-
MySQL -- 索引
当表中的数据量到达几十万甚至上百万的时候,SQL查询所花费的时间会很长,导致业务超时出错,此 时就需要用索引来加速SQL查询。 由于索引也是需要存储成索引文件的,因此对索引的使用也会涉及磁盘I/O操作。如果索引创建过多, 使用不当,会造成SQL查询时,进行大量无用的磁盘I/O操作,降低了SQL的查询效率,适得其反,因此 掌握良好的索引创建原则非常重要。
1.索引分类
索引是创建在表上的,是对数据库表中一列或者多列的值进行排序的一种结果。索引的核心是提高查询的速度!
物理上(聚集索引&非聚集索引)/逻辑上(...)
索引的优点: 提高查询效率
索引的缺点: 索引并非越多越好,过多的索引会导致CPU使用率居高不下,由于数据的改变,会造成索引文件的改动,过多的磁盘I/O造成CPU负荷太重
1、普通索引:没有任何限制条件,可以给任何类型的字段创建普通索引(创建新表&已创建表,数量是 不限的,一张表的一次sql查询只能用一个索引 where a=1 and b='M')
2、唯一性索引:使用UNIQUE修饰的字段,值不能够重复,主键索引就隶属于唯一性索引
3、主键索引:使用Primary Key修饰的字段会自动创建索引(MyISAM, InnoDB)
4、单列索引:在一个字段上创建索引
5、多列索引:在表的多个字段上创建索引 (uid+cid,多列索引必须使用到第一个列,才能用到多列索 引,否则索引用不上)
6、全文索引:使用FULLTEXT参数可以设置全文索引,只支持CHAR,VARCHAR和TEXT类型的字段 上,常用于数据量较大的字符串类型上,可以提高查询速度(线上项目支持专门的搜索功能,给后台服务 器增加专门的搜索引擎支持快速高校的搜索 elasticsearch 简称es C++开源的搜索引擎 搜狗的 workflow)
索引创建和删除
创建表的时候指定索引字段:
- CREATE TABLE index1(id INT,
- name VARCHAR(20),
- sex ENUM('male', 'female'),
- INDEX(id,name);
在已经创建的表上添加索引:
CREATE [UNIQUE] INDEX 索引名 ON 表名(属性名(length) [ASC | DESC]);删除索引:
DROP INDEX 索引名 ON 表名;1.经常作为where条件过滤的字段考虑添加索引
2.字符串列创建索引时,尽量规定索引的长度,而不能让索引值的长度key_len过长
3.索引字段涉及类型强转、mysql函数调用、表达式计算等,索引就用不上了
create index nameidx on student(name);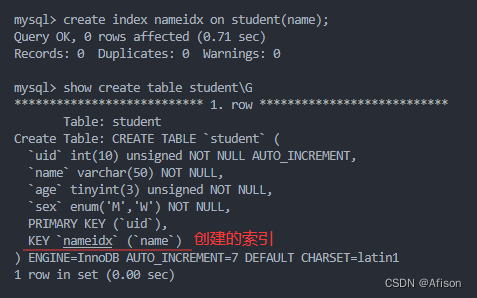

未创建索引时,搜索

创建索引后,搜索

未创建索引时


创建索引

创建索引后查询

索引字段涉及类型强转、mysql函数调用、表达式计算等,索引就用不上了(我们使用SQL时用的是int 1000000,而password是varchar,涉及类型强转)

改为字符串类型‘1000000’不涉及类型强转,速度明显提升
加索引后,只扫描一行


2.索引的执行过程
使用
EXPLAIN命令可以分析 SQL 语句的执行计划,帮助我们理解索引的使用情况和查询效率,从而进行优化。常见的字段包括select_type,table,type,ref,Extra等,理解这些字段的含义对于优化查询性能非常重要。mysql的user权限表示例如下:
- mysql> explain select Host,User from user where Host='%'\G
- *************************** 1. row ***************************
- id: 1
- select_type: SIMPLE
- table: user
- partitions: NULL
- type: ref
- possible_keys: PRIMARY
- key: PRIMARY
- key_len: 180
- ref: const
- rows: 1
- filtered: 100.00
- Extra: Using index
- 1 row in set, 1 warning (0.00 sec)
可以看到使用了主键索引,共扫描1行,Using index表示直接从索引树上查询到结果,不需要回表。
- mysql> explain select Host,User from user where User='root'\G
- *************************** 1. row ***************************
- id: 1
- select_type: SIMPLE
- table: user
- partitions: NULL
- type: index
- possible_keys: NULL
- key: PRIMARY
- key_len: 276
- ref: NULL
- rows: 4
- filtered: 25.00
- Extra: Using where; Using index
- 1 row in set, 1 warning (0.00 sec)
- mysql> explain select * from user where User='root'\G
- *************************** 1. row ***************************
- id: 1
- select_type: SIMPLE
- table: user
- partitions: NULL
- type: ALL
- possible_keys: NULL
- key: NULL
- key_len: NULL
- ref: NULL
- rows: 4
- filtered: 25.00
- Extra: Using where
- 1 row in set, 1 warning
explain结果字段分析
- select_type
simple:表示不需要union操作或者不包含子查询的简单select语句。有连接查询时,外层的查询 为simple且只有一个。
primary:一个需要union操作或者含有子查询的select,位于最外层的单位查询的select_type即 为primary且只有一个。
union:union连接的两个select查询,除了第一个表外,第二个以后的表的select_type都是 union。
union result:包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id 字段为null。
- table
显示查询的表名;
如果不涉及对数据库操作,这里显示null;
如果显示为尖括号就表示这是个临时表,后边的N就是执行计划中的id,表示结果来自于这个查询 产生的;
如果是尖括号括起来也是一个临时表,表示这个结果来自于union查询的id为M,N 的结果集;
- type
const:使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type就是 const。
ref:常见于辅助索引的等值查找,或者多列主键、唯一索引中,使用第一个列之外的列作为等值 查找会出现;返回数据不唯一的等值查找也会出现。
range:索引范围扫描,常见于使用、is null、between、in、like等运算符的查询中。
index:索引全表扫描,把索引从头到尾扫一遍;常见于使用索引列就可以处理不需要读取数据文 件的查询,可以使用索引排序或者分组的查询。
all:全表扫描数据文件,然后在server层进行过滤返回符合要求的记录。
- ref
如果使用常数等值查询,这里显示const;
如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段;
- Extra
using filesort:排序时无法用到索引,常见于order by和group by语句中。
using index:查询时不需要回表查询,直接通过索引就可以获取查询的数据。
3.索引的底层实现原理
索引是数据库中用于快速查找数据的一种数据结构,类似于书的目录,数据库索引是存储在磁盘上的,当数据量大时,就不能把整个索引全部加载到内存了,只 能逐一加载每一个磁盘块(对应索引树的节点),索引树越低,越“矮胖”,磁盘IO次数就少。
MySQL支持两种索引,一种的B-树索引,一种是哈希索引,大家知道,B-树和哈希表在数据查询时的效 率是非常高的。 这里我们主要讨论一下MySQL InnoDB存储引擎,基于B-树(但实际上MySQL采用的是B+树结构)的 索引结构。 B-树是一种m阶平衡树,叶子节点都在同一层,由于每一个节点存储的数据量比较大,索引整个B-树的 层数是非常低的,基本上不超过三层。 由于磁盘的读取也是按block块操作的(内存是按page页面操作的),因此B-树的节点大小一般设置为 和磁盘块大小一致,这样一个B-树节点,就可以通过一次磁盘I/O把一个磁盘块的数据全部存储下来, 所以当使用B-树存储索引的时候,磁盘I/O的操作次数是最少的(MySQL的读写效率,主要集中在磁盘 I/O上)。
1. B-Tree 索引
B-Tree(Balance Tree)索引是最常见的索引类型,尤其是在关系型数据库中(如 MySQL)。
特点:
- 平衡树结构:B-Tree 是一种平衡树,所有叶子节点在同一层,确保查找、插入和删除操作的时间复杂度为 O(log n)。
- 节点存储:每个节点存储多个键值,并包含指向子节点的指针,节点中的键值按顺序排列。
- 范围查询:B-Tree 非常适合范围查询(如 BETWEEN 和 >= 操作)。
工作原理:
- 查找:从根节点开始,比较查找值与节点中的键值,选择合适的子节点继续查找,直到叶子节点。
- 插入:找到插入位置,插入键值,如果节点满了则进行分裂,保持树的平衡。
- 删除:删除键值后,可能需要合并节点或借用邻近节点的键值,保持树的平衡。
2. B+Tree 索引
B+Tree 是 B-Tree 的一种变体,广泛用于数据库和文件系统。
特点:
- 所有值存储在叶子节点:内部节点只存储键值和指向子节点的指针,所有实际数据存储在叶子节点中。
- 叶子节点链表:叶子节点通过链表连接,方便范围查询和顺序访问。
工作原理:
- 查找:与 B-Tree 类似,但最终数据在叶子节点中找到。
- 插入和删除:与 B-Tree 类似,通过分裂和合并节点保持树的平衡。
3. Hash 索引
Hash 索引基于哈希表实现,适用于等值查询。
特点:
- 哈希函数:使用哈希函数将键值映射到哈希表的桶中。
- 快速查找:查找时间复杂度为 O(1)。
- 不支持范围查询:因为哈希函数的特性,无法进行范围查询。
工作原理:
- 查找:将键值通过哈希函数转换为哈希值,然后在哈希表中找到对应的桶。
- 插入:将键值插入到对应的桶中,如果发生哈希冲突,则通过链地址法(链表)或开放地址法解决冲突。
- 删除:找到对应的桶并删除键值,处理冲突方式相同。
4. R-Tree 索引
R-Tree 索引主要用于空间数据,如地理信息系统中的多维数据。
特点:
- 节点存储矩形:节点存储包含空间对象的最小边界矩形(MBR)。
- 适用于多维数据:支持多维数据的快速查找和范围查询。
工作原理:
- 查找:从根节点开始,检查查询范围是否与节点的 MBR 重叠,选择合适的子节点继续查找,直到叶子节点。
- 插入:找到合适的叶子节点插入,如果叶子节点满了则进行分裂。
- 删除:找到对应的叶子节点删除数据,可能需要合并节点,保持树的平衡。
-
相关阅读:
Vue(6)
Atcoder TUPC 2023(東北大学プログラミングコンテスト 2023)P. Sub Brackets(dinic 二分图最大独立集)
Spark Streaming 整合 Flume
hive3升级
【数据结构】链表LinkedList
分布式复制系统设计-总结
Linux 开源数据库Mysql-10-mysql集群一主一从GTID
【Spring的自动装配】
测评补单:Temu卖家的市场攻略,轻松吸引更多流量和转化!
C++ - STL 使用红黑树封装map set
- 原文地址:https://blog.csdn.net/Afison/article/details/139436126