-
利用熵权法进行数值评分计算——算法过程
1、概述
在软件系统中,研发人员常常遇上需要对系统内的某种行为/模型进行评分的情况。例如根据系统的各种漏洞情况对系统安全性进行评分、根据业务员最近操作系统的情况对业务员工作状态进行打分等等。显然研发人员了解一种或者几种标准评分算法是非常有利于开展研发工作的。
目前流行的评分方法有很多种,诸如wilson评分算法、模糊综合评价法、秩和比评分法等等,本文内容介绍一种容易理解和编码实现的评分算法——熵权评分法。熵权法是一种基于信息论的方法,其核心在于通过计算数据中的熵来评估数据的不确定性。在信息论中,熵是衡量信息不确定性的一个重要指标。当数据集合中的概率分布更加均匀时,信息熵较大,表示数据的不确定性较高;反之,当概率分布更加集中时,信息熵较小,表示数据的不确定性较低。
2、计算过程
本文通过一个给员工工作状态评分的示例,介绍熵权法在实际工作中的使用。这个示例中本文不但演示熵权法的每个计算步骤,还通过一个Excel表格对每个计算步骤进行演练。这个示例的背景是,某公司针对员工的工作状态进行打分,这些打分要素包括了“迟到次数”、“食物带入办公区次数”、“遗忘打卡次数”、“下班后电脑未关次数”、“上厕所次数”、“计件质检评分”。
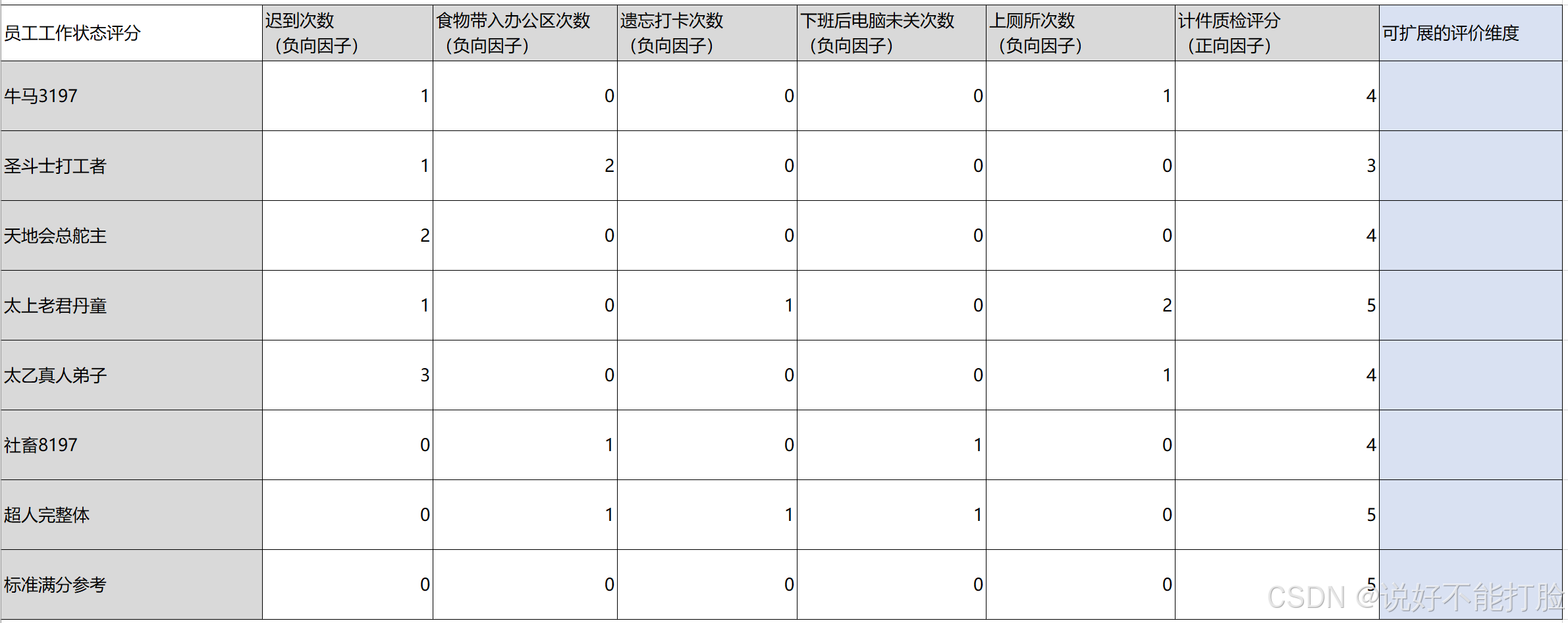
需要说明的是,熵权法进行编码实现时可以支持对评价维度的扩展。也就是说评价维度的多少并不影响计算步骤,只对某些步骤的计算数值产生影响。2.1、进行数据标准化
评分指标分为正向指标(正向因子)和负向指标(负向因子)。正向指标是指该数据分值越高,对最后的评分结果影响越正面,例如电视的尺寸数据在电视综合评分中就是一个正向数据——尺寸越大综合评分越高;负向指标是指该数据分值越高,对最后的评分结果影响越负面,例如在网络安全评分场景下,某台终端端口被扫描的次数越多,则终端安全性得分越低。因为评分数据有正向和负向之分,所以评分计算的第一步是将各个评分要素进行标准化处理。处理公式如下所示:

如上图所示,正向指标和负向指标的数据标准化公式是不一样的,正向指标进行数据标准化的公式可以解释为:从各个评分参与者的正向指标中,取得得分最高的值和得分最低的值,相减后最为分母;使用当前要进行标准化的值,减去得分最低的值,作为分子;以下为计算结果: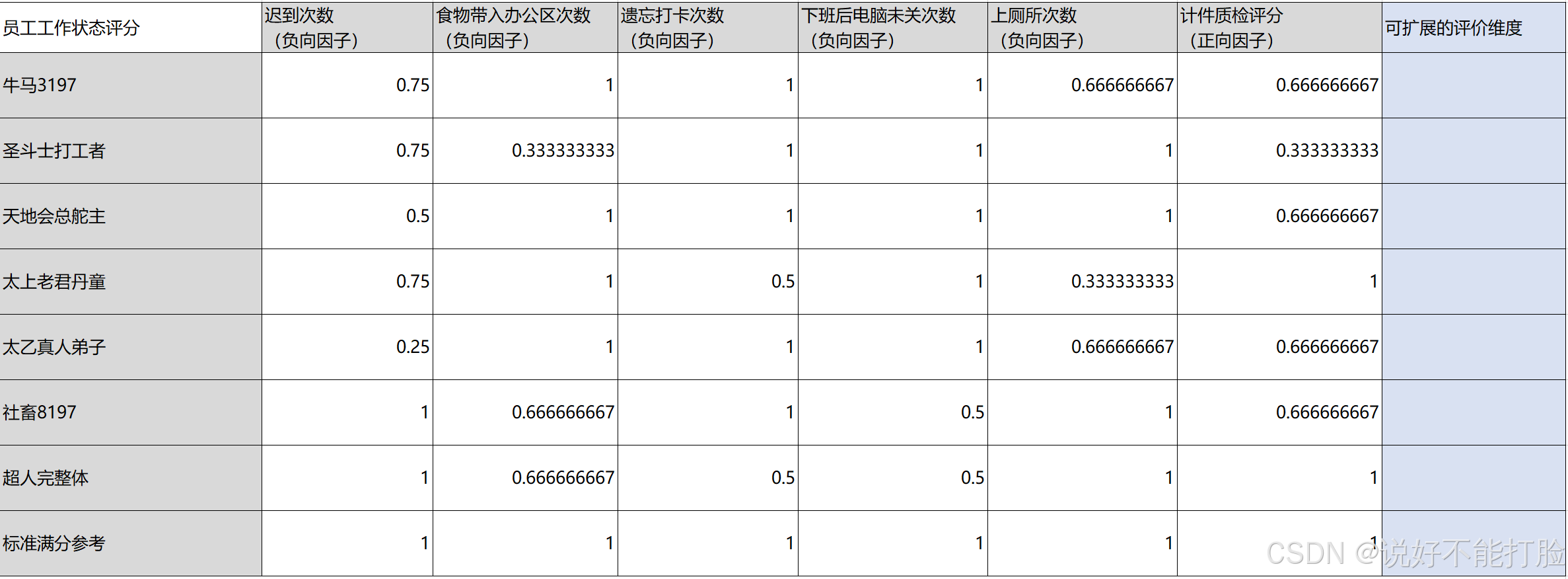
以上图中的迟到次数为例,由于迟到次数是一个负向指标,所以“社畜8197”的迟到次数标准化的计算方式就是:分母为最大得分3 减去 最小得分1;分子为最大得分3 减去 “社畜8197”的次数0,得到结果为1。
另外要说明的是,由于是取得各个分母是各个参与者中的最大值,减去各个参与者中的最小值,所以当最大值和最小值为一样时,分母就可能为0;所以在进行标准化计算时,可以通过分母分子同时+1的方式,修正这种极端情况下的问题。以下是Excel使用的计算公式,可以看到分子分母都加了“1”:

2.2、求每个数值在评分列中的数值占比(数值比例)
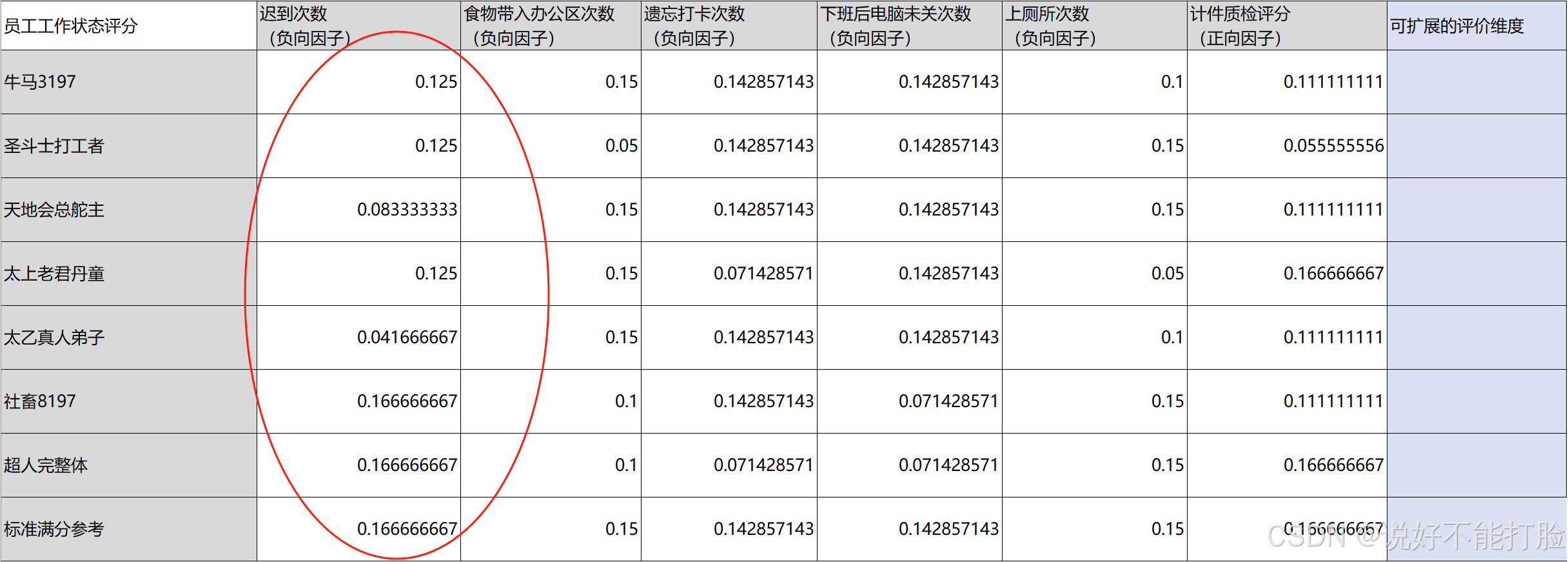
还是以“迟到次数”这个负向指标为例,上一步我们求得了每个参与者“迟到次数”的数据标准值,分别为0.75、0.75、0.5、0.75、0.25、1、1、1;下面我们求每一个数值的数值占比,公式为:

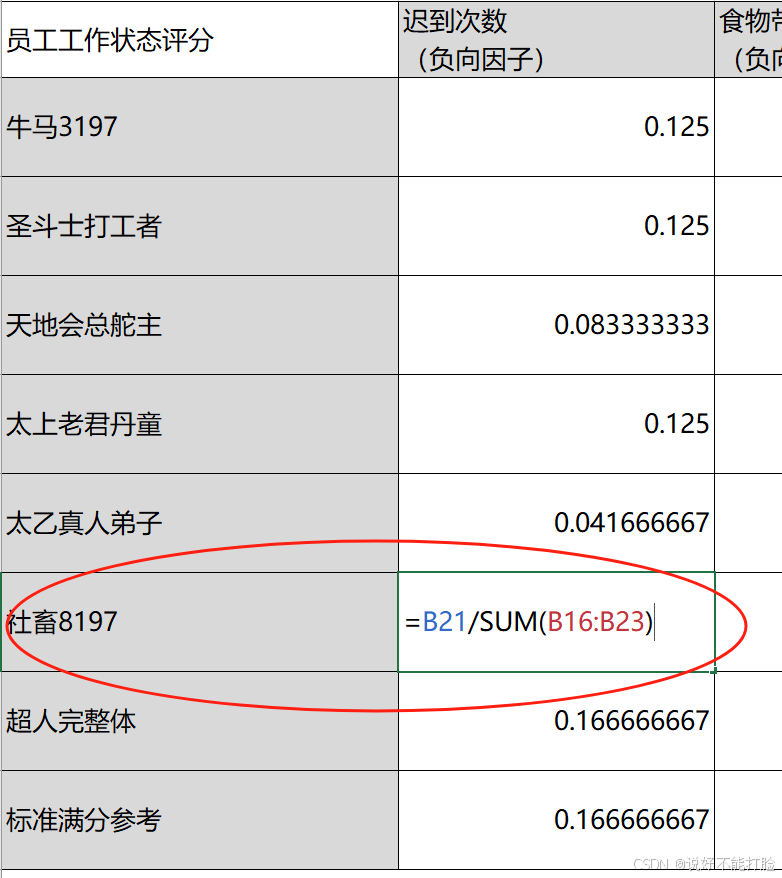
这个公式很好理解,分母就是所有评分参与者的“迟到次数”数据标准值的和;分子就是某个具体的某个“迟到次数”的标准值。所以求得的数据如下表所示:
使用Excel文件进行计算过程演练时,可以使用以下公式进行表达:
2.3、求数值占比与自身(数值占比)对数的积
上一步我们计算出了每一个评分参与者在“迟到次数”这个要素上的数值占比,分别是0.125、0.125、0.0833333、0.125…… 。接下来我们就每个数和自身对数(以2为底)的积。熵权法要求对数的原因在于对数函数能够有效地衡量数据的不确定性,并确保信息的可加性。
X i = P i L o g ( P i ) X_i = P_i Log(P_i) Xi=PiLog(Pi)

使用Excel文件进行计算过程演练时,可以使用以下公式进行表达:

这个数值将在下一步正式进行熵值计算时,起到关键作用。
2.4、计算每个评分要素的熵值
现在我们开始正式计算每个参与评分的要素的熵值。在本示例中,这些要素分别就是“迟到次数”、“食物带入办公区次数”、“遗忘打卡次数”、“未关电脑次数”等等。熵值的计算公式如下:

这个公式分为两部分进行理解,其中第一部分就是K值的定义:
K = 1 / L o g ( N ) K = 1 / Log(N) K=1/Log(N)
其中N为参与评分的参与者数量,这个示例中N的值就是8(“牛马3197”、“圣斗士打工者”、“天地会总舵主”、“太上老君丹童”……)。这个公式的第二部分就是“西格玛符号”(∑)描述的求和部分,刚好是对我们2.3小节得到的每个栏目的值进行的求和。所以通过以上公式,我们能得到的计算结果如下图所示:

同样使用Excel文件进行计算过程演练,可以使用以下公式进行表达:

其中公式中“B37到B44”的值,就是2.3小节中每一个“迟到次数”通过求对数得到的值。
2.5、计算每个评分要素的权重值
现在我们有了每个评分要素的熵值,基于熵值我们可以求得每个平分要素的权重值——实际上这里的权重值可以理解为每个评分要素的熵值在整个熵值体系中的占比,其公式为:

其中分母为所有要素熵值的累加(d代表每一个要素的熵值),分子为当前要素的熵值。计算过程的演练表格如下所示: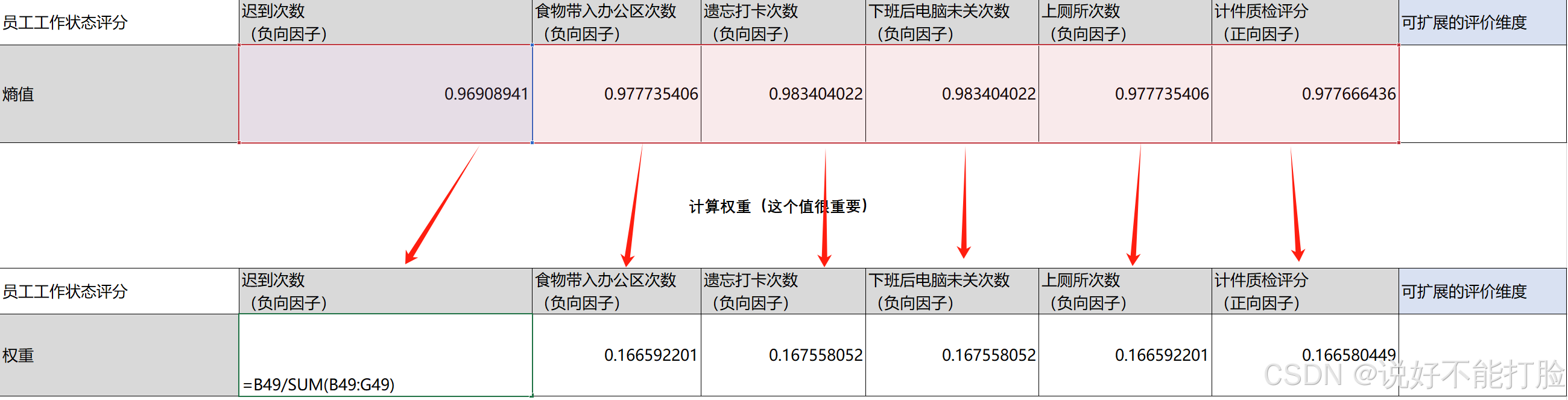
2.6、基于权重值转换为10分制/100分制/或者N分制
有了每个评分要素的权重值(基于熵值得出),以及每个评分栏目标准化值(本文2.1小节所描述),就可以进行每个参与者的评分了——这个评分不能是10分制或者100分制或者1000分制的,而是一个得分基数。最后操作者可以根据这个得分基数,转换成自己所需的10分制或者100分制得分——最终用户可以看懂的得分。
得分基数的计算公式为:
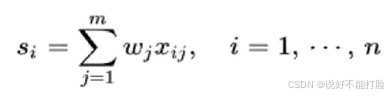
公式是一个西格玛(∑)求和公式,其中每一个从1到m的w值,代表每一个评分要素的值;每一个x的值,代表每一个平分栏目。如果不好理解,可以看下图的解释
可以看到每个评分参与者的得分分别是:“牛马3197”——0.847662689、“圣斗士打工者”——0.736605139、“天地会总舵主”——0.861913661、“太上老君丹童”——0.763879745、“太乙真人弟子”——0.765103166、“社畜8197”——0.805163424、“超人完整体”——0.776911214、“标准满分参考”——1;
但是最终用户是看不懂这些得分基数的,所以需要一些形式上的计算过程,将基准评分转换为10分制、100分制或者某种最终用户能看懂的分数,如下所示:

E x c e l 栏目公式 = 100 / R O U N D U P ( M A X ( I 56 : I 62 ) , 3 ) ∗ I 56 Excel栏目公式=100/ROUNDUP(MAX(I56:I62),3)*I56 Excel栏目公式=100/ROUNDUP(MAX(I56:I62),3)∗I56以上评分结果,这只是一个形式主义的计算过程,目的是让最终使用者根据日常习惯的计分方式对评分结果进行理解。后文我们将介绍熵权法的编码实现过程。
-
相关阅读:
20_数组的常见操作
Vue3理解(9)
如何在 uniapp 里面使用 pinia 数据持久化 (pinia-plugin-persistedstate)
【考研数学】数学一“背诵”手册(一)| 高数部分(2)
基于springboot实现4S店车辆管理系统项目【项目源码+论文说明】
java基于springboot+vue的校园闲置二手物品交易系统 跳蚤市场 element
Google DataFlow入门与(Pub/Sub-DataFlow-BigQuery解决方案)
含文档+PPT+源码等]精品基于SSM的校园二手交易平台[包运行成功]程序设计源码计算机毕设
【数据结构】归并排序、基数排序算法的学习知识点总结
什么是开源?为什么要坚持开源?
- 原文地址:https://blog.csdn.net/yinwenjie/article/details/142012545