论文信息
论文标题:Iterative Graph Self-Distillation
论文作者:Hanlin Zhang, Shuai Lin, Weiyang Liu, Pan Zhou, Jian Tang, Xiaodan Liang, Eric P. Xing
论文来源:2021, ICLR
论文地址:download
论文代码:download
1 Introduction
创新点:图级对比。
2 Method
整体框架如下:
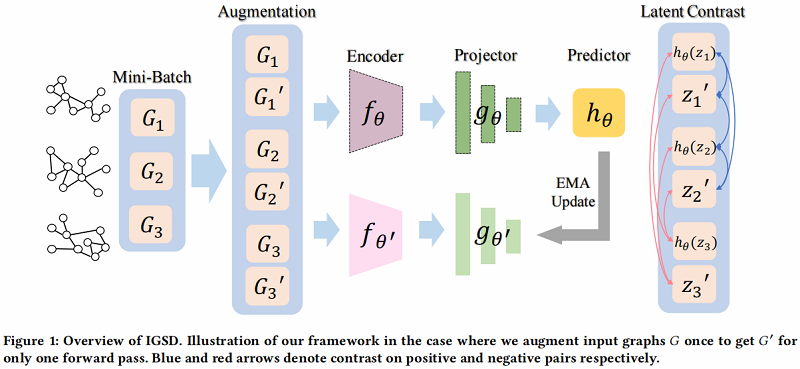
2.1 Iterative Graph Self-Distillation Framework
在 IGSD 中,引入了一个结构相似的两个网络,由 encoder 、projector 和 predictor 组成。我们将教师网络和学生网络的组成部分分别表示为 、 和 、、
IGSD 过程描述如下:
-
- 首先对原始输入图 进行扩充,以获得增广视图 。然后将 和不同的图实例 分别输入到两个编码器 、 中,用于提取图表示 ;
- 其次,投影头 , 通过 和 转换图表示 到投影 ,,其中 表示ReLU非线性;
- 最后,为防止崩溃为一个平凡的解,在学生网络中使用预测头来获得投影 的预测 ;
通过对称传递两个图实列 和 ,可以得到总体一致性损失:
在一致性损失的情况下,teacher network 提供了一个回归目标来训练 student network,在通过梯度下降更新 student network 的权值后,将其参数 更新为学生参数 的指数移动平均值(EMA):
2.2 Self-supervised Learning with IGSD
给定一组无标记图 ,我们的目标是学习每个图 的低维表示,有利于下游任务,如图分类。
在 IGSD 中,为了对比锚定 与其他图实例(即负样本),使用以下自监督的 InfoNCE 目标:
其中, 。
我们通过用混合函数 :融合潜在表示 和 ,得到图表示 :
2.3 Semi-supervised Learning with IGSD
考虑一个整个数据集 由标记数据 和未标记数据 (通常 ),我们的目标是学习一个模型,可以对不可见图的图标签进行预测。生成 个增强视图,我们得到了 和 作为我们的训练数据。
为了弥合自监督的预训练和下游任务之间的差距,我们将我们的模型扩展到半监督设置。在这种情况下,可以直接插入自监督损失作为表示学习的正则化器。然而,局限于标准监督学习的实例性监督可能会导致有偏的负抽样问题。为解决这一问题,我们可以使用少量的标记数据来进一步推广相似性损失,以处理属于同一类的任意数量的正样本:
其中, 表示训练集中与锚点 具有相同标签 的样本总数。由于IGSD的图级对比性质,我们能够缓解带有监督对比损失的有偏负抽样问题,这是至关重要的,但在大多数 context-instance 对比学习模型中无法实现,因为子图通常很难给其分配标签。此外,有了这种损失,我们就能够使用自我训练来有效地调整我们的模型,其中伪标签被迭代地分配给未标记的数据。
对于交叉熵或均方误差 ,总体目标可以总结为:
3 Experiments
节点分类
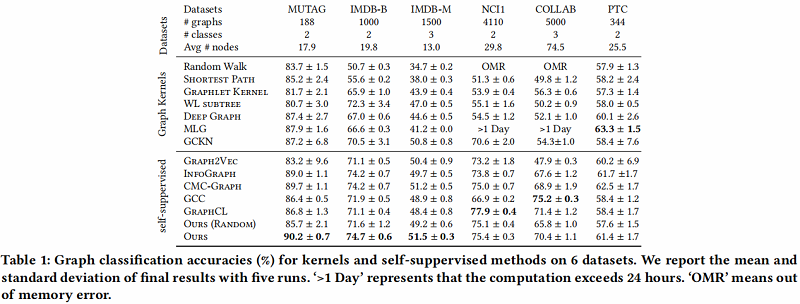
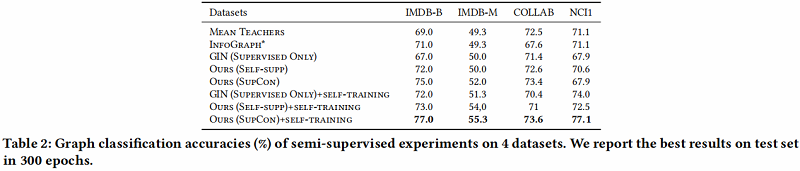
3 Conclusions
在本文中,我们提出了一种新的基于自蒸馏的图级表示学习框架IGSD。我们的框架通过对图实例的增强视图的实例识别,迭代地执行师生精馏。在自监督和半监督设置下的实验结果表明,IGSD不仅能够学习与最先进的模型竞争的表达性图表示,而且对不同的编码器和增强策略的选择也有效。在未来,我们计划将我们的框架应用到其他的图形学习任务中,并研究视图生成器的设计,以自动生成有效的视图。
__EOF__
