-
Redis 缓存预热、缓存雪崩、缓存击穿、缓存穿透业务实践
0、前言
本文所有代码可见 => 【gitee code demo】
本文会涉及 缓存预热、缓存雪崩、缓存击穿、缓存穿透介绍和解决方案业务实践1、缓存预热
1.1、描述
提前将热点数据加载到缓存,提前响应,降低后端数据源访问压力
1.2、实践
@Autowired private RedisTemplate<String, Object> redisTemplate; // 业务 public void bizFunc(String[] args) { // 预热缓存 warmUpCache(); // 使用缓存 String value = getFromCache("key1"); System.out.println("从缓存中获取的值:" + value); } // 模拟缓存预热 public void warmUpCache() { redisTemplate.opsForValue().set("key1", "value1"); redisTemplate.opsForValue().set("key2", "value2"); redisTemplate.opsForValue().set("key3", "value3"); } public String getFromCache(String key) { return (String) redisTemplate.opsForValue().get(key); }2、缓存雪崩
2.1、描述
同一时间大规模的缓存失效
常见原因:
- 服务器宕机
- 同一时刻,缓存大面积失效
2.2、解决方案
- 使用集群防止单点故障
- 对缓存key的过期时间进行随机化处理
- 服务降级
2.3、实践:过期时间随机化处理
/** * 设置缓存key的过期时间并进行随机化处理 * @param key 缓存key * @param value 缓存value */ public void setWithRandomExpire(String key, Object value) { // 生成一个随机的过期时间,范围在[240, 300]s之间 long randomExpireTime = ThreadLocalRandom.current().nextLong(60) + 240; redisTemplate.opsForValue().set(key, value, randomExpireTime, TimeUnit.SECONDS); }3、缓存击穿
3.1、描述
热点数据过期失效,导致数据库压力骤增
3.2、解决方案
- 差异失效时间(双缓存)
- 双检加锁
3.3、实践1:差异失效时间(双缓存)



3.4、实践2:双检加锁
缓存失效时,对查询MySQL加锁,只有一个线程能查MySQL,防止MySQL压力过大

4、缓存穿透(本来无一物)
4.1、描述
缓存和数据库中都不存在数据,请求每次都会直接到数据库
4.2、解决方案
- 缓存空结果
将空结果缓存起来,并设置一个较短的过期时间。这样当再次有相同的查询时,可以直接在缓存中获取到结果,减轻数据库的压力
- 布隆过滤器
过滤不可能存在的请求
4.3、实践:Guava布隆过滤器
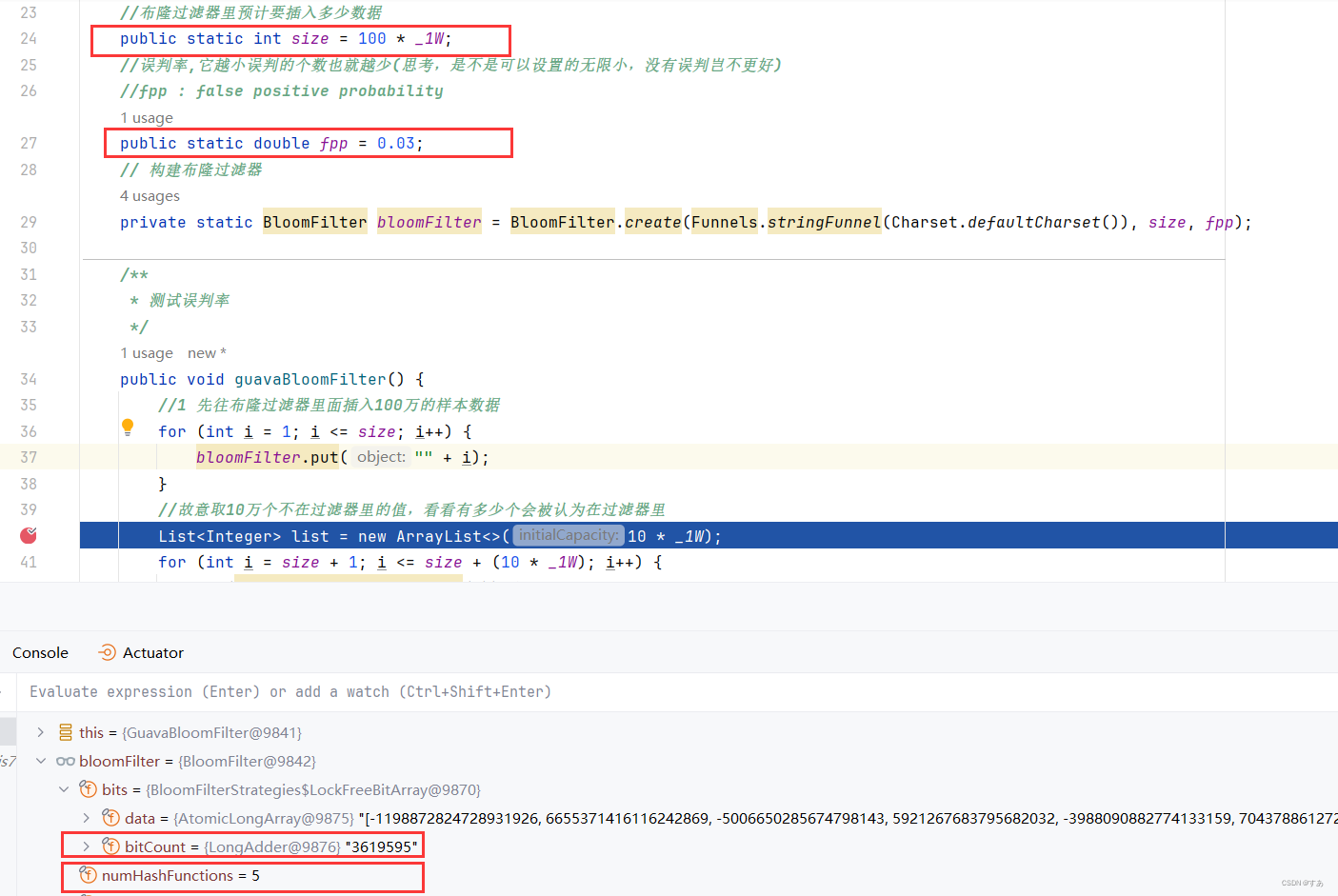
4.3.1、Guava布隆过滤器原理
在预期插入的数据量和误判率一定时,可以通过调整这些参数来控制内存的使用。例如:
-
如果想要降低误判率,就需要增加位数组的大小或使用更多的哈希函数,这会相应地增加内存的使用。
-
误判率越低,所需的位数组越长,占用的空间也就越大。
-
更多的哈希函数会增加计算的耗时,但也会降低误判率。
4.3.2、实践
过滤器业务流程

过滤器业务代码

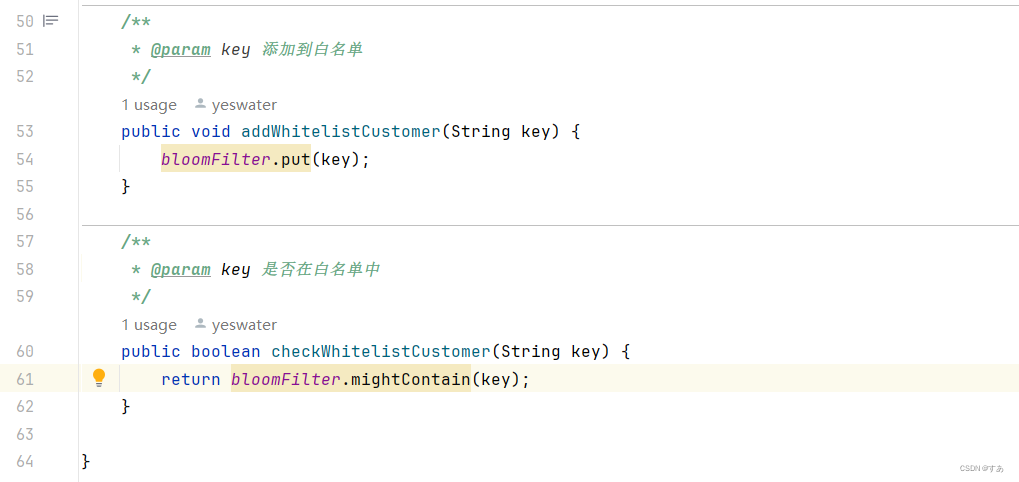
布隆过滤器封装
-
相关阅读:
查看日志.
【QandA C++】面向过程、面向对象、多态的原理、虚函数表、虚表指针、虚析构、虚构造、虚函数、纯虚函数等重点知识汇总
从零点五开始的深度学习笔记——VAE(Variational AutoEncoder) (一) 预备知识
Python爬虫程序网络请求及内容解析
如何保证Redis和MySQL两者之间数据的一致性
记一次dubbo消费者注册失败找不到服务提供者问题
解决六大痛点促进企业更好使用生成式AI,亚马逊云科技顾凡采访分享可用方案
CROS错误 403 preflight 预检
Linux 解决wine启动winedows程序无法显示中文
【C++编程语言】之函数的默认参数,占位参数,函数重载
- 原文地址:https://blog.csdn.net/weixin_44296614/article/details/140054646
{kind=link}
{kind=link}