-
计算机毕业设计hadoop+spark+hive知识图谱音乐推荐系统 音乐数据分析可视化大屏 音乐爬虫 LSTM情感分析 大数据毕设 深度学习 机器学习
青岛理工大学(临沂)机械与电子工程系
毕业设计外文翻译
独立于语言的个性化音乐
推荐系统
Personalized Language-Independent Music Recommendation System
设计题目:基于python的音乐推荐系统的分析可视化设计
专业班级: 计算机科学与技术21级3班
学生姓名: 纪光辉
学生学号: 202113160638
指导教师: 刘庆海
完成日期: 2023年3月17日
独立于语言的个性化音乐推荐系统拉迪卡·N
计算机科学系研究生学者
工程专业
战国策工程学院
帕拉卡德,喀拉拉邦
电子邮件:XXXXXXX
赛亚姆·桑卡尔
计算机科学系助理教授
工程专业
战国策工程学院
帕拉卡德, 喀拉拉邦
电子邮件: syam.sankar8@gmail.com
摘要 — 社交媒体是用户展示的地方 他们自己并分享所有类型的信息、想法和 与世界的经验。近年来,情绪分析已经 被多家互联网服务探索推荐内容 根据人类的情感,通过社交网络。社交网络上的许多用户在写句子 多种语言。本文介绍与语言无关 音乐推荐系统中的情感分析。这个系统 根据当前的情绪向用户推荐音乐那个人的状态。其中当前情绪状态通过测量调整后的情绪强度来计算人 值,它是情绪强度值与 修正系数。此校正系数基于用户配置文件信息,并用于调整最终情绪强度值。
传统分类器是特定于语言的,需要很多 工作应用于不同的语言。建议的系统使用 语言的监督情绪分类方法 独立情绪强度计算。我们训练朴素湾 对我们的数据进行分类,并在2中的1000多个帖子上对其进行评估语言,英语和马拉雅拉姆语。
受监督的情绪具有校正因子的分类器可以提高性能拟议的语言独立音乐推荐系统。
关键词 — 社交网络,情绪分析,更正因素,建议
一、引言
互联网改变了我们的生活。如今很常见 让人们通过以下方式表达他们的情绪和意见 社交网络和微博。社交媒体使我们能够把世界掌握在我们手中。推特是最大的推特之一 互联网上的微博服务[8]。微博是 人们用来分享各种短信的短信 信息与世界。在推特上,这些微博是被称为“推
文”,其中超过4亿条被发布日。在这种情况下,关于情绪强度的研究有 开始出现。情感分析是一种自然语言技术 处理和文本分析,可应用于许多 推荐系统。了解情绪强度 一句话可以帮助更多地了解一个人表达自己对事件、产品或内容的看法。然而,它在推荐系统中的使用仍然是一个
挑战,因为人们用不同的方式表达自己的感受方式,这使得很难创建可靠的基于情绪分析的建议[2]。
在这里,情绪分析开始被探索
推荐特定歌曲的音乐推荐系统取决于人当前的情绪状态,因为歌曲完全与当下的情绪和感受有关这个人。人目前的情绪状态是通过收集用户在社交网络上的帖子来计算。
人们在一天中的某些时间使用社交网络了解他们的行为和习惯可能有助于几种应用[8],[9]。因此,记录很重要。
所有这些数据都在日志中。通过实现日志,可以为定制时期开发推荐系统的时间。例如,一个人通常阅读财经新闻周一和周四上午 8 点至上午 9 点,倾向于阅读周日娱乐新闻。
有大量的研究有待发现从文本数据中自动提取情绪的方法。最研究仅在一种语言的推文上进行。然而,Twitter是一个国际流行的社交网络服务和大部分推文都是多种语言的。
因此,仅分析一种语言的推文仅涵盖可用内容的一部分。 分类方法不限于只分析一种语言,就能收集很多东西来自多个推文的更多情绪信息语言。在本文中,我们研究了语言独立性情绪分类方法。我们训练分类器来标记推文的情绪极性,对于这个阶段需要原始用于训练分类器的该语言的推文。
我们在两个不同的推文上训练分类器语言:英语和马拉雅拉姆语。出于我们收集的目的以这两种语言发送的数千条人工注释的推文并假设任何一条推文只包含一种情绪一时间。要个性化此推荐系统,请正确使用因子,此校正因子完全取决于用户的个人资料信息。
本文对工作的贡献程度[1],它提出了个人语言独立音乐推荐使用基于语料库的情感分析的系统,具有 基于用户个人资料信息的校正系数。










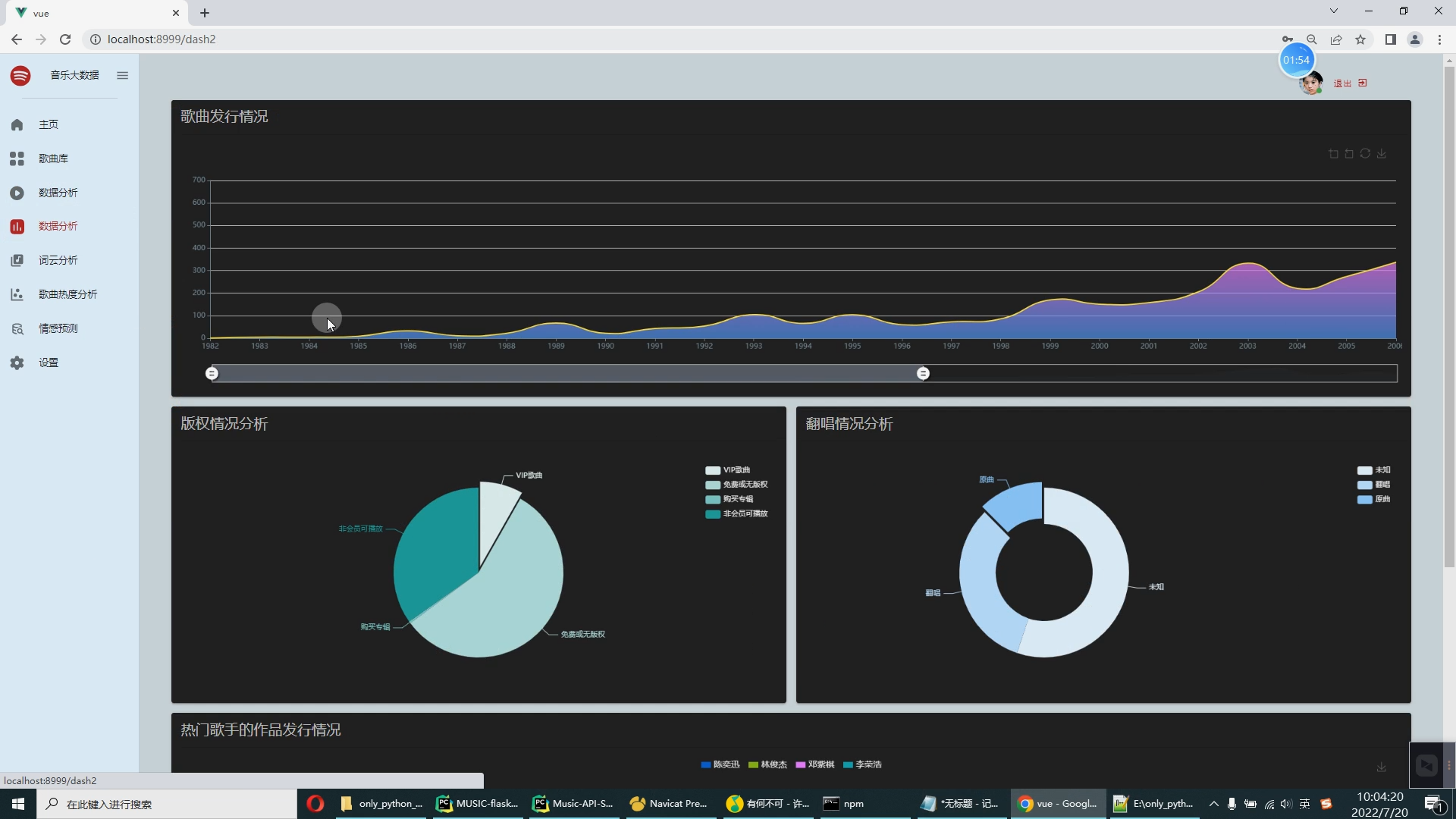


核心算法代码分享如下:
- from flask import Flask, render_template, request, redirect, url_for
- import json
- from flask_mysqldb import MySQL
- from flask import Flask, send_from_directory,render_template, request, redirect, url_for, jsonify
- import csv
- import os
- import pymysql
- # 创建应用对象
- app = Flask(__name__)
- app.config['MYSQL_HOST'] = 'bigdata'
- app.config['MYSQL_USER'] = 'root'
- app.config['MYSQL_PASSWORD'] = '123456'
- app.config['MYSQL_DB'] = 'hive_chinawutong'
- mysql = MySQL(app) # this is the instantiation
- @app.route('/tables01')
- def tables01():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT replace(REPLACE(REPLACE(from_province, '区', ''), '省', ''),'市','') from_province,num FROM table01''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['from_province','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
- @app.route('/tables02')
- def tables02():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT pub_time,num,LENGTH(pub_time) len_time FROM table02 ORDER BY len_time desc ''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['pub_time','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
- @app.route('/tables03')
- def tables03():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table03 order by rztime asc''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['rztime','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
- @app.route('/tables04')
- def tables04():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table04''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['yslx','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
- @app.route("/getmapcountryshowdata")
- def getmapcountryshowdata():
- filepath = r"D:\\wuliu_hadoop_spark_spider2025\\echarts\\data\\maps\\china.json"
- with open(filepath, "r", encoding='utf-8') as f:
- data = json.load(f)
- return json.dumps(data, ensure_ascii=False)
- @app.route('/tables05')
- def tables05():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table05 order by num asc''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['hwlx','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
- @app.route('/tables06')
- def tables06():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table06''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['weight_union','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
- @app.route('/tables07')
- def tables07():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table07 order by num asc''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['recieve_province','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
- @app.route('/tables08')
- def tables08():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table08''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['end_time','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
- @app.route('/tables09')
- def tables09():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table09''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['wlmc','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
- @app.route('/data',methods=['GET'])
- def data():
- limit = int(request.args['limit'])
- page = int(request.args['page'])
- page = (page-1)*limit
- conn = pymysql.connect(host='bigdata', user='root', password='123456', port=3306, db='hive_chinawutong',
- charset='utf8mb4')
- cursor = conn.cursor()
- if (len(request.args) == 2):
- cursor.execute("select count(*) from ods_chinawutong");
- count = cursor.fetchall()
- cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
- cursor.execute("select * from ods_chinawutong limit "+str(page)+","+str(limit));
- data_dict = []
- result = cursor.fetchall()
- for field in result:
- data_dict.append(field)
- else:
- weight_union = str(request.args['weight_union'])
- wlmc = str(request.args['wlmc']).lower()
- if(weight_union=='不限'):
- cursor.execute("select count(*) from ods_chinawutong where wlmc like '%"+wlmc+"%'");
- count = cursor.fetchall()
- cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
- cursor.execute("select * from ods_chinawutong where wlmc like '%"+wlmc+"%' limit " + str(page) + "," + str(limit));
- data_dict = []
- result = cursor.fetchall()
- for field in result:
- data_dict.append(field)
- else:
- cursor.execute("select count(*) from ods_chinawutong where wlmc like '%"+wlmc+"%' and weight_union like '%"+weight_union+"%'");
- count = cursor.fetchall()
- cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
- cursor.execute("select * from ods_chinawutong where wlmc like '%"+wlmc+"%' and weight_union like '%"+weight_union+"%' limit " + str(page) + "," + str(limit));
- data_dict = []
- result = cursor.fetchall()
- for field in result:
- data_dict.append(field)
- table_result = {"code": 0, "msg": None, "count": count[0], "data": data_dict}
- cursor.close()
- conn.close()
- return jsonify(table_result)
- if __name__ == "__main__":
- app.run(debug=False)
-
相关阅读:
Roblox 不但不支持 Linux,还屏蔽了 Wine
网络技术在学校是学习网络协议吗
四周(28天)的个人开发总结(技巧)
[附源码]java毕业设计基于web的健康信息管理系统
动态链接库(扩展)--实际开发时的注意事项
Bigemap添加自定义地图,第三方地图
每天5分钟快速玩转机器学习算法:支持向量机SVM的优势和缺点
STM32F407ZGT6移植AD7606
chatGPT底层原理是什么,为什么chatGPT效果这么好?三万字长文深度剖析-中
【CentOS7】基于python2,3安装docker-compose
- 原文地址:https://blog.csdn.net/spark2022/article/details/139232989