-
浅析MySQL-基础篇01
目录
执行一条select语句,发生了什么?
学习SQL的时候,查询数据的时候简单的用到就是下面的这SQL语句:
select * from tbl_1 where id = 100;有没有想过,MYSQL执行一条select查询语句,在MYSQL中期间发生了什么?
带着这个问题,我们可以很好的理解MYSQL内部的架构,下面我们具体看看内部的流程。
MYSQL执行流程是怎么样的?
下面就是 MySQL 执行一条 SQL 查询语句的流程,也从图中可以看到 MySQL 内部架构里的各个功能模块

MySQL 的架构共分为两层:Server 层和存储引擎层
- Server层负责建立连接、分析和执行SQL
- 存储引擎负责数据的存储和求提取
第一步:连接器
如果你要使用MySQL,那么第一步是要先连接数据库服务,然后才能才能执行SQL语句。
mysql -h$ip -u$user -P$port -p$password连接的过程需要先经过TCP三次握手,因为MySQL是基于TCP协议进行传输。
如何查看MySQL服务当前有多少个客户端连接?
可以执行执行下面的SQL命令进行查看
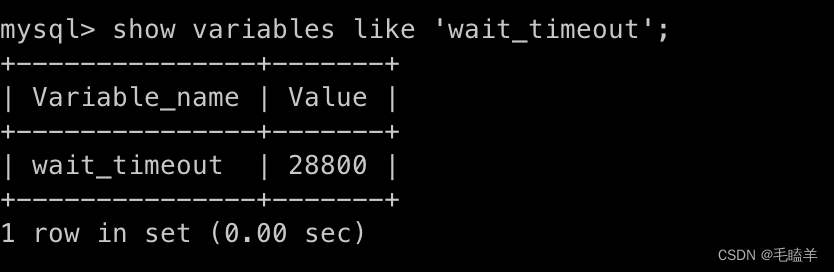
show processlist
上图结果:有两个用户名为root的用户连接了MYSQL服务,其中id为42的用户的Command状态为Sleep,这意味着该用户连接完MSQL服务就没有执行过任何命令,也就是个空闲的连接,空闲时长是81秒
空闲连接会一直占用吗?
不会,MySQL定义了空闲连接的最大空闲时长,由wait_timeout参数控制,默认值是28800秒(8小时),如果空闲连接超过了这个时间,连接器就会自动将它断开。
当然,我们也可以手动断开空闲连接,使用kill connection + id 命令

一个处于空闲状态的连接被服务端主动断开后,这个客户端并不会马上知道,等到客户端再发起下一个请求的时候,才会收到"Lost connection"

MySQL的连接数有限制吗?
MySQL服务支持的最大连接数由max_connections参数控制。默认值是151个,超过这个值,系统就会拒绝接下来的连接请求,并提示报错“Too many connections”。

MySQL的连接也有长连接和短连接的概念,区别如下:
- // 短连接
- 连接 mysql 服务 (TCP 三次握手)
- 执行sql
- 断开 mysql 服务 (TCP 四次挥手)
- // 长连接
- 连接 mysql 服务 (TCP 三次握手)
- 执行sql
- 执行sql
- 执行sql
- ...
- 断开 mysql 服务 (TCP 四次挥手)
可以发现,使用长连接的好处就是可以减少建立连接和断开连接的过程,所以一般推荐使用长连接。
但是长连接后可能会占用内存增多,因为MySQL执行查询过程中临时使用内存管理连接对象,这些连接对象资源只有在连接断开时才会释放。如果长连接累计很多,将导致MySQL服务占用内存太大,有可能会被系统强制杀掉,这样会发生MySQL服务异常重启的现象。
怎么解决长连接占用内存的问题?
两种解决方式:
- 定期断开长连接。
- 客户端主动重置连接。5.7版本实现了mysql_reset_connection() 函数的接口,注意这个事接口函数不是命令,那么客户端执行了一个很大的操作后,在代码里调用此函数来重置连接,达到释放内存的效果。这个过程不需要重连和重新做权限验证,但是会将恢复到刚刚创建完时的状态
数据库连接池简单的实现方式:
GitHub - maokeyang/SimpleDataSourcePool
至此,连接器的工作做完了,简单的总结一下:
- 与客户端发起TCP三次握手建立连接
- 校验客户端的用户名和密码
- 如果校验通过,会读取用户的权限,然后后面的权限逻辑判断都会基于此时读到的权限
第二步:查询缓存
连接器的工作完成以后,客户端可以向MySQL服务发送SQL语句,服务端收到SQL语句后,就会解析SQL语句第一个字段,分析是什么类型的语句
如果SQL语句是查询select语句,MySQL就会先去缓存里查询找数据,看看之前有没有执行过这一条命令。这个缓存是以key-value方式保存在内存中,key为SQL查询语句,value是SQL语句的查询结果。
其实缓存比较鸡肋。
对于更新比较频繁的表,查询缓存的命中率很低。因为只要表有一个更新操作,那么这个表的查询缓存就会被清空。如果刚缓存了一个查询结果很大的数据,还没被使用的时候,刚好这个表触发了更新操作,那么查询缓存就会被清空,相当于干了个寂寞。所以MySQL8.0版本中直接将查询缓存删掉了,也就是说从8.0版本开始,执行一条SQL查询语句,不会再走查询缓存这个阶段了。
第三步:解析SQL
执行SQL之前,MySQL会先对SQL语句解析,这个工作交给「解析器」来处理
解析器
第一步:词法分析
关键字 非关键字 关键字 非关键字 select name from
tbl_1
第二步:语法分析
如果我们输入的 SQL 语句语法不对,就会在解析器这个阶段报错。比如,我下面这条查询语句,把 from 写成了 form,这时 MySQL 解析器就会给报错。

第四步:执行SQL
经过解析器后,接着就要进入执行SQL查询语句的流程,每条select查询语句流程主要可以分为下面三个阶段
- prepare阶段 -> 预处理阶段
- optimize阶段 -> 优化阶段
- execute阶段 -> 执行阶段
预处理器
预处理都做了什么事情呢?
- 检查SQL查询语句中的表或者字段是否存在
- 将select * 中的*符号,扩展为表上的所有列
优化器
经过预处理阶段后,还需要为SQL查询语句先制定一个执行计划,这个工作是由「优化器」完成的。
优化器主要负责将SQL查询语句的执行方案确定下来,比如表里面有多个索引的时候,优化器会基于查询成本的考虑,来决定选择使用哪个索引
执行器
经历完优化器后,就确定了执行方案,接下来就真正开始执行语句了 ,这个工作是由「执行器」完成的。在执行的过程中,执行器就会和存储引擎交互了,交互是以记录为单位的。
以下以三种方式描述执行过程
- 主键索引查询
- 全表扫描
- 索引下推
索引下推是MySQL5.6推出的查询优化策略,索引下推能够减少二级索引在查询时的回表操作,提高查询的效率,因为它将Server层部分负责的事情,交给存储引擎层去处理了。
下面以一个例子说明:
- CREATE TABLE `tbl_score` (
- `id` bigint NOT NULL AUTO_INCREMENT,
- `name` varchar(30) NOT NULL comment '名字',
- `age` int NOT NULL comment '年龄',
- `score` int NOT NULL comment '分数',
- PRIMARY KEY (`id`),
- KEY `index_age_score` (`age`,`score`) USING BTREE
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
下面这条查询语句:
select * from tbl_score where age < 18 and score = 80;联合索引当遇到范围查询就会停止匹配,也就是age字段能用到联合索引,但是score字段则无法利用到索引。
无索引下推(5.6版本之前)时,执行器与存储引擎的执行流程会如下:
- Server层首先调用存储引擎的接口定位到满足条件的第一条二级索引记录,也就是定位到age<18的第一条记录;
- 存储引擎根据二级索引的B+树快速定位到这条记录后,获取主键值,然后进行回表操作,将完整的记录返回给Server层;
- Server层在判断该记录的score是否等于80,如果成立则将其发送给客户端;否则跳过该记录;
- 接着,继续向存储引擎索要下一条记录,存储引擎在二级索引定位到记录后,获取主键值,然后回表操作,将完整的记录返回给 Server 层;
- 如此往复,直到存储引擎把表中的所有记录读完。
可以看到,没有索引下推的时候,每查询到一条二级索引记录,都要进行回表操作,然后将记录返回给 Server,接着 Server 再判断该记录的 score 是否等于80。
使用索引下推时,执行器与存储引擎的执行流程:
- Server层首先调用存储引擎的接口定位到满足条件的第一条二级索引记录,也就是定位到age<18的第一条记录;
- 存储引擎定位到二级索引后,先不执行回表操作,而是先判断一下该索引中包含的列(score列)的条件(score 是否等于 80)是否成立。如果条件不成立,则直接跳过该二级索引。如果成立,则执行回表操作,将完成记录返回给 Server 层。
- Server 层在判断其他的查询条件(本次查询没有其他条件)是否成立,如果成立则将其发送给客户端;否则跳过该记录,然后向存储引擎索要下一条记录。
- 如此往复,直到存储引擎把表中的所有记录读完。
可以看到,使用了索引下推后,虽然 score 列无法使用到联合索引,但是因为它包含在联合索引(age,score)里,所以直接在存储引擎过滤出满足 score = 80 的记录后,才去执行回表操作获取整个记录。相比于没有使用索引下推,节省了很多回表操作。
如果发现执行计划里的 Extr 部分显示了 “Using index condition”,说明使用了索引下推。

-
相关阅读:
力扣labuladong一刷day2共7题
基于Django的博客系统之增加手机验证码登录(九)
压力管道的分类
【C++模板编程入门】模板介绍、模板定义、函数模板、类模板、模板的继承
Kali Linux 2022.3部署指南 VirtualBox快速安装及nmap使用说明
认识Modbus通信协议(笔记)
[附源码]JAVA毕业设计高校在线办公系统(系统+LW)
线性回归大结局(岭(Ridge)、 Lasso回归原理、公式推导),你想要的这里都有
【K8S】常用的 Kubernetes(K8S)指令
数据库执行计划与更新统计信息(AI问答)
- 原文地址:https://blog.csdn.net/wh2691259/article/details/139698987