性正则化来解决标记样本较少的情况。例如FixMatch将两者简单地结合起来,采用无监督学习和聚类方式给未标记的目标打上了伪标签。
数据编程(Data Programming)是一种弱监督范式,从标签函数产生的各类带噪声标签中获取相关知识从而推断出正确的标签。利用该方法可以自动生成一些概率标签。
虽然以上三种方法都能很好地处理未标记的样本,但在标记样本较少的情况下,仅靠其中任何一种方法都不能得到准确的预测结果。
03 流程图及代码注释
为了解决现存方法的缺陷,作者首次提出了将MCL、SSL和DP结合起来的DP-SSL,其结构如图1所示。
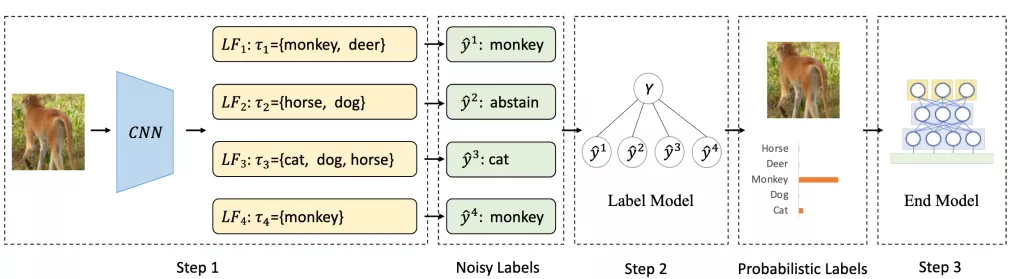
图1 DP-SSL结构图
(图片来自论文:DP-SSL: Towards Robust Semi-supervised Learning with A Few Labeled Samples. https://arxiv.org/abs/2110.13740)
1、建立标签函数
建立标签函数的目的是为未标记的图像生成带有噪声的标签。现有的标签是基于图像不可知(image-agnostic)知识和预训练模型生成的,这类标签很难清楚地描述图像分类的规则。
为了改进这类标签,作者将MCL和SSL结合起来,利用MCL为每个标签函数生成特定的集合,使其在标记样本数量较少的情况下也能通过SSL区分出来。
如图1所示,首先利用一个Wide ResNet模型提取图像特征,生成多个标签函数。然后将图像特征经过特定的变换(如公式(1)所示)送入每个标签函数中。
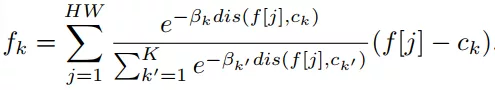
(1)
其中,k是标签函数的个数,
f[j]是空间位置下的特征向量,
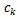
:是第k个标签函数的聚类中心,
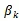
:是第k个聚类中心的变量,
为了提高标签函数的多样性,作者对传统的MCL方法进行了改进,在反向传播的过程中增加了特定标签函数的比例,其损失函数如公式(2)所示。
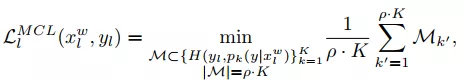
(2)
公式(2)中
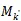
:是集合M的第K个元素,
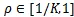
:表示特定标签函数的比例。
经过MCL方法后,每个标签函数对应于一个特定的分类,因此在这些特定范围内的样本能被准确地分类。
但在实际情况下,有些样本不在特定范围内,会因为模型的over-confidence导致分类错误。
针对这个问题,作者允许每个标签函数放弃样本中的某些不确定分类,并将其作为abstention label,此时对已标记图像进行分类的目标函数可改写为公式(3)。
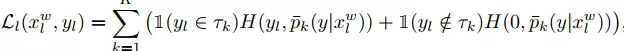
(3)
对于未标记的图像,结合FixMatch模型的相关策略,将数据进行弱增广后用伪标签进行监督学习,此时的目标函数为公式(4)。

(4)
综合以上三种情况,模型的目标函数可以进一步改写为公式(5)。

(5)
公式(5)中的
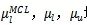
均为超参数。
作者将三者初始化为

当
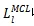
收敛后将其调整为

2、搭建标签模型
为了在源标签和带噪声的标签混合后的情况下进行预测,作者假设K个标签函数都是相互独立的,

:是K个标签函数的预测值的向量形式,
标签模型的联合分布可以用公式(6)描述。
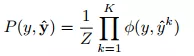
(6)
式中,Z是联合分布的归一化值,由公式(7)表示;φ是目标和伪标签的耦合量,可由公式(8)表示。
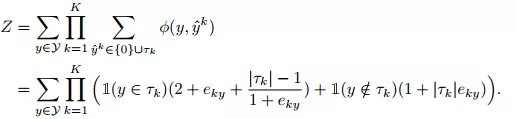
(7)

(8)
其中
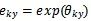
,
y是目标,
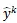
是第个伪标签,
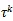
是第个标签函数所包含的类别。
标签模型的目标函数用SSL方式可表示为公式(9)。函数的第一部分是交叉熵损失,第二部分是伪标签的log边际似然函数,第三部分是正则化值。
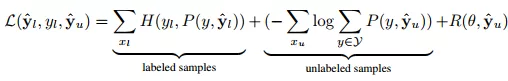
(9)
3、预测标签函数的准确性并建立最终的目标函数
确定了图像属于哪一类标签函数后,接着需要验证目标属于标签函数中的哪一个类别。
作者将待分类的标签设为

(表示目标属于标签函数的第i类;
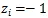
表示目标不属于标签函数的第i类)。
同时,作者将属于第k个标签函数的带噪声标签
设为,
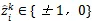
具体表示如公式(10)所示。
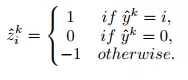
(10)
通过计算
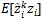
即可估计每个标签函数的正确率。
利用标签函数生成了伪标签后可以将这些概率标签送入末端模型进行训练,从而得到目标图像的分类。
此处,作者利用噪声感知的经验风险预期模型作为目标函数,如公式(11)所示。
其中,
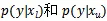
分别是标记图像和未标记图像的概率分布,
n是标签模型输出结果的分布。
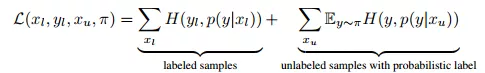
(11)
04 实验
作者采用了CIFAR-10、CIFAR-100和SVHN这三个公开数据集。
前两者包含了50000个训练样本,10000个验证样本,所有图像的尺寸均为32*32,分别分成了10类和100类。
SVHN包含了训练集、测试集和其他集的图像数量分别为73257,26032和531131,其图像质量与CIFAR-10相同。
文中将DP-SSL与现有的半监督学习方法(Π-Model, Pseudo-Labeling,Mean Teacher, MixMatch, UDA, ReMixMatch, FixMatch, USADTM)在这三个数据集上进行了对比,误差率如表1所示。

表1 不同算法在CIFAR-10, CIFAR-100,SVHN数据集上的误差率(其中CIFAR-10和SVHN数据集都采用了Wide ResNet-28-2的网络架构,CIFAR-100采用了WRN-28-8的网络架构。
表格来自论文:DP-SSL: Towards Robust Semi-supervised Learning with A Few Labeled Samples. https://arxiv.org/abs/2110.13740)
从表1 可以看出,DP-SSL在大多数情况下的误差率较低,尤其在每类仅有4个标记样本的情况下误差率最低。
对于CIFAR-100数据集,DP-SSL在2500和10000这两种标记样本数量的情况下,虽然误差率较低,但标准差相对较高,可能是由于标签函数准确率的估计误差导致的。
为了验证DP-SSL的标签质量,作者采用了Precision, Recall, FI score, Coverage这四个指标,结果如表2所示。
从表2中可以看出,DP-SSL给99%以上未标记的图像都打上了概率标签,且在三个数据集上的FI score均高于Majority Vote FlyingSquid方法。

表2 利用macro Precision, Recall, FI score, Coverage四个指标验证不同方法在CIFAR-10, CIFAR-100,SVHN数据集上的标签质量
(表格来自论文:DP-SSL: Towards Robust Semi-supervised Learning with A Few Labeled Samples. https://arxiv.org/abs/2110.13740)
05 结论
作者将SSL、MCL、DP三种方法结合起来,提出了一种新的半监督学习方法DP-SSL对未标记的样本打上较准确的标签用于图像分类。
首先作者采用改进的MCL生成了多个种类的标签函数,然后设计了一个有效的标签模型使其能预测带噪声的标签属于哪一个标签函数,并通过合适的目标函数评价了标签函数的准确性。
利用该标签模型可以解决由标签函数生成的带噪声的标签之间的相互重叠和冲突问题。最后以标签模型生成的概率标签作为监督学习的依据对未标记的图像进行分类。
通过在CIFAR-10、CIFAR-100和SVHN这三个数据集上与现有方法的对比实验,DP-SSL不仅可以自动对99%以上未标记的图像打上概率标签,而且在图像分类上的准确性优于现有的方法。
参考文献
[1] DP-SSL: Towards Robust Semi-supervised Learning with A Few Labeled Samples. https://arxiv.org/abs/2110.13740