-
JVM之【GC-垃圾清除算法】
Java虚拟机(JVM)中的垃圾收集算法主要分为以下几种:
- 标记-清除算法(Mark-Sweep)
- 复制算法(Copying)
- 标记-整理算法(Mark-Compact)
- 分代收集算法(Generational Collecting)
- G1垃圾收集器(Garbage-First)
- ZGC(Z Garbage Collector)
- Shenandoah垃圾收集器
1. 标记-清除算法(Mark-Sweep)
原理:
- 标记阶段:从根对象开始,遍历整个对象图,标记所有被引用的对象。
- 清除阶段:遍历整个堆,清除未被标记的对象,释放其内存。
优点:
- 直观,简单,适用于任何对象图。
缺点:
- 内存碎片化严重,因为清除阶段并不移动对象,导致堆中可能有大量不连续的可用空间,产生内存碎片。
- 标记和清除阶段都需要扫描整个堆,效率较低。
- GC的时候需要停止整个应用程序,用户体验不好

2. 复制算法(Copying)
原理:
- 将堆分为两个等大的区域,每次只使用其中一个。当活动对象达到一定比例时,将活动对象复制到另一个区域,然后清空当前区域。
- 复制过程中保留活动对象,并保持对象的相对位置不变。
优点:
- 没有内存碎片问题,因为每次都会在一个新的区域中重新排列对象。
- 分配速度快,只需分配指针移动。
缺点:
- 需要两倍的内存空间,因为要维持两个区域。
- 对于存活率高的对象,复制成本高。
- 只适用于存活对象少的情况/频繁消亡的情况(非常适合新生代)
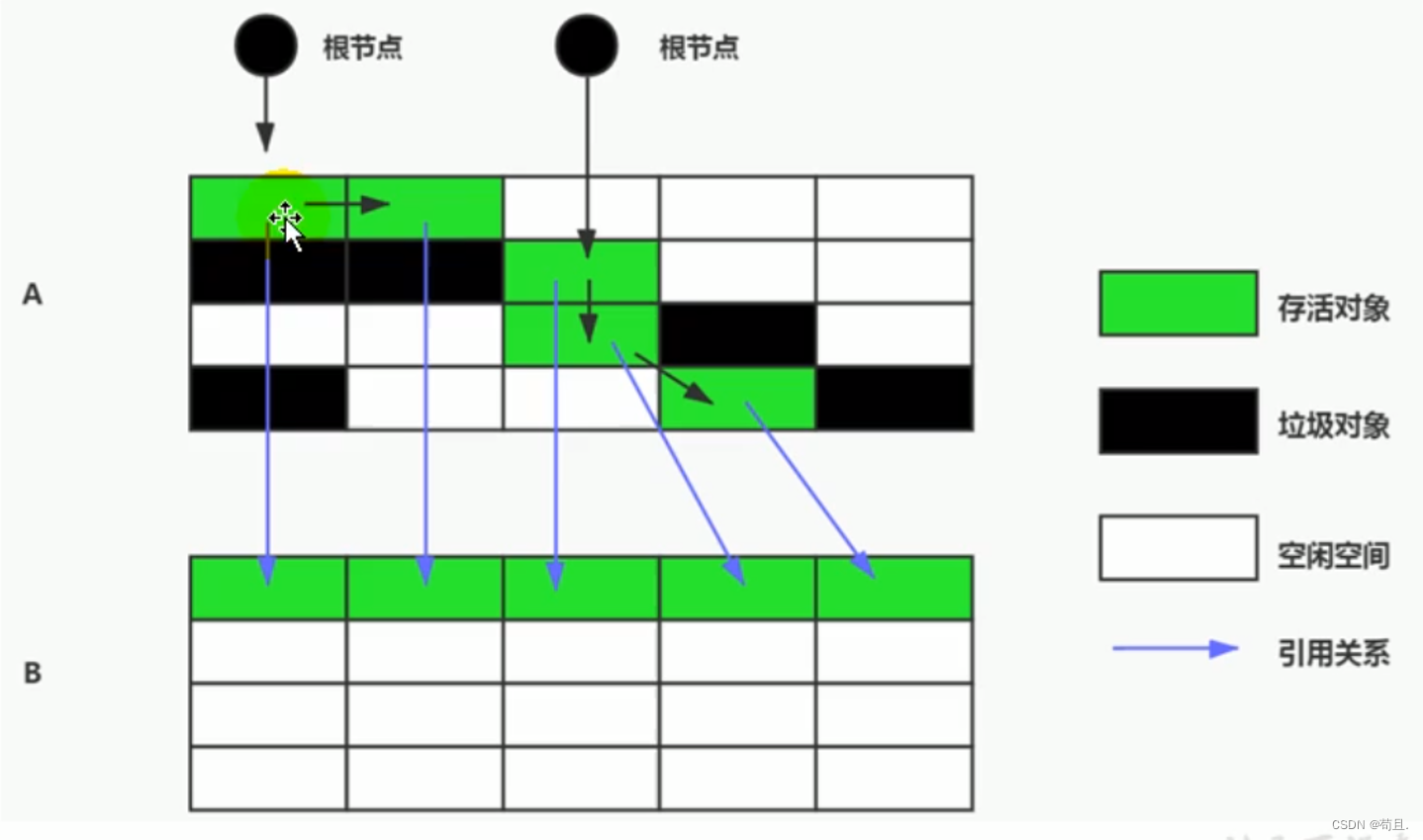
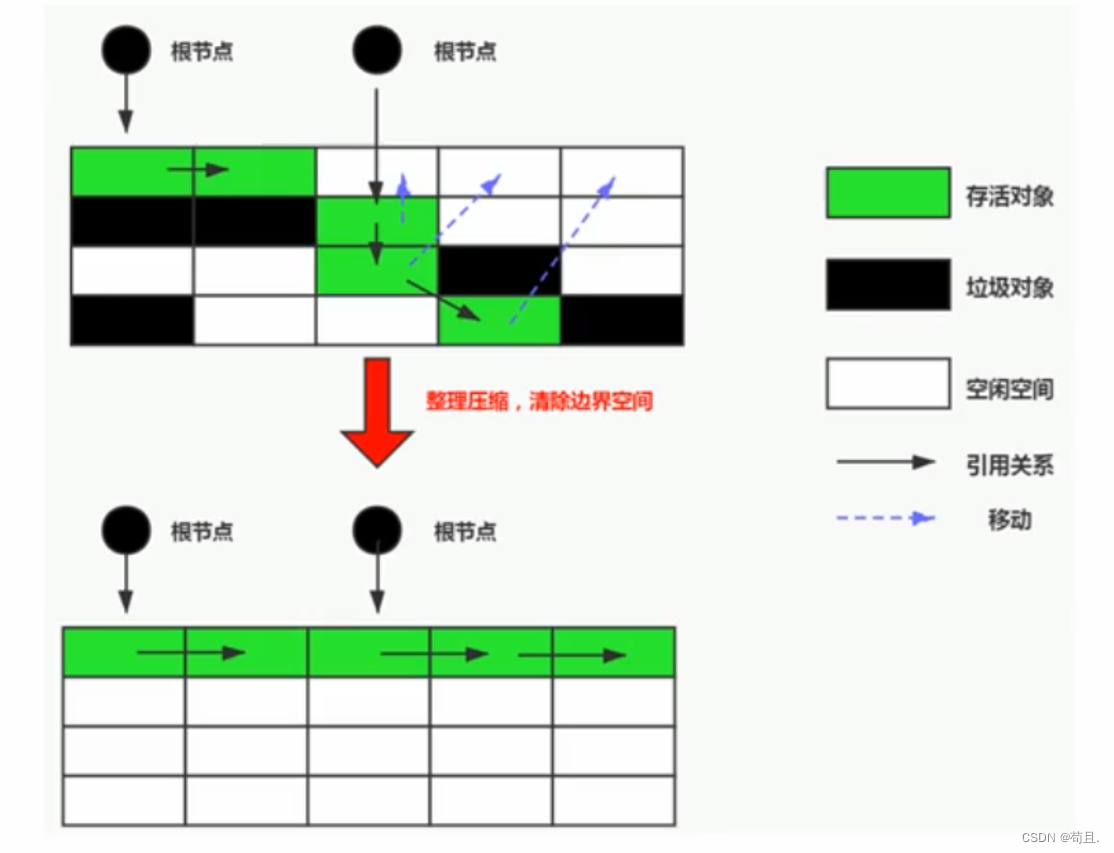
3. 标记-整理算法(Mark-Compact)
原理:
- 标记阶段:与标记-清除算法相同。
- 整理阶段:将所有存活的对象压缩到堆的一端,保持空间的连续性,然后清理边界以外的内存。
优点:
- 消除内存碎片问题,因为对象都被压缩到一端,剩余空间连续。
- 在整理阶段减少了内存分配的复杂度,消除了复制算法翻倍消耗内存的缺点。
缺点:
- 整理阶段涉及大量对象移动,可能会导致较高的性能开销。
- 效率其实不如复制算法,在对象移动后,其他地方引用了该对象的话,还需要同步修改对象的引用地址
前面所有这些算法中,并没有一种算法可以完全替代其他算法,它们都具有自己独特的优势和特点。分代收集算法应运而生。
分代收集算法:是基于这样一个事实:不同的对象的生命周期是不一样的。因此,不同生命周期的对象可以采取不同的收集方式,以便提高回收效率。一般是把Java堆分为新生代和老年代,这样就可以根据各个年代的特点使用不同的回收算法,以提高垃圾回收的效率。
在Java程序运行的过程中,会产生大量的对象,其中有些对象是与业务信息相关,比如Http请求中的Session对象、线程、Socket连接,这类对象跟业务直接挂钩,因此生命周期比较长。但是还有一些对象,主要是程序运行过程中生成的临时变量,这些对象生命周期会比较短,比如:string对象,由于其不变类的特性,系统会产生大量的这些对象,有些对象甚至只用一次即可回收。
4. 分代收集算法(Generational Collecting)
详情请移步堆篇章
JVM之【运行时数据区2——堆】
原理:- 将堆划分为不同的代(一般为年轻代和老年代)。
- 年轻代使用复制算法,老年代使用标记-清除或标记-整理算法。
- 依据“弱分代假说”,大多数对象很快就会死亡。
优点:
- 优化了垃圾收集的效率,因为年轻代对象存活率低,收集速度快。
- 减少了老年代垃圾收集的频率。
缺点:
- 需要复杂的调优工作,以确定代大小和收集策略。
- 在年轻代和老年代之间的对象移动可能会产生额外的开销。
5. 分区收集算法/G1垃圾收集器(Garbage-First)
- 一般来说,在相同条件下,堆空间越大,一次Gc时所需要的时间就越长,有关GC产生的停顿也越长。为了更好地控制GC产生的停顿时间,将一块大的内存区域分割成多个小块,根据目标的停顿时间,每次合理地回收若干个小区间,而不是整个堆空间,从而减少一次GC所产生的停顿。
- 分代算法将按照对象的生命周期长短划分成两个部分,分区算法将整个堆空间划分成连续的不同小区间。
- 每一个小区间都独立使用,独立回收。这种算法的好处是可以控制一次回收多少个小区间。
原理:
- 将堆分为多个区域(regions),分别处理,优先回收垃圾最多的区域。
- 结合了标记-清除和标记-整理算法,适用于大堆的垃圾收集。
优点:
- 低暂停时间,适合大堆应用。
- 可以并行和并发进行垃圾收集,提升性能。
缺点:
- 相对较复杂的实现和调优。
- 在某些情况下,性能可能不如其他收集器。
6.Shenandoah垃圾收集器
原理:
- 以并发标记和并发整理为基础,最小化垃圾收集对应用线程的影响。
- 使用并发压缩技术减少停顿时间。
优点:
- 低停顿时间,适合延迟敏感应用。
- 高效处理大堆内存。
缺点:
- 复杂的实现和调优。
- 性能可能受限于特定的硬件和JVM版本。
总结
不同垃圾收集算法和垃圾收集器各有优缺点,应根据具体应用需求和硬件环境选择合适的垃圾收集策略。标记-清除和复制算法比较基础,适用于小型或简单应用;分代收集算法适用于大多数常规应用;G1、Shenandoah更适合大内存、低延迟的高性能应用。
-
相关阅读:
Vue中的数据分页与分页组件设计
排序算法模板
【考研数学】五. 二重积分
5.11-5.12Union-Find算法详解
【算法每日一练]-图论(保姆级教程 篇5(LCA,最短路,分层图)) #LCA #最短路计数 #社交网络 #飞行路线 # 第二短路
intellij idea的快速配置详细使用
我在简历上写了这个,超级加分!
Playwright官方文档要点记录(java)
windows aseprite编译指南(白嫖)
漏电断路器
- 原文地址:https://blog.csdn.net/qq_38096989/article/details/139423945