论文信息
论文标题:Deep Graph Clustering via Dual Correlation Reduction
论文作者:Yue Liu, Wenxuan Tu, Sihang Zhou, Xinwang Liu, Linxuan Song, Xihong Yang, En Zhu
论文来源:2022, AAAI
论文地址:download
论文代码:download
1 介绍
表示崩塌问题:倾向于将所有数据映射到相同表示。
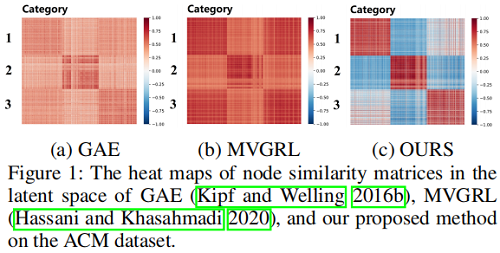
创新点:提出使用表示相关性来解决表示坍塌的问题。
2 方法
2.1 整体框架
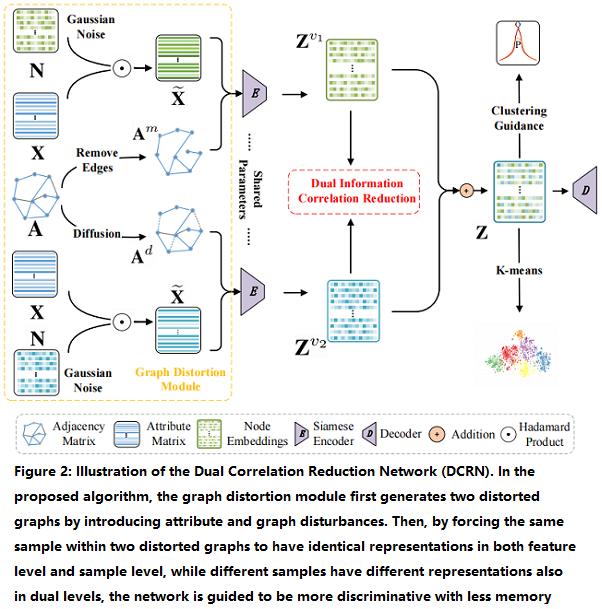
该框架包括两个模块:
-
- a graph distortion module;
- a dual information correlation reduction (DICR) module;
2.2 相关定义

˜A=D−1(A+I)and˜A∈RN×N
2.3 Graph Distortion Module
Feature Corruption:
首先从高斯分布矩阵 N(1,0.1) 采样一个随机噪声矩阵 N∈RN×D,然后得到破坏后的属性矩阵 ˜X∈RN×D :
˜X=X⊙N(1)
Edge Perturbation:
- similarity-based edge removing
根据表示的余弦相似性先计算一个相似性矩阵,然后根据相似性矩阵种的值小于 0.1 将其置 0 来构造掩码矩阵(masked matrix)M∈RN×N。对采用掩码矩阵处理的邻接矩阵做标准化:
Am=D−12((A⊙M)+I)D−12(2)
- graph diffusion
Ad=α(I−(1−α)(D−12(A+I)D−12))−1(3)
2.4 Dual Information Correlation Reduction
框架如下:
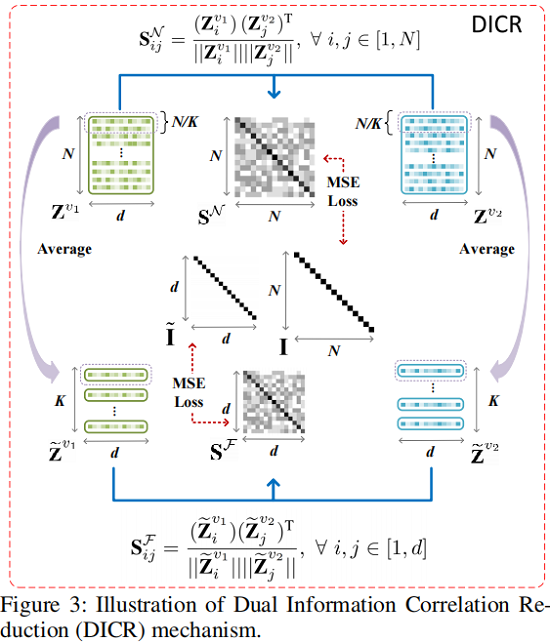
Sample-level Correlation Reduction
对于由 siamese graph encoder 学习到的双视图节点嵌入 Zv1 和 Zv2,我们首先通过以下方法计算交叉视图样本相关性矩阵SN∈RN×N :
SNij=(Zv1i)(Zv2j)T‖Zv1i‖‖Zv2j‖,∀i,j∈[1,N](4)
其中:SNij∈[−1,1] 表示第一个视图中第 i 个节点嵌入与第二个视图中第 j 个节点嵌入的余弦相似度。
然后利用 SN 计算:
LN=1N2N∑(SN−I)2=1NN∑i=1(SNii−1)2+1N2−NN∑i=1∑j≠i(SNij)2(5)
LN 的第一项鼓励 SN 中的对角线元素等于 1,这表明希望两个视图的节点表示一致性高。第二项使 SN 中的非对角线元素等于 0,以最小化在两个视图中不同节点的嵌入之间的一致性。
Feature-level Correlation Reduction
首先,我们使用读出函数 R(⋅):Rd×N→Rd×K 将双视图节点嵌入 Zv1 和 Zv2 分别投影到 ˜Zv1 和 ˜Zv2∈Rd×K 中,该过程公式化为:
˜Zvk=R((Zvk)T)(6)
同样此时计算 ˜Zv1 和 ˜Zv2 之间的相似性:
SFij=(˜Zv1i)(˜Zv2j)T‖˜Zv1i‖‖˜Zv2j‖,∀i,j∈[1,d](7)
然后利用 SF 计算:
LF=1d2S∑(SF−˜I)2=1d2d∑i=1(SFii−1)2+1d2−dd∑i=1∑j≠i(SFij)2(8)
下一步将两个视图的表示合并得:
Z=12(Zv1+Zv2)(9)
上述所提出的 DICR 机制从样本视角和特征水平的角度都考虑了相关性的降低。这样,可以过滤冗余特征,在潜在空间中保留更明显的特征,从而学习有意义的表示,避免崩溃,提高聚类性能。
为了缓解网络训练过程中出现的过平滑现象,我们引入了一种传播正则化方法,即:
LR=JSD(Z,˜AZ)(10)
综上 DICR ,模块的目标函数为:
LDICR=LN+LF+γLR(11)
2.5 目标函数
总损失函数如下:
L=LDICR+LREC+λLKL(12)
分别代表着 DICR的损失LDICR、重建损失LREC 和聚类损失 LKL。
后面两个损失参考 DFCN。
【我本文认为它这个相关性的方法存在不合理之处,没考虑邻居节点,本文之所以有效,也许可能正是它后面加了一个自表达模型】
3 实验
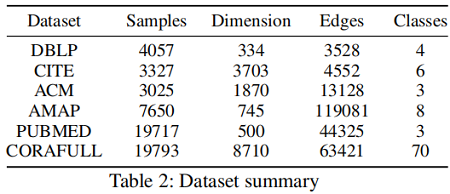
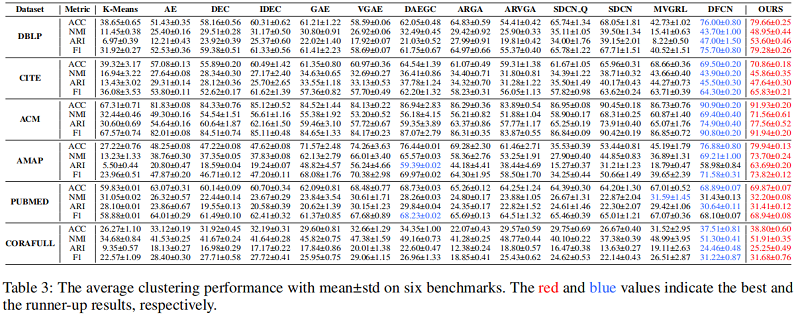
数据集:
基线实验:
4 结论
在这项工作中,我们提出了一种新的自监督深度图聚类网络,称为双相关减少网络(DCRN)。在我们的模型中,引入了一种精心设计的双信息相关减少机制来降低样本和特征水平上的信息相关性。利用这种机制,可以过滤掉两个视图中潜在变量的冗余信息,可以很好地保留两个视图的更鉴别特征。它在避免表示崩溃以实现更好的聚类方面起着重要的作用。在6个基准测试上的实验结果证明了DCRN的优越性。
__EOF__
