-
【数学建模】——【python库】——【Pandas学习】


专栏:数学建模学习笔记
pycharm专业版免费激活教程见资源,私信我给你发
python相关库的安装:pandas,numpy,matplotlib,statsmodels
第一卷:【数学建模】—【Python库】—【Numpy】—【学习】
本篇属于第二卷——Pandas学习笔记
步骤1:安装PyCharm和Pandas
1.下载并安装PyCharm:
- 前往JetBrains官网,下载并安装PyCharm Community Edition(免费)或Professional Edition。
- 安装完成后,启动PyCharm。
2.安装Pandas库:
- 打开PyCharm,新建一个项目。
在项目窗口中,找到Terminal(终端)窗口,输入以下命令安装Pandas库:
pip install pandas步骤2:创建并读取数据
1.创建数据文件:
- 在项目根目录下创建一个名为
data.csv的文件,输入一些示例数据。例如: -
Name
Age
Score
Alice
23
88
Bob
25
92
Charlie
22
85
Xiaoli
18
100

2.读取数据:
- 在项目中创建一个新的Python文件,例如 Pandas学习.py。
在Pandas学习.py中编写以下代码来读取数据 :
- import pandas as pd
- # 读取CSV文件
- data = pd.read_csv('data.csv')
- # 打印数据
- print(data)
点击右上角的绿色运行按钮,或使用快捷键Shift+F10:

步骤3:数据清洗和处理
3.1 处理缺失值
假设我们的数据有缺失值,可以用以下代码来处理:
修改
data.csv文件,加入一些缺失值:Name,Age,Score Alice,23,88 Bob,25, Charlie,,85 David,22,90 xiaoli,18,100
在Pandas学习
.py中编写以下代码:- import pandas as pd
- # 读取CSV文件
- data_with_nan = pd.read_csv('data.csv')
- print("原始数据带有缺失值:")
- print(data_with_nan)
- # 用平均值填充缺失的年龄
- data_with_nan['Age'].fillna(data_with_nan['Age'].mean(), inplace=True)
- # 用指定值填充缺失的分数
- data_with_nan['Score'].fillna(0, inplace=True)
- print("\n处理后的数据:")
- print(data_with_nan)
运行此代码,您将看到以下输出:

3.2 数据转换
假设我们需要将年龄从岁转换为月,可以用以下代码:
在Pandas学习
.py中添加以下代码:- data_with_nan['Age_in_Months'] = data_with_nan['Age'] * 12
- print("\n添加年龄(以月为单位)后的数据:")
- print(data_with_nan)
运行此代码,您将看到以下输出:

步骤4:数据分析和可视化
1.数据统计:
- 我们可以使用Pandas提供的统计函数进行简单的数据分析:
- # 计算平均年龄
- mean_age = data['Age'].mean()
- print(f'平均年龄: {mean_age}')
- # 计算分数的标准差
- score_std = data['Score'].std()
- print(f'分数标准差: {score_std}')
运行此代码,您将看到以下输出:
-

2.数据可视化:
虽然你只提到Pandas,但这里简要提及如何使用Matplotlib进行简单可视化:
- import matplotlib.pyplot as plt
- # 绘制年龄分布图
- plt.hist(data['Age'], bins=10, alpha=0.75)
- plt.xlabel('Age')
- plt.ylabel('Frequency')
- plt.title('Age Distribution')
- plt.show()
运行此代码,您将看到一个年龄分布的直方图。

步骤5:高级操作
5.1 数据分组和聚合
使用
groupby函数对数据进行分组和聚合,例如按年龄分组计算平均分数:-
Pandas学习.py中添加以下代码:
- age_grouped = data_with_nan.groupby('Age')['Score'].mean()
- print("\n按年龄分组的平均分数:")
- print(age_grouped)
运行结果

5.2 数据透视表
使用
pivot_table函数创建数据透视表:在
main.py中添加以下代码:- pivot_table = data_with_nan.pivot_table(values='Score', index='Age', columns='Name', aggfunc='mean')
- print("\n数据透视表:")
- print(pivot_table)

步骤6:保存数据
6.1 保存处理后的数据
将处理后的数据保存为新的CSV文件:
在
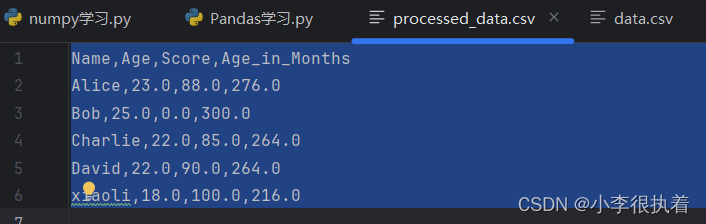
main.py中添加以下代码:data_with_nan.to_csv('processed_data.csv', index=False)运行此代码后,您将在项目目录下看到一个名为
processed_data.csv的新文件,内容如下:
总结
在PyCharm中使用Pandas进行数据读取、清洗、处理、分析和保存,应用Pandas进行环境设置、数据加载、预处理、分析、可视化到简单建模的全过程。欢迎友友的提问指导!
7.进一步细节和注意事项
1.数据质量控制
数据质量控制是数据分析中至关重要的一环。确保数据的准确性和完整性是数据分析成功的基础。以下是一些常见的数据质量控制方法:
-
数据验证:
- 检查数据是否有重复记录,确保每一行数据的唯一性。
- 验证数据范围是否在合理范围内(例如,年龄不应超过100岁)。
-
数据一致性:
- 检查同一字段的数据类型是否一致。
- 确保同一字段的数据格式一致,例如日期格式统一为YYYY-MM-DD。
-
数据完整性:
- 确保关键字段没有缺失值。
- 检查数据表之间的关联性,确保外键关系的完整性。
2.数据处理技巧
1.处理异常值:
异常值是指与大多数数据点明显不同的数据点。处理异常值的方法包括:
删除异常值:如果异常值是由于数据录入错误造成的,可以直接删除。
替换异常值:使用中位数或均值替换异常值。
data_filtered = data[(data['Age'] > 0) & (data['Age'] < 100)]2.数据转换:
数据转换是指将数据从一种形式转换为另一种形式,以便于分析。
例如,可以将分类数据转换为数值数据,使用One-Hot编码:
data['Gender'] = data['Gender'].map({'Male': 1, 'Female': 0})3.数据分析与可视化
高级可视化:
数据可视化能够帮助我们更直观地理解数据。以下是一些常见的数据可视化方法:
箱线图:用于显示数据的分布情况,特别是检测异常值。
- sns.boxplot(x=data['Score'])
- plt.title('Score Boxplot')
- plt.show()
散点图:用于显示两个变量之间的关系。
- sns.scatterplot(x=data['Age'], y=data['Score'])
- plt.title('Age vs Score')
- plt.show()
4.时间序列分析:
- 如果数据包含时间维度,可以进行时间序列分析。
- data['Date'] = pd.to_datetime(data['Date'])
- data.set_index('Date', inplace=True)
- data['Score'].plot()
- plt.title('Score over Time')
- plt.show()
8.更多数据分析与处理细节
1.扩展数据清洗技术
1.去除重复值:
- data_without_duplicates = data.drop_duplicates()
- print("去除重复值后的数据:")
- print(data_without_duplicates)
2.处理异常值:
- # 假设年龄和分数的合理范围
- data_filtered = data[(data['Age'] > 0) & (data['Age'] < 100) & (data['Score'] >= 0) & (data['Score'] <= 100)]
- print("去除异常值后的数据:")
- print(data_filtered)
3.转换数据类型:
- data['Age'] = data['Age'].astype(int)
- data['Score'] = data['Score'].astype(float)
- print("转换数据类型后的数据:")
- print(data.dtypes)
2.详细分析数据
1.更多统计分析:
- # 计算中位数
- median_age = data['Age'].median()
- print(f'年龄中位数: {median_age}')
- # 计算分数的方差
- variance_score = data['Score'].var()
- print(f'分数方差: {variance_score}')
2.高级可视化:
- import seaborn as sns
- # 绘制箱线图
- sns.boxplot(x=data['Score'])
- plt.title('Score Boxplot')
- plt.show()
- # 绘制散点图
- sns.scatterplot(x=data['Age'], y=data['Score'])
- plt.title('Age vs Score')
- plt.show()
9.实战 接单


- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- from matplotlib.font_manager import FontProperties
- # 设置字体
- plt.rcParams['font.sans-serif'] = ['SimSun'] # 设置默认字体为宋体
- plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
- # 读取数据
- file_path = 'E:/python/零食大礼包销售/SuperMarket_order.txt'
- data = pd.read_csv(file_path, sep=',')
- # 按照付款金额分类
- bins = [0, 100, 500, float('inf')]
- labels = ['100以下', '100-500', '500以上']
- data['付款金额分类'] = pd.cut(data['931.79'], bins=bins, labels=labels)
- # 分别对订单状态、物品类别、购物方式、支付类别、付款人所在省份进行统计分析
- status_counts = data['已完成'].value_counts()
- category_counts = data['文体类'].value_counts()
- shopping_method_counts = data['PC'].value_counts()
- payment_type_counts = data['微信'].value_counts()
- province_counts = data['江苏省'].value_counts()
- amount_category_counts = data['付款金额分类'].value_counts()
- # 绘制图表
- fig, axes = plt.subplots(2, 3, figsize=(18, 12))
- # 订单状态统计图
- axes[0, 0].bar(status_counts.index, status_counts.values)
- axes[0, 0].set_title('订单状态统计')
- axes[0, 0].set_xlabel('订单状态')
- axes[0, 0].set_ylabel('数量')
- # 物品类别统计图
- axes[0, 1].bar(category_counts.index, category_counts.values)
- axes[0, 1].set_title('物品类别统计')
- axes[0, 1].set_xlabel('物品类别')
- axes[0, 1].set_ylabel('数量')
- # 购物方式统计图
- axes[0, 2].bar(shopping_method_counts.index, shopping_method_counts.values)
- axes[0, 2].set_title('购物方式统计')
- axes[0, 2].set_xlabel('购物方式')
- axes[0, 2].set_ylabel('数量')
- # 支付类别统计图
- axes[1, 0].pie(payment_type_counts.values, labels=payment_type_counts.index, autopct='%1.1f%%')
- axes[1, 0].set_title('支付类别统计')
- # 付款人所在省份统计图
- axes[1, 1].scatter(province_counts.index, province_counts.values)
- axes[1, 1].set_title('付款人所在省份统计')
- axes[1, 1].set_xlabel('省份')
- axes[1, 1].set_ylabel('数量')
- # 付款金额分类统计图
- axes[1, 2].bar(amount_category_counts.index, amount_category_counts.values)
- axes[1, 2].set_title('付款金额分类统计')
- axes[1, 2].set_xlabel('付款金额分类')
- axes[1, 2].set_ylabel('数量')
- plt.tight_layout()
- plt.show()


10.相关应用
Pandas在实际数据分析中的应用非常广泛,以下是一些常见的应用场景:
1.金融数据分析:
分析股票市场数据,包括股价趋势分析、波动率分析、技术指标计算等。
- stock_data = pd.read_csv('stock_data.csv')
- stock_data['Daily Return'] = stock_data['Close'].pct_change()
- stock_data['Daily Return'].plot()
- plt.title('Daily Return of Stock')
- plt.show()
2.市场营销数据分析:
- 分析客户购买行为,进行客户细分、预测客户价值等。
- sales_data = pd.read_csv('sales_data.csv')
- customer_segments = sales_data.groupby('CustomerID')['PurchaseAmount'].sum()
- customer_segments.plot(kind='bar')
- plt.title('Customer Purchase Amount')
- plt.show()
3.社会科学研究:
分析社会调查数据,包括人口统计分析、社会行为模式分析等。
- survey_data = pd.read_csv('survey_data.csv')
- age_distribution = survey_data['Age'].value_counts()
- age_distribution.plot(kind='pie')
- plt.title('Age Distribution of Survey Respondents')
- plt.show()
11.注意事项
1.数据隐私:
- 在处理个人数据时,确保遵守相关数据隐私法律法规,如GDPR(General Data Protection Regulation)。
- 避免在数据处理中泄露个人敏感信息,使用数据匿名化技术。
2.性能优化:
- 对于大规模数据,使用Pandas可能会导致内存消耗过高。可以考虑使用Dask或Pandas的chunking功能进行分块处理。
- chunk_size = 10000
- chunks = pd.read_csv('large_data.csv', chunksize=chunk_size)
- for chunk in chunks:
- # 处理每个chunk
- process_chunk(chunk)
3.版本兼容性:
- 使用Pandas时,确保使用相同版本的Pandas库,以避免因版本差异导致的代码不兼容问题。
-
相关阅读:
【c++】向webrtc学习容器操作
vscode 编译java不通过缺少jar包.
班级管理小程序开发
基于内存的分布式NoSQL数据库Redis(三)常用命令
java web学习
jvm基础--JVM内存模型
Enzo丨Enzo SAVIEW PLUS AP试剂解决方案
怎么查看当前vue项目,要求的node.js版本
chatGPT马上要支持应用商痁了 个人开发GPT应用赚钱的时代来了 海外淘金GPT4 Turbo版
图书管理系统C语言课程设计
- 原文地址:https://blog.csdn.net/2303_77720864/article/details/140001382